windowAll and AggregateFunction


|
Hi all, In our implementation,we are consuming from kafka and calculating distinct with hyperloglog. We are using windowAll function with a custom AggregateFunction but flink runtime shows a little bit unexpected behavior at runtime. Our sources running with parallelism 4 and i expect add function to run after source calculate partial results and at the end of the window i expect it to send 4 hll object to single operator to merge there(merge function). Instead, it sends all data to single instance and call add function there. Is here any way to make flink behave like this? I mean calculate partial results after consuming from kafka with paralelism of sources without shuffling(so some part of the calculation can be calculated in parallel) and merge those partial results with a merge function? Thank you in advance... |
Re: windowAll and AggregateFunction
|
|
Hi,
I think your expectation about windowAll is wrong, from the method documentation: “Note: This operation is inherently non-parallel since all elements have to pass through the same operator instance” and I also cannot think of a way in which the windowing API would support your use case without a shuffle. You could probably build the functionality by hand through, but I guess this is not quite what you want. Best, Stefan > On 9. Jan 2019, at 13:43, CPC <[hidden email]> wrote: > > Hi all, > > In our implementation,we are consuming from kafka and calculating distinct with hyperloglog. We are using windowAll function with a custom AggregateFunction but flink runtime shows a little bit unexpected behavior at runtime. Our sources running with parallelism 4 and i expect add function to run after source calculate partial results and at the end of the window i expect it to send 4 hll object to single operator to merge there(merge function). Instead, it sends all data to single instance and call add function there. > > Is here any way to make flink behave like this? I mean calculate partial results after consuming from kafka with paralelism of sources without shuffling(so some part of the calculation can be calculated in parallel) and merge those partial results with a merge function? > > Thank you in advance... |
|
|
Hi Stefan, Could i use "Reinterpreting a pre-partitioned data stream as keyed stream" feature for this? On Wed, 9 Jan 2019 at 17:50, Stefan Richter <[hidden email]> wrote: Hi, |
Re: windowAll and AggregateFunction
|
|
Hi there,
You should be able to use a regular time-based window(), and emit the HyperLogLog binary data as your result, which then would get merged in your custom function (which you set a parallelism of 1 on). Note that if you are generating unique counts per non-overlapping time window, you’ll need to keep N HLL structures in each operator. — Ken
-------------------------- Ken Krugler +1 530-210-6378 http://www.scaleunlimited.com Custom big data solutions & training Flink, Solr, Hadoop, Cascading & Cassandra |
|
|
Hi Ken, From regular time-based windows do you mean keyed windows? On Wed, Jan 9, 2019, 10:22 PM Ken Krugler <[hidden email] wrote:
|
Re: windowAll and AggregateFunction
|
|
I think you want to key on whatever you’re counting for unique values, so that each window operator gets a slice of the unique values. — Ken
-------------------------- Ken Krugler +1 530-210-6378 http://www.scaleunlimited.com Custom big data solutions & training Flink, Solr, Hadoop, Cascading & Cassandra |
|
|
Hi Ken, I am doing a global distinct. What i want to achive is someting like below. With windowAll it sends all data to single operator which means shuffle all data and calculate with par 1. I dont want to shuffle data since i just want to feed it to hll instance and shuffle just hll instances at the end of the window and merge them. This is exactly the same scenario with global count. Suppose you want to count events for each 1 minutes window. In current case we should send all data to single operator and count there. Instead of this we can calculate sub totals and then send those subtotals to single operator and merge there. 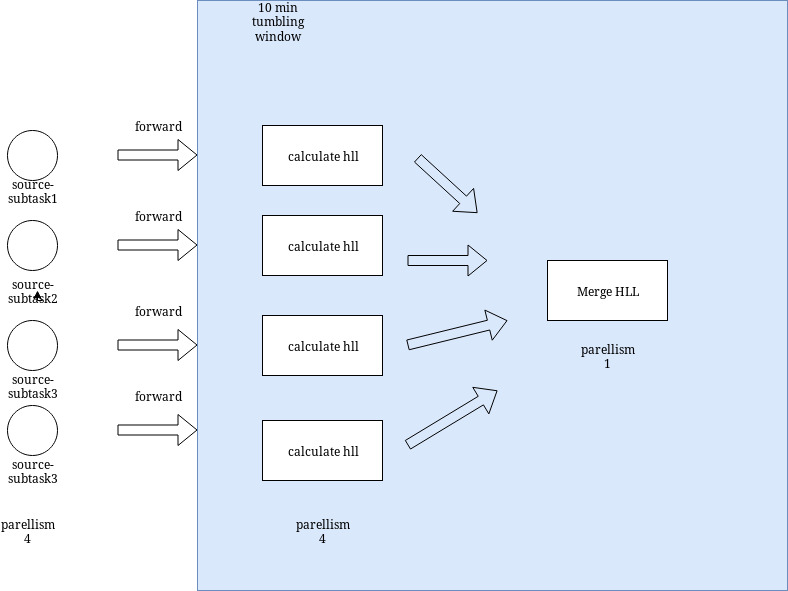 On Thu, 10 Jan 2019 at 02:26, Ken Krugler <[hidden email]> wrote:
|
|
|
I converted to this SingleOutputStreamOperator<Tuple2<Integer, XMPP>> tuple2Stream = sourceStream.map(new RichMapFunction<XMPP, Tuple2<Integer, XMPP>>() { an uggly hack but works. On Thu, 10 Jan 2019 at 10:54, CPC <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |