A use-case for Flink and reactive systems

A use-case for Flink and reactive systems

|
Hi all,
I am working on a prototype which should include Flink in a reactive systems software. The easiest use-case with a traditional bank system where I have one microservice for transactions and another one for account/balances. Both are connected with Kafka. Transactions record a transaction and then send, via Kafka, a message which include account identifer and the amount. On the other microservice I want to have Flink consuming this topic and updating the balance of my account based on the incoming message. it needs to pull from the DB my data and make the update. The DB is Couchbase. I spent few hours online today, but so far I only found there's no sink for Couchbase, I need to build one which shouldn't be a big deal. I haven't found information on how I can make Flink able to interact with a DB to retrieve information and store information. I guess the case is a good case, as updating state in an event sourcing based application is part of the first page of the manual. I am not looking to just dump a state into a DB, but to interact with the DB: retrieving data, elaborating them with the input coming from my queue, and persisting them (especially if I want to make a second prototype using Flink CEP). I probably even read how to do it, but I didn't recognize. Can anybody help me to figure out better this part? Thanks, Y. |
Re: A use-case for Flink and reactive systems
|
|
Looks interesting. As I understand you have a microservice based on ingestion where a topic is defined for streaming messages that include transactional data. These transactions should already exist in your DB. For now we look at DB as part of your microservices and we take a logical view of it. So
So far we have avoided interfaces among these services. But I gather M1 and M2 are well established. Assuming that Couchbase is your choice of DB I believe it provides JDBC drivers of some sort. It does not have to be Couchbase. You can achieve the same with Hbase as well or MongoDB. Anyhow the only challenge I see here is the interface between your Flink application in M2 and M3 HTH Dr Mich Talebzadeh
LinkedIn https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw
http://talebzadehmich.wordpress.com Disclaimer: Use it at your own risk. Any and all responsibility for any loss, damage or destruction of data or any other property which may arise from relying on this email's technical content is explicitly disclaimed. The author will in no case be liable for any monetary damages arising from such loss, damage or destruction.
On Wed, 4 Jul 2018 at 17:56, Yersinia Ruckeri <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
In reply to this post by Yersinia Ruckeri
I think it is a little bit overkill to use Flink for such a simple system.
> On 4. Jul 2018, at 18:55, Yersinia Ruckeri <[hidden email]> wrote: > > Hi all, > > I am working on a prototype which should include Flink in a reactive systems software. The easiest use-case with a traditional bank system where I have one microservice for transactions and another one for account/balances. > Both are connected with Kafka. > > Transactions record a transaction and then send, via Kafka, a message which include account identifer and the amount. > On the other microservice I want to have Flink consuming this topic and updating the balance of my account based on the incoming message. it needs to pull from the DB my data and make the update. > The DB is Couchbase. > > I spent few hours online today, but so far I only found there's no sink for Couchbase, I need to build one which shouldn't be a big deal. I haven't found information on how I can make Flink able to interact with a DB to retrieve information and store information. > > I guess the case is a good case, as updating state in an event sourcing based application is part of the first page of the manual. I am not looking to just dump a state into a DB, but to interact with the DB: retrieving data, elaborating them with the input coming from my queue, and persisting them (especially if I want to make a second prototype using Flink CEP). > > I probably even read how to do it, but I didn't recognize. > > Can anybody help me to figure out better this part? > > Thanks, > Y. |
Re: A use-case for Flink and reactive systems
|
|
In reply to this post by Mich Talebzadeh
My idea started from here: https://flink.apache.org/usecases.html First use case describes what I am trying to realise (https://flink.apache.org/img/usecases-eventdrivenapps.png) My application is Flink, listening to incoming events, changing the state of an object (really an aggregate here) and pushing out another event. States can be persisted asynchronously; this is ok. My point on top to this picture is that the "state" it's not just persisting something, but retrieving the current state, manipulate it new information and persist the updated state. Y On Wed, Jul 4, 2018 at 10:16 PM, Mich Talebzadeh <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
Hi Yersinia, The main idea of an event-driven application is to hold the state (i.e., the account data) in the streaming application and not in an external database like Couchbase. This design is very scalable (state is partitioned) and avoids look-ups from the external database because all state interactions are local. Basically, you are moving the database into the streaming application. There are a few things to consider if you maintain the state in the application: - You might need to mirror the state in an external database to make it queryable and available while the streaming application is down. - You need to have a good design to ensure that your consistency requirements are met in case of a failure (upsert writes can temporarily reset the external state). - The design becomes much more challenging if you need to access the state of two accounts to perform a transaction (subtract from the first and add to the second account) because Flink state is distributed per key and does not support remote lookups. If you do not want to store the state in the Flink application, I agree with Jörn that there's no need for Flink. Hope this helps, Fabian 2018-07-05 10:45 GMT+02:00 Yersinia Ruckeri <[hidden email]>:
|
Re: A use-case for Flink and reactive systems
|
|
It helps, at least it's fairly clear now.
I am not against storing the state into Flink, but as per your first point, I need to get it persisted, asynchronously, in an external database too to let other possible application/services to retrieve the state. What you are saying is I can either use Flink and forget database layer, or make a java microservice with a database. Mixing Flink with a Database doesn't make any sense. My concerns with the database is how do you work out the previous state to calculate the new one? Is it good and fast? (moving money from account A to B isn't a problem cause you have two separate events). Moreover, a second PoC I was considering is related to Flink CEP. Let's say I am elaborating sensor data, I want to have a rule which is working on the following principle: - If the temperature is more than 40 - If the temperature yesterday at noon was more than 40 - If no one used vents yesterday and two days ago then do something/emit some event. This simple CEP example requires you to mine previous data/states from a DB, right? Can Flink be considered for it without an external DB but only relying on its internal RockDB ? Hope I am not generating more confusion here. Y On Thu, Jul 5, 2018 at 11:21 AM, Fabian Hueske <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
In reply to this post by Fabian Hueske-2
Hi Fabian, On your point below … Basically, you are moving the database into the streaming application. This assumes a finite size for the data in the streaming application to persist. In terms of capacity planning how this works? Some applications like Fraud try to address this by deploying databases like Aerospike that the Keys are kept in the memory and indexed and the values are stored on SSD devices. I was wondering how Flink in general can address this? Regards, Dr Mich Talebzadeh
LinkedIn https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw
http://talebzadehmich.wordpress.com Disclaimer: Use it at your own risk. Any and all responsibility for any loss, damage or destruction of data or any other property which may arise from relying on this email's technical content is explicitly disclaimed. The author will in no case be liable for any monetary damages arising from such loss, damage or destruction.
On Thu, 5 Jul 2018 at 11:22, Fabian Hueske <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
In reply to this post by Yersinia Ruckeri
Hi, What you are saying is I can either use Flink and forget database layer, or make a java microservice with a database. Mixing Flink with a Database doesn't make any sense. I would have thought that moving with microservices concept, Flink handling streaming data from the upstream microservice is an independent entity and microservice on its own assuming loosely coupled terminologies here Database tier is another microservice that interacts with your Flink and can serve other consumers. Indeed in classic CEP like Aleri or StreamBase you may persist your data to an external database for analytice. HTH Dr Mich Talebzadeh
LinkedIn https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw
http://talebzadehmich.wordpress.com Disclaimer: Use it at your own risk. Any and all responsibility for any loss, damage or destruction of data or any other property which may arise from relying on this email's technical content is explicitly disclaimed. The author will in no case be liable for any monetary damages arising from such loss, damage or destruction.
On Thu, 5 Jul 2018 at 12:26, Yersinia Ruckeri <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
I guess my initial bad explanation caused confusion. After reading again docs I got your points. I can use Flink for online streaming processing, letting it to manage the state, which can be persisted in a DB asynchronously to ensure savepoints and using queryable state to make the current state available for queries (I know this API can change, but let's assume it's ok for now). DB size is curious, what about if I plan to use it in a true big environment? We used a financial system, so if I am BNP Paribas, HSBC or VISA and I want to process incoming transactions to update the balance. Flink is into receiving transactions and updating the balance (state). However, I have 100 millions of accounts, so even scaling Flink I might have some storage limit. My research around Flink was for investigating two cases: 1. see if and how Flink can be put into an event-sourcing based application using CQRS to process an ongoing flow of events without specifically coding an application (which might be a microservice) that make small upsert into a DB (keep the case of a constant flow of transactions which determine a balance update in a dedicated service) 2. Using CEP to trigger specific events based on a behaviour you have been following. Take the case of sensors I described or supermarket points systems: I want to give 1k points to all customers who bought tuna during last 3 months and spent more than 100 euro per weeks and installed supermarket mobile app since the beginning of the year. I want to do it online processing the flow, rather than triggering an offline routine which mines your behaviour. I got stuck understanding that Flink don't work with the DB, except for RockDB which it can be implemented internally. Hence, unless I redefine my cases (which I aim to do), Flink isn't the best choice here. Y On Thu, Jul 5, 2018 at 2:09 PM, Mich Talebzadeh <[hidden email]> wrote:
|
Re: A use-case for Flink and reactive systems
|
|
Hi Yersinia, let me reply to some of your questions. I think these answers should also address most of Mich's questions as well. > What you are saying is I can either use Flink and forget database
layer, or make a java microservice with a database. Mixing Flink with a
Database doesn't make any sense. > My concerns with the
database is how do you work out the previous state to calculate the new
one? Is it good and fast? (moving money from account A to B isn't a
problem cause you have two separate events). Well, you could implement a Flink application that reads and writes account data from/to an external database but that voids the advantages of Flink's state management. A stateful Flink application can maintain the accounts as state (in memory or in RocksDB on disk) and just push updates to an external DB from which external services read. As you said, you can also use queryable state to avoid using an external DB, but that means the state is only accessible when the Flink application is running. > This
simple CEP example requires you to mine previous data/states from a DB,
right? Can Flink be considered for it without an external DB but only
relying on its internal RockDB ? The CEP library also keeps all data to evaluate a pattern in local state. Again, this can be in-memory JVM or RocksDB but not an external DB. > DB size is curious, what about if I plan to use it in a true big
environment? We used a financial system, so if I am BNP Paribas, HSBC or
VISA and I want to process incoming transactions to update the balance.
Flink is into receiving transactions and updating the balance (state).
However, I have 100 millions of accounts, so even scaling Flink I might
have some storage limit. Flink maintains its state in a so-called state backend. We have state
backends that store all data in the JVM heap or in a local, embedded
RocksDB instance on disk. Also state is typically partitioned on a key
and can be spread over many nodes. We have users with applications
that maintain several terabytes of state (10+ TB). > I got stuck understanding that Flink don't work with
the DB, except for RockDB which it can be implemented internally.
Hence, unless I redefine my cases (which I aim to do), Flink isn't the
best choice here. Flink works best if it can manage all required data in its own state and locally read and update it. Flink manages state in JVM memory or an embedded RocksDB instance (embedded
means you don't have to set up anything. All of that happens
automatically). You can store and access the state in an external DB, but that diminishes Flink's
advantages of local state management. There is an AsyncIO operator for such operations. Pushing the result of an application (immediately or in intervals) to an external data
store like Kafka, JDBC, Cassandra or any other database, is fine. However, when writing to an external DB, you should think about the consistency guarantees that you need. 2018-07-05 18:30 GMT+02:00 Yersinia Ruckeri <[hidden email]>:
|
Re: A use-case for Flink and reactive systems
|
|
I was talking with a client that ingest streaming data (not using Kafka but files and logs) unfiltered (think of it as creating a data pipeline without the element of transformation) and putting it in Google BigQuery and using ElasticSearch for data processing; As they found out such simple design is not scalable as there will be a tipping point that the volume of unfiltered data will saturate the database. The other challenge is the scalability when the volume of increases by orders of magnitude. My suggestion looking at as we discussed is to dive the operations into a number of microservices. Principally
I drew a crude sketch as below. Hope you can read it :) 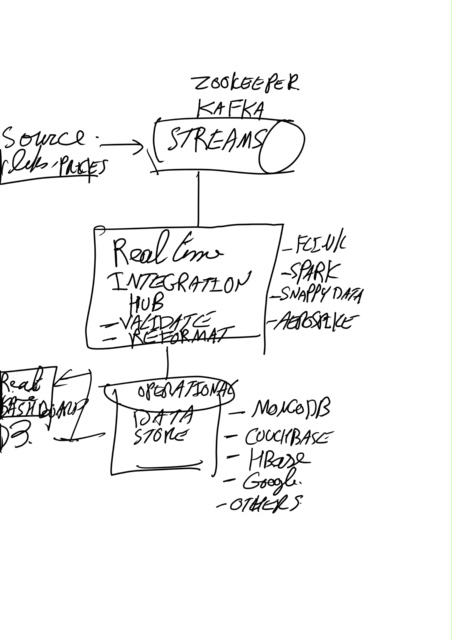 Dr Mich Talebzadeh
LinkedIn https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw
http://talebzadehmich.wordpress.com Disclaimer: Use it at your own risk. Any and all responsibility for any loss, damage or destruction of data or any other property which may arise from relying on this email's technical content is explicitly disclaimed. The author will in no case be liable for any monetary damages arising from such loss, damage or destruction.
On Fri, 6 Jul 2018 at 11:20, Fabian Hueske <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |