Flink 1.0 Critical memory issue/leak with a high throughput stream

Flink 1.0 Critical memory issue/leak with a high throughput stream

|
We are using Flink in production and running into some high CPU and memory issues. Our initial analysis points to high memory utilization that exponentially increases the CPU required for GC and ultimately takes down the task managers.
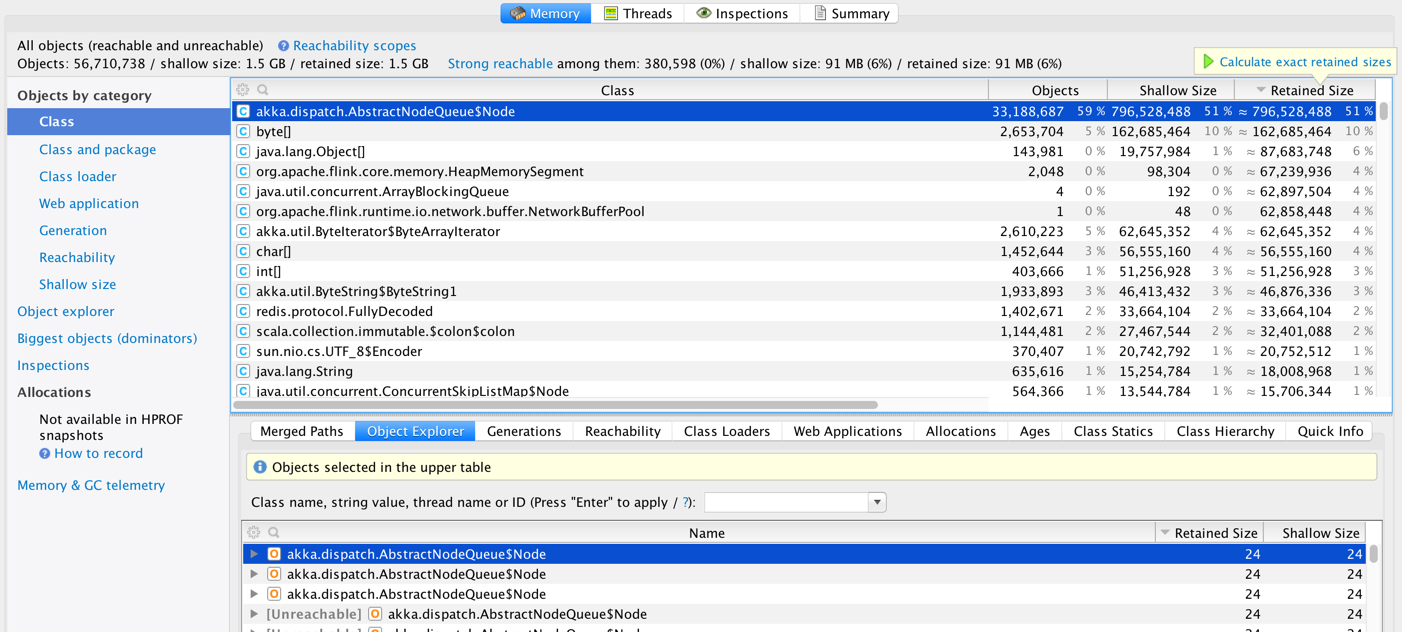
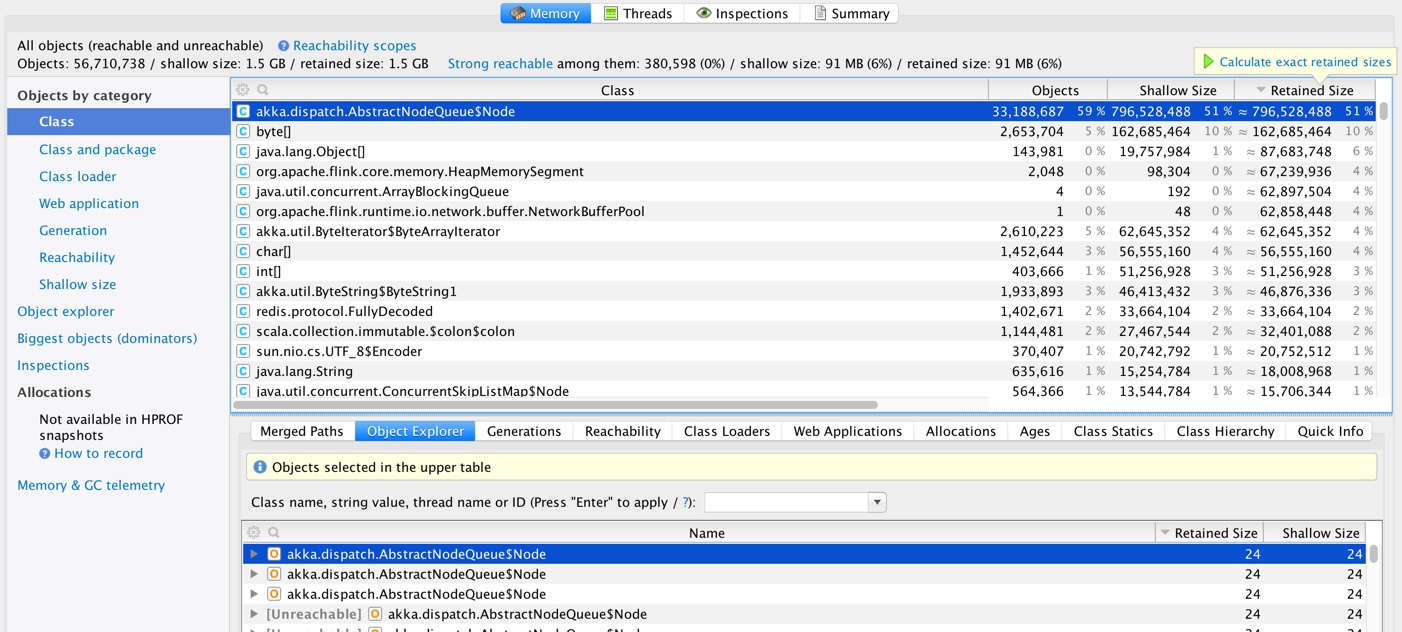
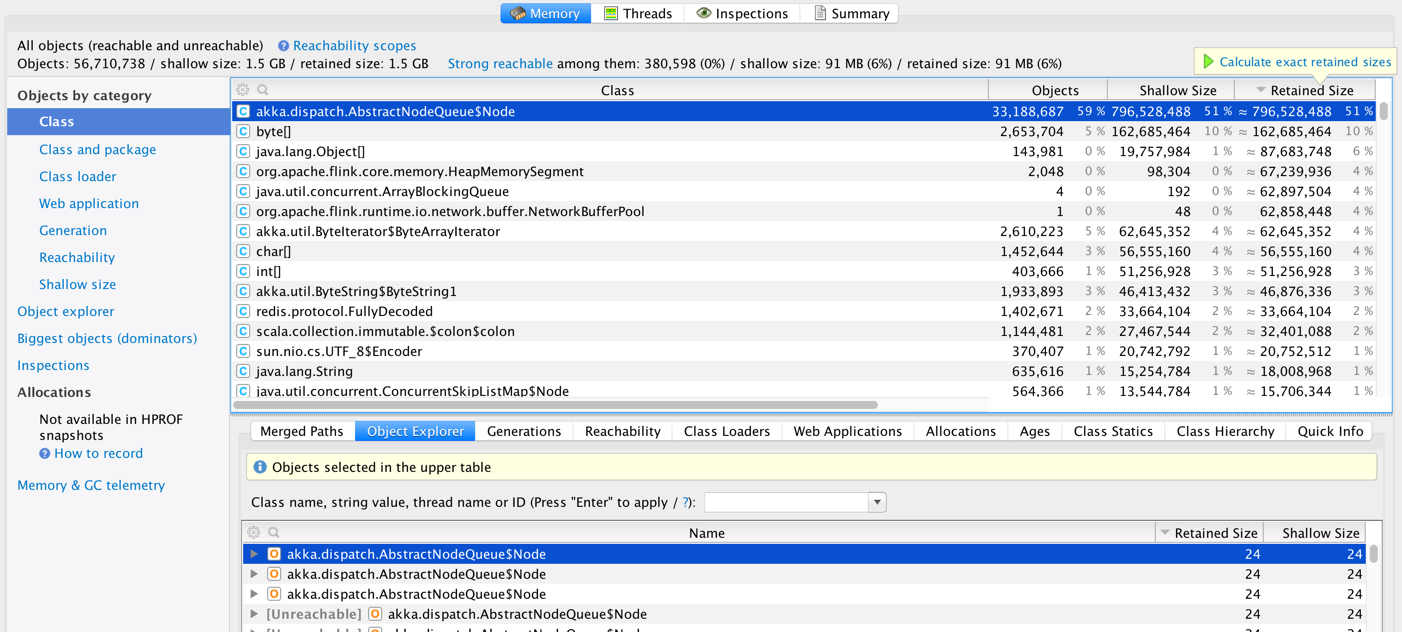
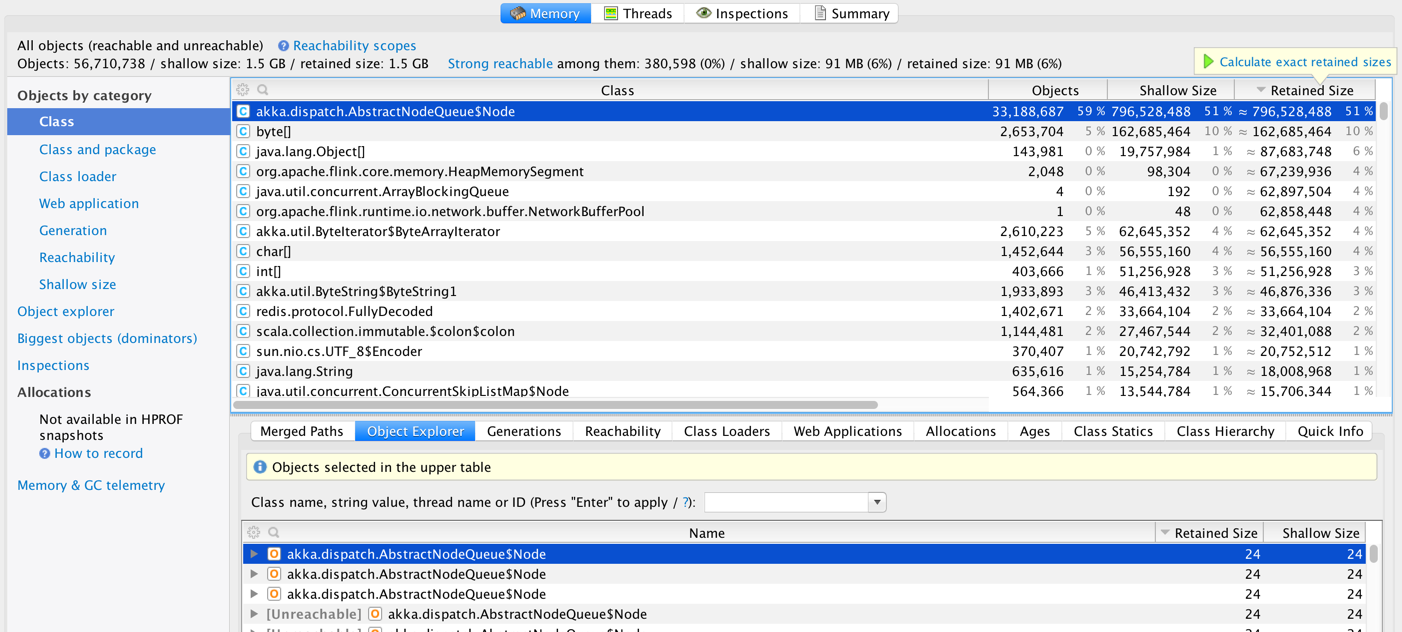
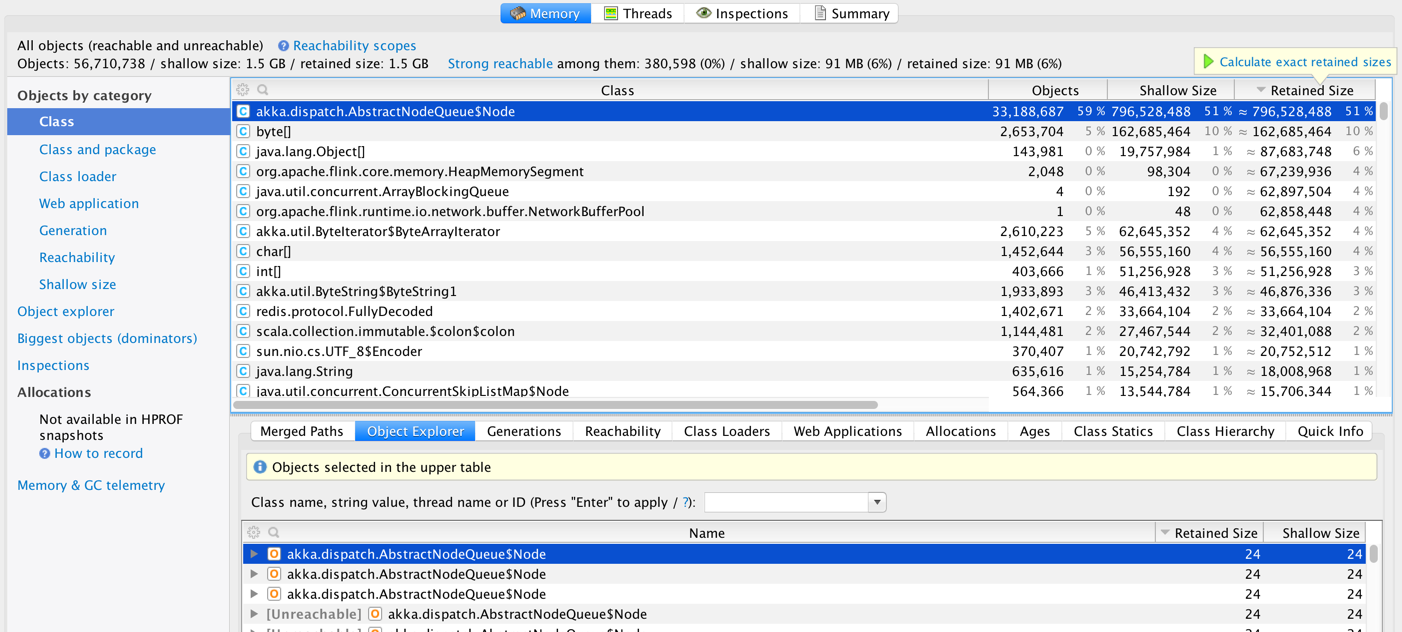
We are running Flink 1.0 on YARN (on Amazon EMR).  We consuming a real-time stream from Kafka and creating some windows and making some calls to Redis (using Rediscala - a non-blocking Redis client lib based on Akka). We took some heap dumps and looks like we have a large number of instances of akka.dispatch.AbstractQueueNode. 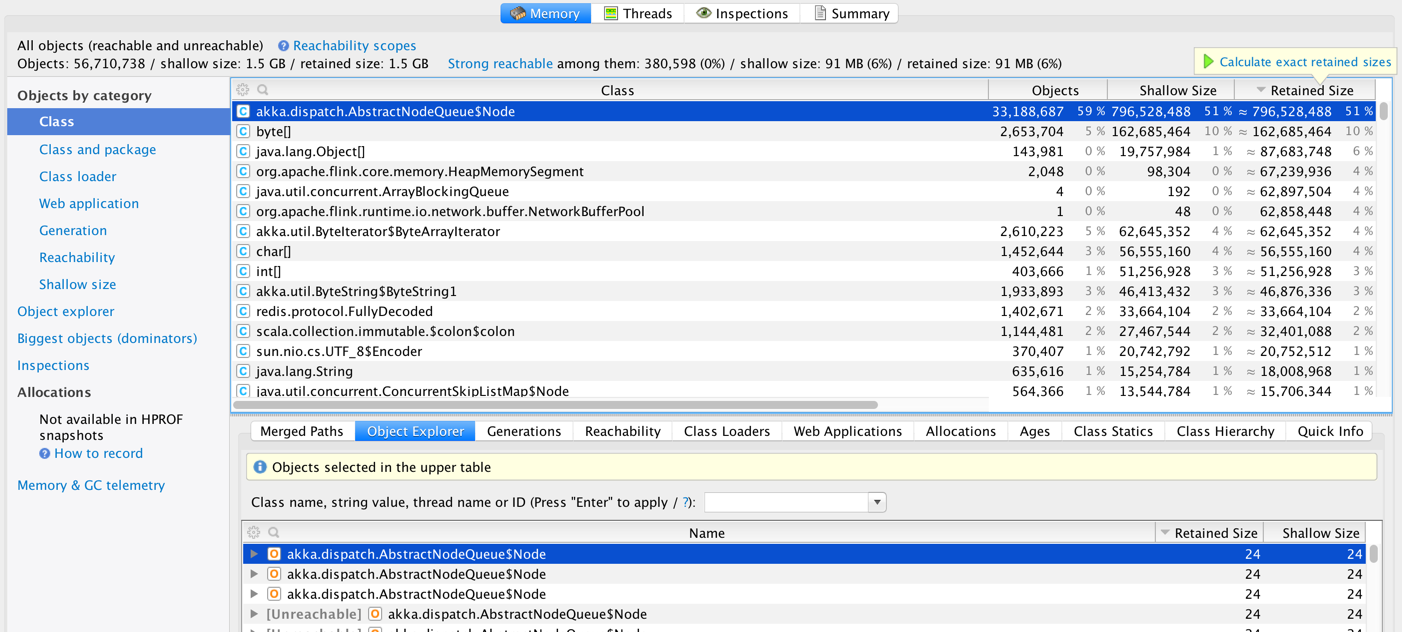 And most of these are unreachable.  It is not clear if this is 1) an Akka issue [1,2] 2) a Flink issue 3) a Rediscala client library issue 4) an issue with the way we are using Scala Futures inside Flink code. 5) Flink running on YARN issue Has anyone else seen a similar issue in Flink? We are planning to test this again with a custom build with a newer version of Akka (see [1]) -Soumya |
Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Hi Soumya, I haven't see this problem before. Thus, I would suspect that the excessive amounts of AbstractQueueNodes could be caused by the Rediscala client library. Maybe you could try to use a different library and then investigate whether the problem still remains or disappears. Cheers, Till On Thu, Jun 9, 2016 at 10:29 AM, Soumya Simanta <[hidden email]> wrote:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
In reply to this post by Soumya Simanta
Hi Soumya, this looks like an issue with Rediscala or Akka (or the way Rediscala uses Akka) to me.I am not aware of any other Flink user having a similar issue with too many AbstractNodeQueue$Nodes. Trying to upgrade to Akka 2.3.15 sounds like a good idea to me. It would be great if you could report whether this fixes the problems or not. Thanks, Fabian 2016-06-09 10:29 GMT+02:00 Soumya Simanta <[hidden email]>:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Hi! Is it possible for you to run an experiment with a job that does not use any Redis communication? If Flink is only writing to Redis, one way to test this would be to use a "dummy sink" operation that does not instantiate Rediscala. That would help to see whether the issue in in Flink's use of Akka, or in Rediscala's use of Akka... Greetings, Stephan On Thu, Jun 9, 2016 at 5:42 PM, Fabian Hueske <[hidden email]> wrote:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Till, Fabian and Stephan - thanks for responding and providing a great framework. In the short term we cannot get away with Redis because we are keeping some global state there. We do lookups on this global state as the stream is processed, so we cannot treat it just as a sink (as suggested by Stephan). Some more points/observations about our implementation: 1. Currently we are creating a new ActorSystem to run Rediscala 2. Since Rediscala is a non-blocking async library the results of all operations are wrapped inside a Future. So we end up a lot of these futures. 3. Currently all futures are being executed inside the global execution context. We upgraded Rediscala to Akka 2.3.15 without any impact. Next we are trying to upgrade Flink to Akka 2.3.15. Just curious if there is a way to keep global state in a fault-tolerant fashion in Flink? If yes, then we can get away from Redis in the near future. Thanks again! -Soumya On Fri, Jun 10, 2016 at 12:23 AM, Stephan Ewen <[hidden email]> wrote:
|


|
|
Hi, what about Till's suggestion to use another library? I guess the asynchronous nature of the Rediscala library makes it quite hard to use it together with Flink. If Flink is processing data faster than redis is able to handle it, you'll end up with a lot of pending futures. So by decoupling the redis requesting from Flink, too fast data processing will naturally lead to these memory issues. With blocking redis calls (maybe using a threadpool to smooth it a bit) you can slow down Flink to the speed of Redis. Since we are loading our Akka version from our flink jar's we'll probably not load the akka classes from your user code jar. So you'd have to rebuild flink with a different Akka version. On Fri, Jun 10, 2016 at 2:31 AM, Soumya Simanta <[hidden email]> wrote:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Robert, We have not tried another library yet because we want to avoid blocking. We agree with your hypothesis. In fact, we are trying to verify it using a standalone test. However, for us blocking will mean higher lag and therefore higher latency. But we have some very strong low latency requirements. For us the ideal solution would be to process everything inside Flink without making any external lookups in Redis. I'll keep this thread updated as we make progress in our findings. Any other suggestion/ideas will be appreciated. Thanks again! -Soumya On Fri, Jun 10, 2016 at 6:36 PM, Robert Metzger <[hidden email]> wrote:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Out of curiosity: Were you able to resolve the issue? On Fri, Jun 10, 2016 at 6:39 PM, Soumya Simanta <[hidden email]> wrote:
|


Re: Flink 1.0 Critical memory issue/leak with a high throughput stream
|
|
Stephan, I was going to report back on this issue. Here is a summary of what we tried.
Again our ultimate solution would be to avoid Redis all together and perform everything inside Flink using ValueState or any other construct that allows us to query with low latency and provides support for Geo Queries (e.g., Radial Geo search) as well. Thanks -Soumya On Mon, Jul 4, 2016 at 8:47 PM, Stephan Ewen <[hidden email]> wrote:
|


| Free forum by Nabble | Edit this page |