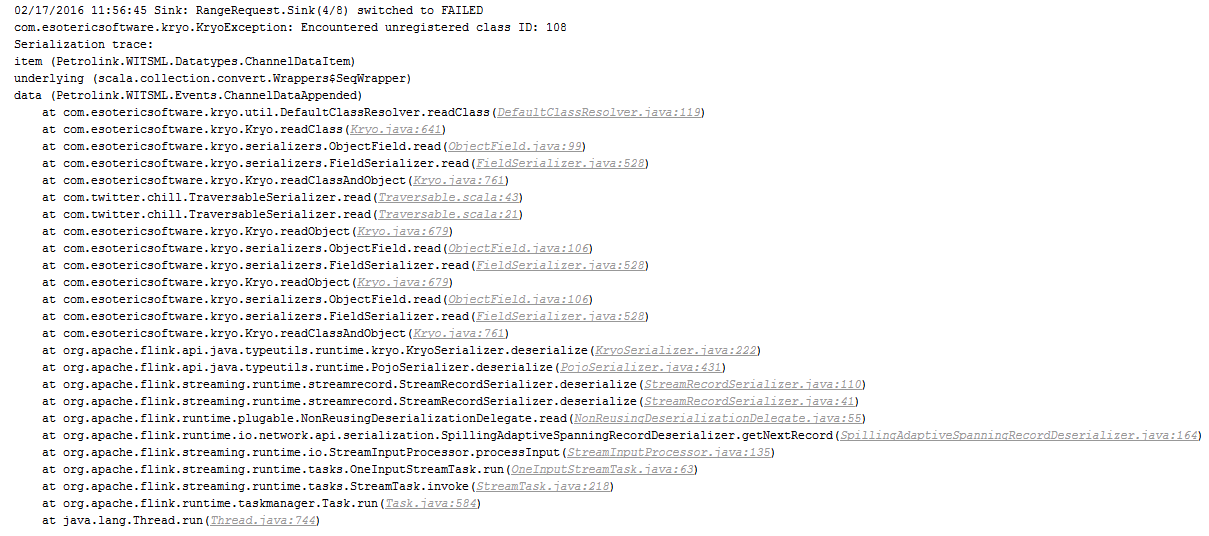
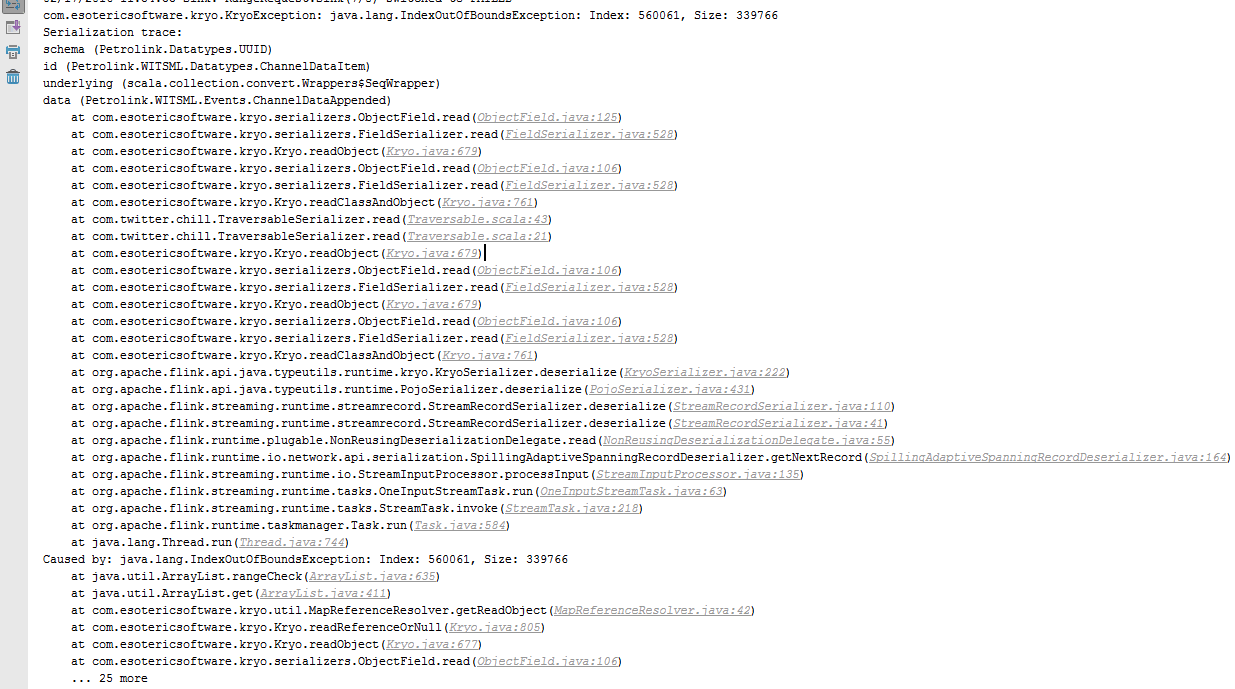
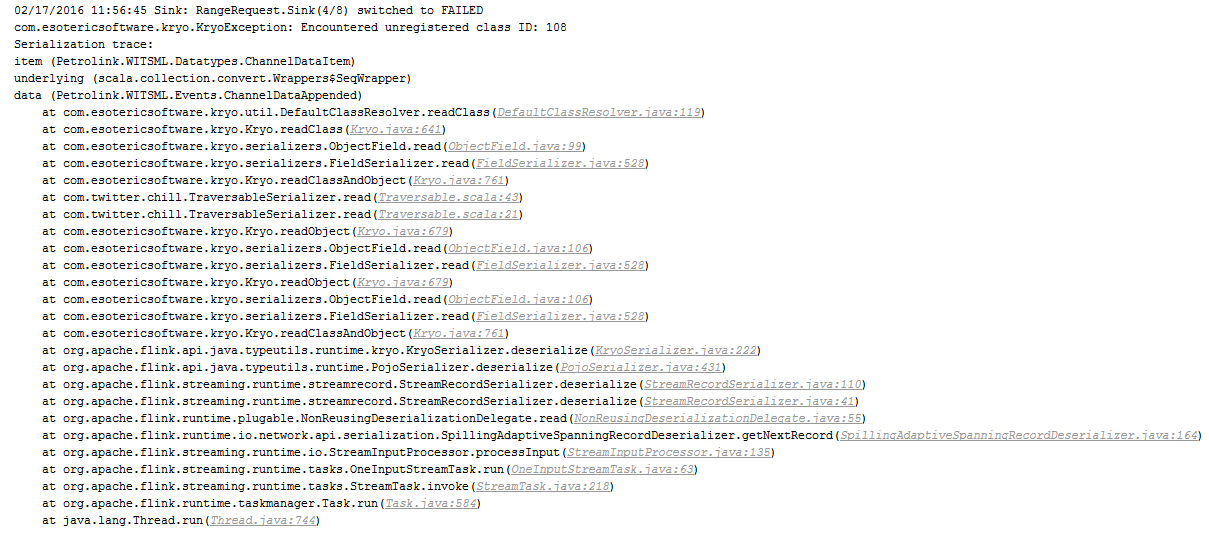
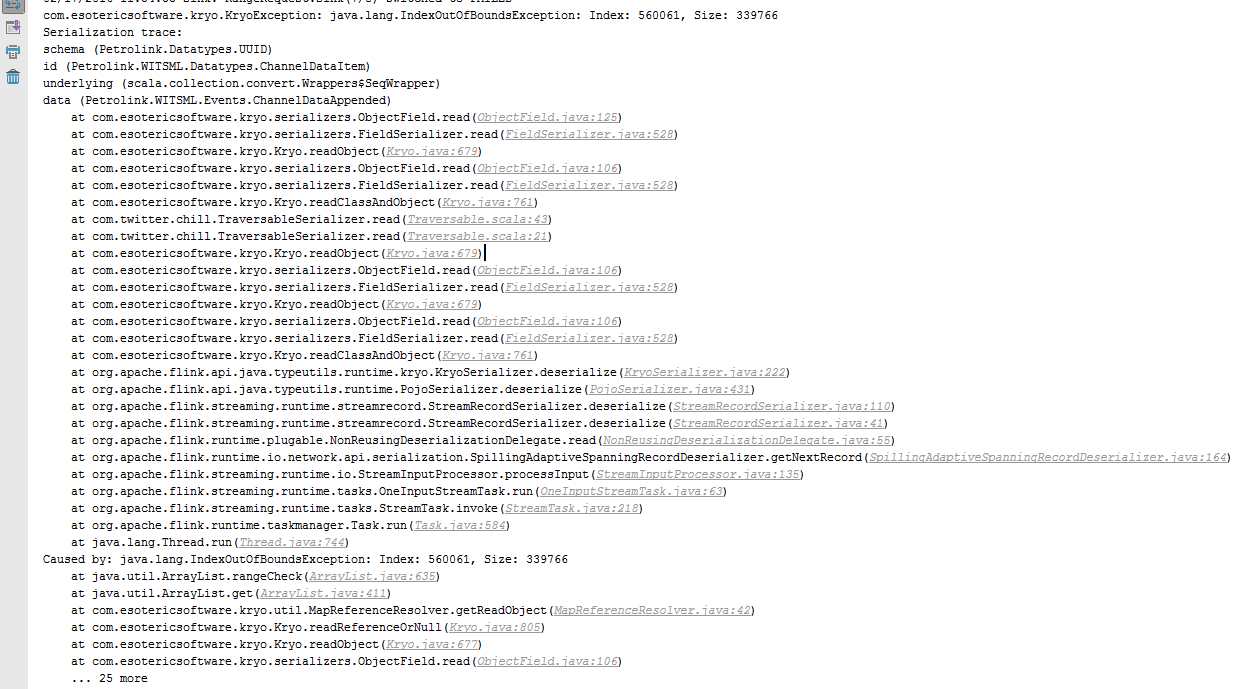
Hi Welly!
There are 3 possible reasons for that error that I can think of:
1) A bug in Kryo, or in one of the serializers used by Kryo
2) Wrong Kryo registration in Flink
3) A corruption in the network stream.
If it is a corruption in the network stream, I think we'd see a different problem earlier, so let's check first the other cases.
Can you try the following: For every data type that you use in the program (like "Petrolink.WITSML.Datatypes.ChannelDataItem"), can you explicitly register the type?
Call "env.registerType(Petrolink.WITSML.Datatypes.ChannelDataItem.class)";
Let's see if that solves the problem. Could you also by any chance try the first release candidate for the upcoming 1.0 release? It should have at least the reference tracing disabled, which throws one of the errors.
If we cannot get to the bottom of this via mail, is it possible by any chance that you share the data with us to debug this (privately,
[hidden email]) ?
Greetings,
Stephan