Imbalanced workload between workers

12

12
Imbalanced workload between workers

|
Hi guys,
Currently I am running a job in the GCloud in a configuration with 4 task managers that each have 4 CPUs (for a total parallelism of 16). However, I noticed my job is running much slower than expected and after some more investigation I found that one of the workers is doing a majority of the work (its CPU load was at 100% while the others were almost idle). My job execution plan can be found here: http://i.imgur.com/fHKhVFf.png The input is split into multiple files so loading the data is properly distributed over the workers. I am wondering if you can provide me with some tips on how to figure out what is going wrong here:
Thanks and kind regards, Pieter |
Re: Imbalanced workload between workers
|
|
Could it be that your data is skewed? This could lead to different loads on different task managers. With the latest Flink version, the web interface should show you how many bytes each operator has written and received. There you could see if one operator receives more elements than the others. Cheers, Till On Wed, Jan 27, 2016 at 1:35 PM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Cheers for the quick reply Till. That would be very useful information to have! I'll upgrade my project to Flink 0.10.1 tongiht and let you know if I can find out if theres a skew in the data :-) - Pieter 2016-01-27 13:49 GMT+01:00 Till Rohrmann <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Hi Till, i've upgraded to Flink 0.10.1 and ran the job again without any changes to the code to see the bytes input and output of the operators and for the different workers.To my surprise it is very well balanced between all workers and because of this the job completed much faster. Are there any changes/fixes between Flink 0.9.1 and 0.10.1 that could cause this to be better for me now? Thanks, Pieter 2016-01-27 14:10 GMT+01:00 Pieter Hameete <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Hi Pieter! Interesting, but good :-) I don't think we did much on the hash functions since 0.9.1. I am a bit surprised that it made such a difference. Well, as long as it improves with the newer version :-) Greetings, Stephan On Wed, Jan 27, 2016 at 9:42 PM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
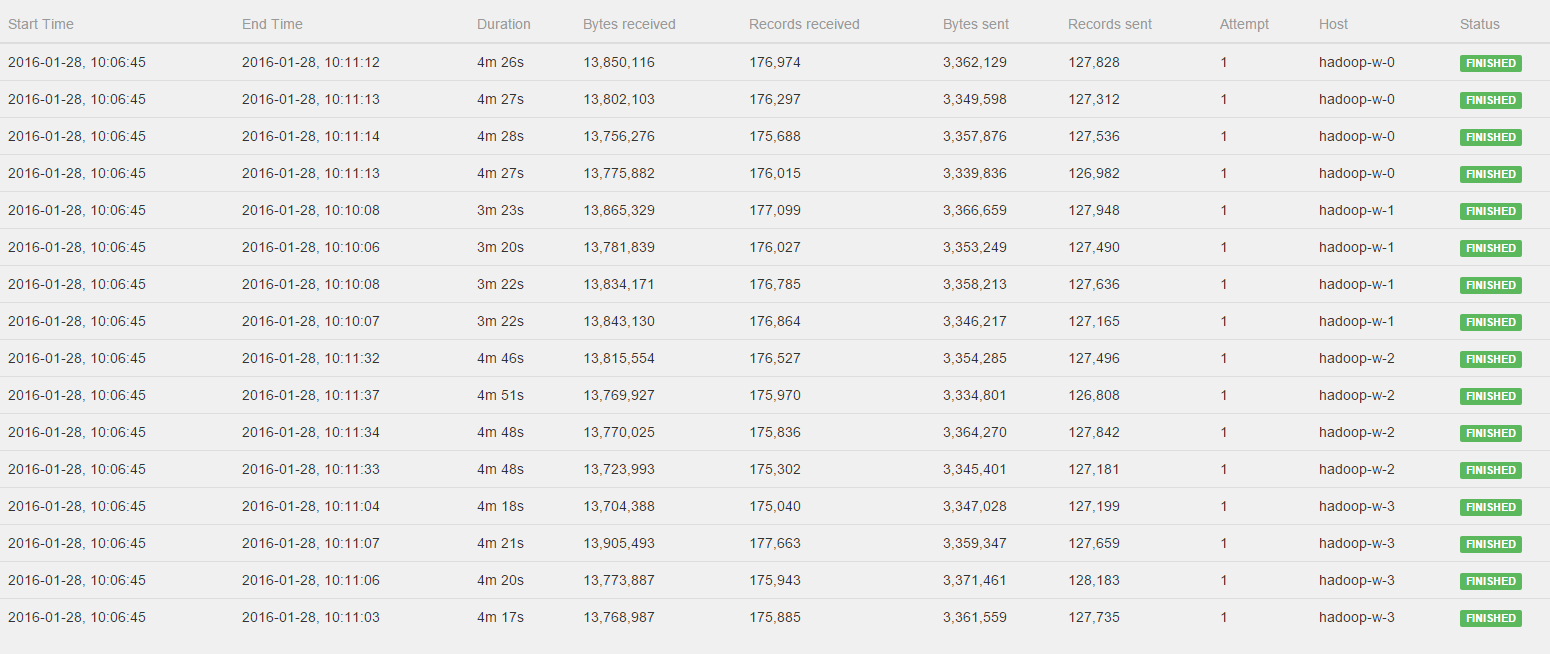
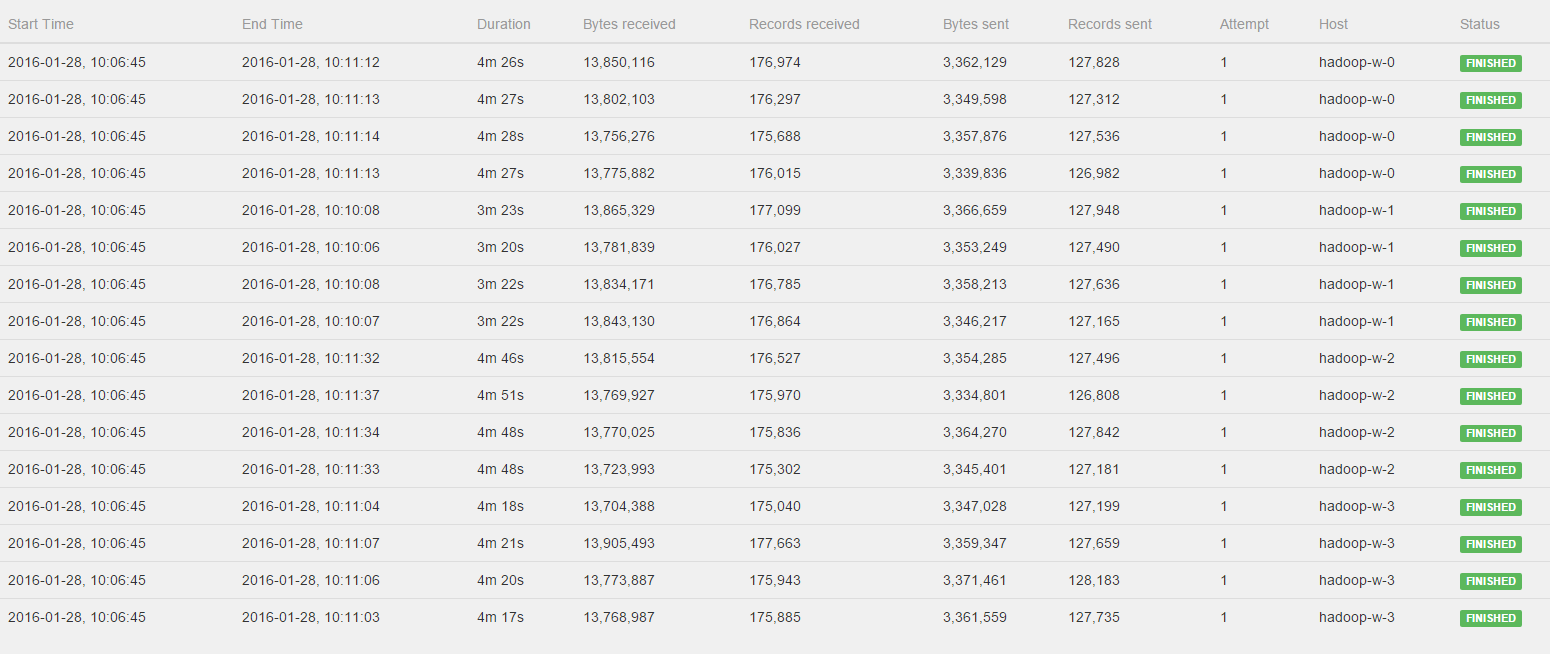
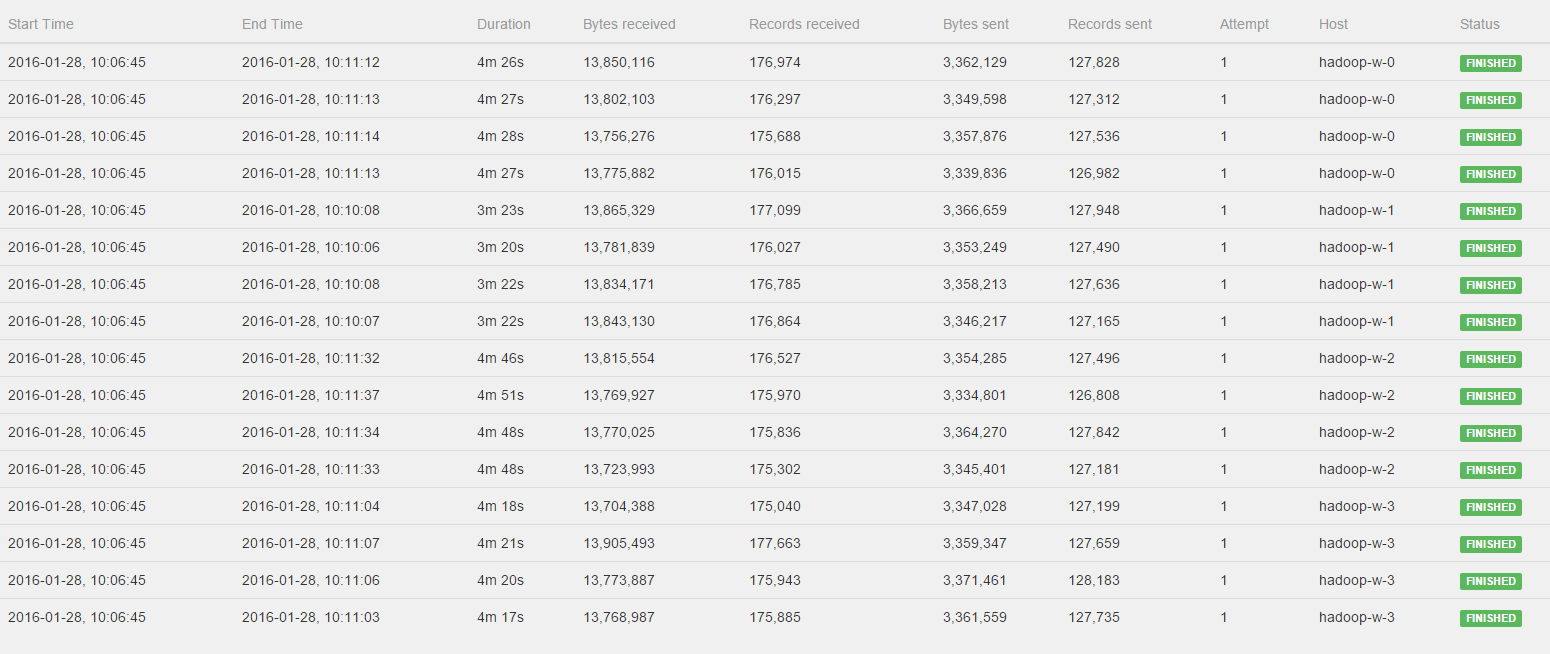
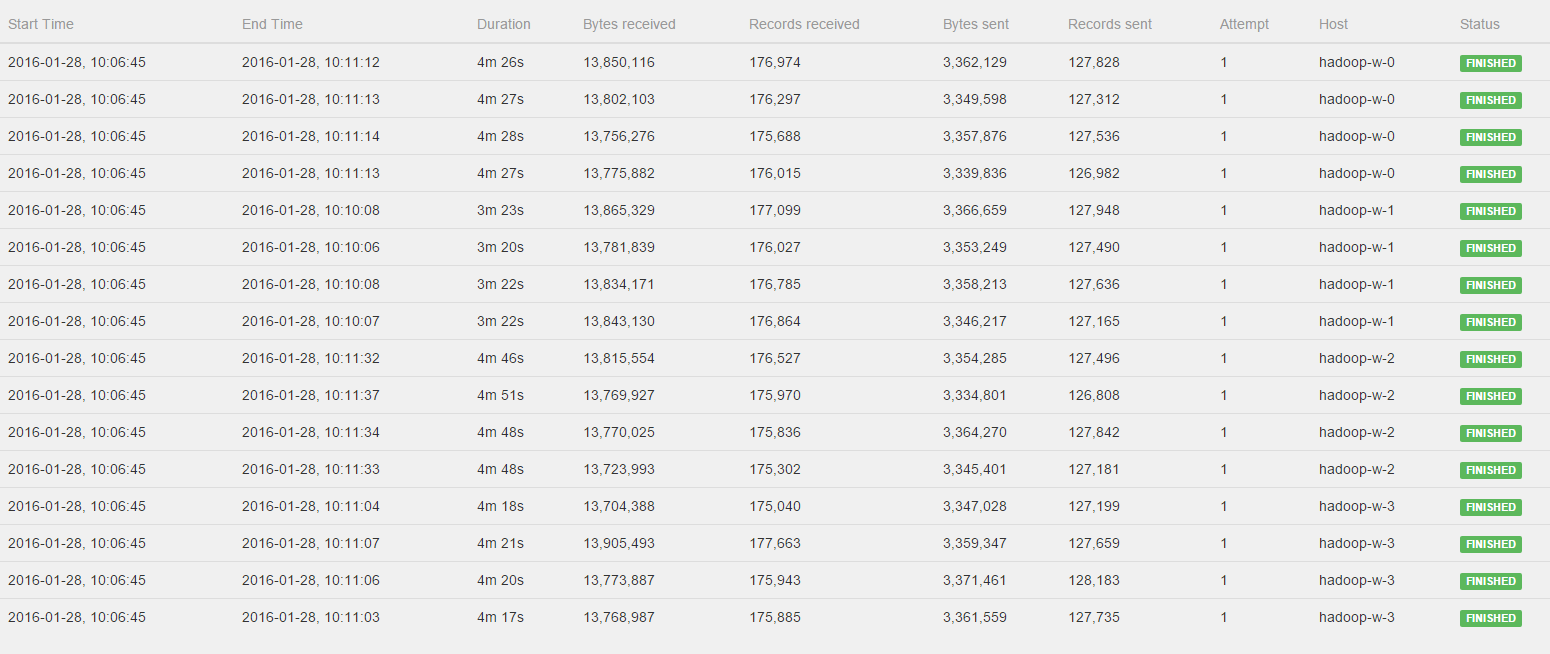
Hi Stephen, Till, I've watched the Job again and please see the log of the CoGroup operator: 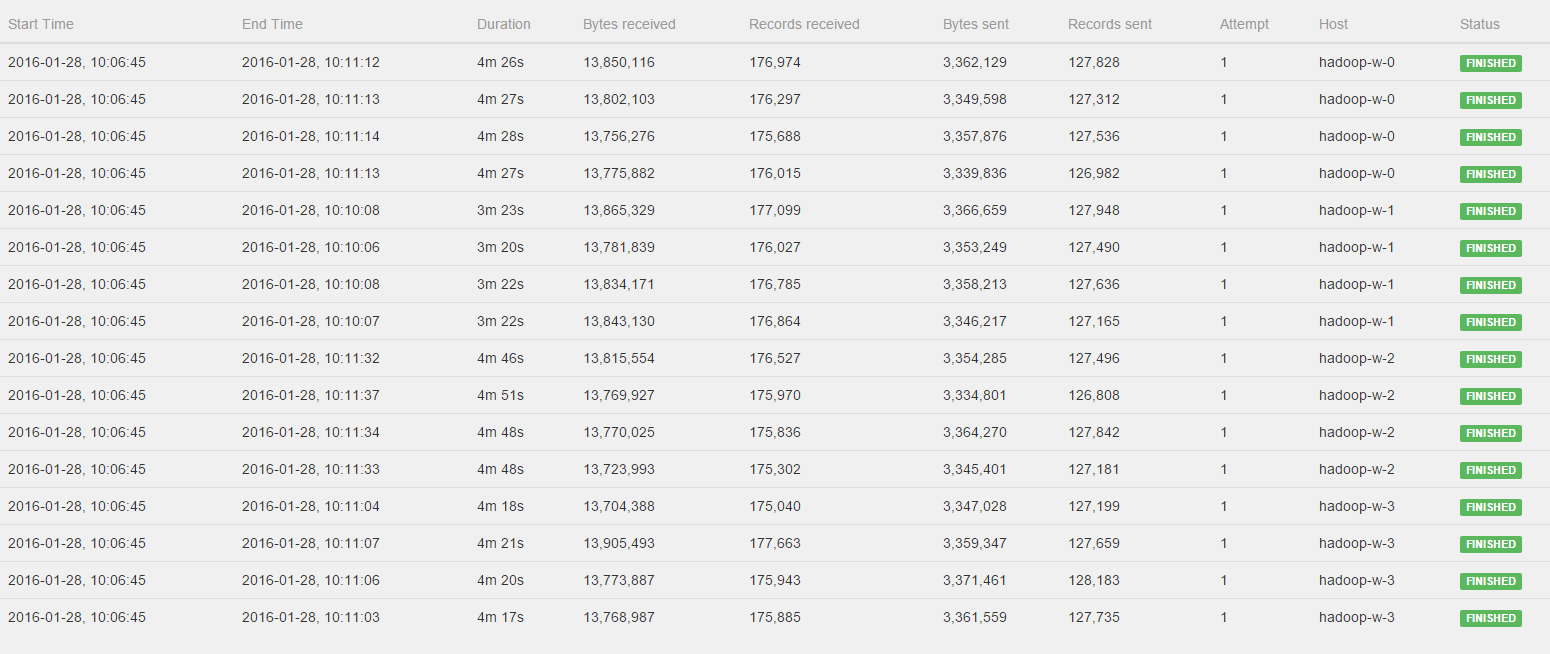 All workers get to process a fairly distributed amount of bytes and records, BUT hadoop-w-0, hadoop-w-2 and hadoop-w-3 don't start working until hadoop-w-1 is finished. Is this behavior to be expected with a CoGroup or could there still be something wrong in the distrubtion of the data? Kind regards, Pieter 2016-01-27 21:48 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Hi Pieter, you can see in the log that the operators are all started at the same time. However, you're right that they don't finish at the same time. The sub tasks which run on the same node exhibit a similar runtime. However, all nodes (not only hadoop-w-0 compared to the others) show different runtimes. I would guess that this is due to some other load on the GCloud machines or some other kind of asymmetry between the hosts. Cheers, Till On Thu, Jan 28, 2016 at 10:17 AM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Hey! Which CoGroup in the plan are the statistics for? For the first or the second one? Stephan On Thu, Jan 28, 2016 at 10:58 AM, Till Rohrmann <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
In reply to this post by Till Rohrmann
Hi Till, Stephan, Indeed I think you're right it is just a coincidence that the three jobs started producing output as soon as the first one finished. Getting back to my comment that after the upgrade to Flink 0.10.1 the job was much faster I searched a bit further. I've now noticed that after setting up a fresh GCloud cluster the job runs roughly 15x faster than the case I just showed you. Im executing many, many jobs in sequence and it seems as if performance is degrading a lot over time. Let me tell you what I'm doing exactly: I'm running a set of 16 queries in sequence on the cluster. Each query is executed multiple (5) times in a row so I can average measurements for a more reliable estimate of performance in the GCloud. This means that I'm running a total of 60 jobs in sequence, and on 5 different datasets, totalling to 300 jobs. For each job I get the execution environment, define the query, write to an output file and run the env.execute. After each job I clear the output folder so the next job can start fresh. Now I'm wondering what causes this performance degradation. Could this have to do with the GCloud (I surely hope they don't scale back my performance by 90% ;-) , do I need to some more cleaning and resetting on the Flink Cluster, or is my above approach asking for trouble? Thanks again for your help! - Pieter 2016-01-28 10:58 GMT+01:00 Till Rohrmann <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
In reply to this post by Stephan Ewen
Hi Stephen, it was the first CoGroup :-) - Pieter 2016-01-28 11:24 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
In reply to this post by Pieter Hameete
Hi Till and Stephan, I've got some additional information. I just ran a query 60 times in a row, and all jobs ran in roughly the same time. I did this for both a simple job that requires intensive parsing and a more complex query that has several cogroups. Neither of the cases showed any slowing down. I believe this is an indication that it is not a problem with unreliable I/O or computational resources. However, when I now run the complete set of 15 different queries again, with 3 repetitions each, things start slowing down very quickly. The code I use to run the jobs can be found here: https://github.com/PHameete/dawn-flink/blob/feature/loading-algorithm-v2/src/main/scala/wis/dawnflink/performance/DawnBenchmarkSuite.scala I run this as follows in the GCloud: /flink run dawn-flink.jar gs://dawn-flink/data/split4G gs://dawn-flink/output/ 3 result.csv Is there something I am doing incorrectly by running these different queries in sequence like this? I have attempted parametrizing further so I would call ./flink run for each separate query but this did not make a difference. Cheers! - Pieter 2016-01-28 11:28 GMT+01:00 Pieter Hameete <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Hi! Thank you for looking into this. Such gradual slowdown is often caused by memory leaks, which reduces available memory and makes GC more expensive. Can you create a heap dump after the series of runs that cause the slowdown? Then we can have a look whether there are leaked Flink objects, or if the user code is causing that. Greetings, Stephan On Thu, Jan 28, 2016 at 5:58 PM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Hi Stephan, cheers for your response. I have the heap dumps, you can download them here (note they are fairly large, tarballs of up to 2GB each, untarred up to 12GB) : Job Manager: after the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapm-after.tar.gz Task Manager 0: after the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw0-after.tar.gz during the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw0-during.tar.gz during the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw0-during2.tar.gz Task Manager 1: after the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw1-after.tar.gz during the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw1-during.tar.gz during the slowdown series: https://storage.googleapis.com/dawn-flink/heapdumps/heapw1-during2.tar.gz I've also attempted to reproduce the issue in a local cluster with a single 4CPU task manager, however no slowdown occurs so far. Please let me know if there is anything else I can provide you with. - Pieter 2016-01-28 22:18 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Super, thanks a lot. I think we need to find some time and look through this, but this should help a lot! Greetings, Stephan On Fri, Jan 29, 2016 at 1:32 PM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Hi Stephan, did you manage to take a look at the dumps? I have looked myself but I could not find anything that would point towards a memory leak in my user code. I have a parser that creates quite a lot of objects, but these are not abundantly present in the heap dump. I did see that the majority of the heap was consisting of byte objects (but this is normal?) as well as Akka objects in another dump. I am not familiar enough with Flink to know what is normal to see in the heap dumps. I am looking forward to hearing what you think :-) - Pieter 2016-01-29 13:36 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
You are using Flink 0.10, right? The byte[] are simply Flink's reserved managed memory. It is expected that they occupy a large portion of the memory. (assuming you run 0.10 is BATCH mode). These byte[] should also not get more or fewer, so they should not cause degradation. I can also not spot anything suspicious (in the after slowdown dumps). The fact that the byte[] make up for 80% of the memory means that nothing else can really be leaking a lot. Did you configure a specific amount of memory (taskmanager.memory.size or taskmanager.memory.fraction) ? Greetings, Stephan On Wed, Feb 3, 2016 at 10:04 AM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
EDIT: The by[] make up for 98% of the memory. That seems correct. 80% would mean something else is consuming a lot, which should not be the case. On Fri, Feb 5, 2016 at 6:09 PM, Stephan Ewen <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Hi Stephan, cheers for looking at this :-) The TaskManagers have a 12GB of available heapspace configured using taskmanager.heap.mb. The configurations that you mention should be default. - Pieter 2016-02-05 18:10 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Imbalanced workload between workers
|
|
Hi! If there is no memory leak, what could be the reason? - Thread leaks? You can try and create thread dumps (via jstack) after the slowdown (between invocations of the program). - Is the JITer going into weird behavior, in the end not compiling as aggressively? Maybe classes do not get properly unloaded, or the code cache (where JITted assembler code is stored) flows over. Can you check at the beginning of the log files, what garbage collectors are set? Is classunloading is actvated? Greetings, Stephan On Fri, Feb 5, 2016 at 6:14 PM, Pieter Hameete <[hidden email]> wrote:
|
Re: Imbalanced workload between workers
|
|
Hi Stephan, Thank you for your time looking into this. I might be able to check those things later if you believe it would be interesting to find the source of this problem. For me the Google Cloud is getting too expensive to use right now. Instead I found a YARN cluster that I can use for free and I'm hoping that getting fresh containers for each job will be a good workaround until then. Cheers, - Pieter 2016-02-06 15:12 GMT+01:00 Stephan Ewen <[hidden email]>:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |