Data loss in Flink Kafka Pipeline


|
Hi,
I am running a Streaming pipeline(written in Beam Framework) with Flink. Operator sequence is -> Reading the JSON data, Parse JSON String to the Object and Group the object based on common key. I noticed that GroupByKey operator throws away some data in between and hence I don't get all the keys as output. In the below screenshot, 1001 records are read from kafka Topic , each record has unique ID . After grouping it returns only 857 unique IDs. Ideally it should return 1001 records from GroupByKey operator. 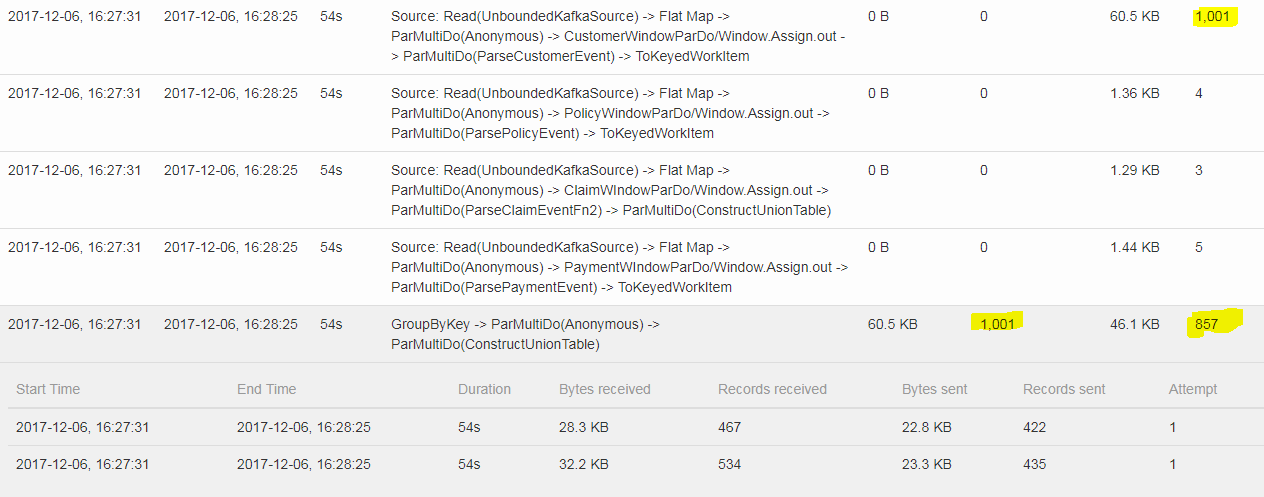 Any idea, what can be the issue? Thanks in advance! -- Thanks & Regards, Nishu Tayal |
|
|
I would recommend to also print the count of input and output of each
operator by using Accumulator. Cheers, Sendoh -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: Data loss in Flink Kafka Pipeline
|
|
Is it possible that the data is dropped due to being late, i.e., records with timestamps behind the current watemark? What kind of operations does your program consist of?2017-12-07 10:20 GMT+01:00 Sendoh <[hidden email]>: I would recommend to also print the count of input and output of each |
|
|
Nishu You might consider sideouput with metrics at least after window. I would suggest having that to catch data screw or partition screw in all flink jobs and amend if needed. Chen On Thu, Dec 7, 2017 at 9:48 AM Fabian Hueske <[hidden email]> wrote:
-- Chen
Software Eng, Facebook |
Re: Data loss in Flink Kafka Pipeline
|
|
Hi, Thanks for your inputs. I am reading Kafka topics in Global windows and have defined some ProcessingTime triggers. Hence there is no late records. Program is performing join between multiple kafka topics. It consists following types of Transformation sequence is something like : 1. Read Kafka topic 2. Apply Window and trigger on kafka topic 3. Parse the data into POJO objects 4. Group the POJO objects by their keys 5. Read other topics and perform same steps 6. Join the Grouped Output with other topic Grouped records. I get all records until 3rd point as expected. But in point 4, few keys are dropped with inconsistent behavior in each run. I have tried the pipeline with different-2 setup i.e 1 task slot, 1 parallel thread, or multiple task slot n multiple thread. It looks like BeamFlink runner has some bug in the pipeline translation in streaming pipeline scenario. Thanks, Nishu On Thu, Dec 7, 2017 at 7:13 PM, Chen Qin <[hidden email]> wrote:
Thanks & Regards, Nishu Tayal |
Re: Data loss in Flink Kafka Pipeline
|
|
Hi Nishu, the data loss might be caused by the fact that processing time triggers do not fire when the program terminates.2017-12-07 23:13 GMT+01:00 Nishu <[hidden email]>:
|
Re: Data loss in Flink Kafka Pipeline
|
|
Hi Fabian, Program is running until I manually stop it. Trigger is also firing as expected because I read the entire data after the trigger firing to see what data is captured. And pass that data over to GroupByKey as Input. Its using Global window so I accumulate entire data each time the trigger fires. So I doubt if triggers are causing the issue. Thanks & regards, Nishu On Thu, Dec 7, 2017 at 11:47 PM, Fabian Hueske <[hidden email]> wrote:
Thanks & Regards, Nishu Tayal |
Re: Data loss in Flink Kafka Pipeline
|
|
Hmm, I see... I'm running out of ideas. You might be right with your assumption about a bug in the Beam Flink runner. In this case, this would be an issue for the Beam project which hosts the Flink runner. But it might also be an issue on the Flink side. |
Re: Data loss in Flink Kafka Pipeline
|
|
Hi,
Could you maybe post your pipeline code. That way I could have a look. Best, Aljoscha > On 8. Dec 2017, at 12:31, Fabian Hueske <[hidden email]> wrote: > > Hmm, I see... > I'm running out of ideas. > > You might be right with your assumption about a bug in the Beam Flink runner. In this case, this would be an issue for the Beam project which hosts the Flink runner. > But it might also be an issue on the Flink side. > > Maybe Aljoscha (in CC), one of the authors of the Flink runner and a Beam+Flink committer, can help to identify the issue. > > Best, Fabian > > |
Re: Data loss in Flink Kafka Pipeline
|
|
In reply to this post by nishutayal
Hi Fabian,
Actually I found a JIRA issue for the similar issue : https://issues.apache.org/ I have 4 kafka topics as input source. Those are read using GlobalWindow and processingTime triggers. And further joined based on common keys. There are multiple GroupByKey transformations in pipeline. After reading BEAM-3225, I assume that this is the bug in the runner. Thanks for connecting with Aljoscha. :) Hi Aljoscha, I will share the code with you in another mail thread. Thanks & regards, Nishu On Fri, Dec 8, 2017 at 1:04 PM, Aljoscha Krettek <[hidden email]> wrote: Hi, Thanks & Regards, Nishu Tayal |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |