weird client failure/timeout


|
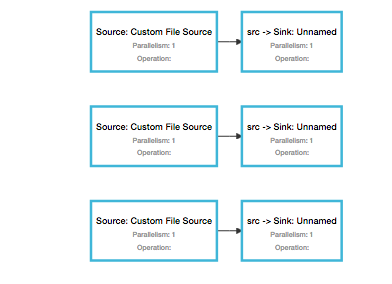
I am trying to construct a topology like this (shown for parallelism of 4) - basically n parallel windowed processing sub-pipelines with single source and single sink: 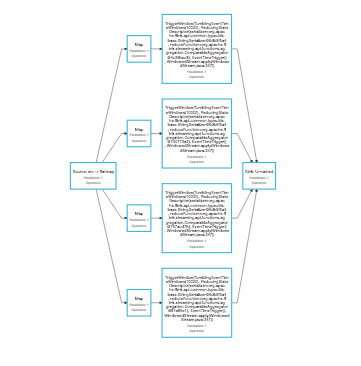 I am getting the following failure (if I go beyond 28 - found empirically using binary search). There is nothing in the job manager logs to troubleshoot this further. Cluster configuration: Standalone cluster with JobManager at /127.0.0.1:6123 Using address 127.0.0.1:6123 to connect to JobManager. JobManager web interface address http://127.0.0.1:10620 Starting execution of program Submitting job with JobID: 27ae3db2946aac3336941bdfa184e537. Waiting for job completion. Connected to JobManager at Actor[<a href="akka.tcp://flink@127.0.0.1:6123/user/jobmanager#2043695445" class="">akka.tcp://flink@127.0.0.1:6123/user/jobmanager#2043695445] ------------------------------------------------------------ The program finished with the following exception: org.apache.flink.client.program.ProgramInvocationException: The program execution failed: Communication with JobManager failed: Job submission to the JobManager timed out. You may increase 'akka.client.timeout' in case the JobManager needs more time to configure and confirm the job submission. at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:410) at org.apache.flink.client.program.StandaloneClusterClient.submitJob(StandaloneClusterClient.java:95) at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:383) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:68) at com.tetration.pipeline.IngestionPipelineMain.main(IngestionPipelineMain.java:116) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:483) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:510) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:404) at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:321) at org.apache.flink.client.CliFrontend.executeProgram(CliFrontend.java:777) at org.apache.flink.client.CliFrontend.run(CliFrontend.java:253) at org.apache.flink.client.CliFrontend.parseParameters(CliFrontend.java:1005) at org.apache.flink.client.CliFrontend.main(CliFrontend.java:1048) Caused by: org.apache.flink.runtime.client.JobExecutionException: Communication with JobManager failed: Job submission to the JobManager timed out. You may increase 'akka.client.timeout' in case the JobManager needs more time to configure and confirm the job submission. at org.apache.flink.runtime.client.JobClient.submitJobAndWait(JobClient.java:137) at org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:406) ... 15 more Caused by: org.apache.flink.runtime.client.JobClientActorSubmissionTimeoutException: Job submission to the JobManager timed out. You may increase 'akka.client.timeout' in case the JobManager needs more time to configure and confirm the job submission. at org.apache.flink.runtime.client.JobClientActor.handleMessage(JobClientActor.java:264) at org.apache.flink.runtime.akka.FlinkUntypedActor.handleLeaderSessionID(FlinkUntypedActor.java:88) at org.apache.flink.runtime.akka.FlinkUntypedActor.onReceive(FlinkUntypedActor.java:68) at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:167) at akka.actor.Actor$class.aroundReceive(Actor.scala:465) at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:97) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516) at akka.actor.ActorCell.invoke(ActorCell.scala:487) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:254) at akka.dispatch.Mailbox.run(Mailbox.scala:221) at akka.dispatch.Mailbox.exec(Mailbox.scala:231) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.pollAndExecAll(ForkJoinPool.java:1253) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1346) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) The code to reproduce this problem is shown below (flink job submission itself fails, the code has been dumbed down to focus on the topology I am trying to build) int nParts = cfg.getInt("dummyPartitions", 4); |
|
|
I am using version 1.1.4 (latest stable)
|
Re: weird client failure/timeout
|
|
The exception says that
Job submission to the JobManager timed out. You may increase 'akka.client.timeout' in case the JobManager needs more time to configure and confirm the job submission.Did you already try that? |
|
|
yes, I had increased it to 5 minutes. It just sits there and bails out again.
> On Jan 23, 2017, at 1:47 AM, Jonas <[hidden email]> wrote: > > The exception says that > > Did you already try that? > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/weird-client-failure-timeout-tp11201p11204.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
|
|
I even make it 10 minutes:
akka.client.timeout: 600s But doesn’t feel like it is taking effect. It still comes out at about the same time with the same error. -Abhishek-
|
|
|
Is there a limit on how many DataStreams can be defined in a streaming program? 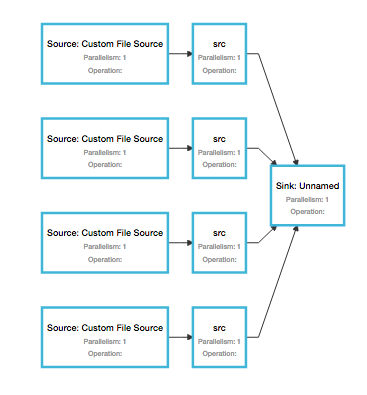 However, when I try to go beyond 51 (found empirically by parametrizing nParts), it barfs again. Submission fails, it wants me to increase akka.client.timeout Here is the reduced code for repro (union at the end itself is not an issue). It is the parallelism of the first for loop: int nParts = cfg.getInt("dummyPartitions", 4); boolean combineAtEnd = cfg.getBoolean("dummyCombineAtEnd", true);
|
|
|
Actually, I take it back. It is the last union that is causing issues (of job being un-submittable). If I don’t conbineAtEnd, I can go higher (at least deploy the job), all the way up to 63.
After that it starts failing in too many files open in Rocks DB (which I can understand and is at least better than silently not accepting my job). Caused by: java.lang.RuntimeException: Error while opening RocksDB instance. at org.apache.flink.contrib.streaming.state.RocksDBStateBackend.initializeForJob(RocksDBStateBackend.java:306) at org.apache.flink.streaming.runtime.tasks.StreamTask.createStateBackend(StreamTask.java:821) at org.apache.flink.streaming.api.operators.AbstractStreamOperator.setup(AbstractStreamOperator.java:118) ... 4 more Caused by: org.rocksdb.RocksDBException: IO error: /var/folders/l1/ncffkbq11_lg6tjk_3cvc_n00000gn/T/flink-io-45a78866-a9da-40ca-be51-a894c4fac9be/3815eb68c3777ba4f504e8529db6e145/StreamSource_39_0/dummy_state/7ff48c49-b6ce-4de8-ba7e-8a240b181ae2/db/MANIFEST-000001: Too many open files at org.rocksdb.RocksDB.open(Native Method) at org.rocksdb.RocksDB.open(RocksDB.java:239) at org.apache.flink.contrib.streaming.state.RocksDBStateBackend.initializeForJob(RocksDBStateBackend.java:304) ... 6 more 
|
Re: weird client failure/timeout
|
|
Hi! I think what you are seeing is the effect of too mans tasks going to the same task slot. Have a look here: https://ci.apache.org/projects/flink/flink-docs-release-1.2/concepts/runtime.html#task-slots-and-resources By default, Flink shares task slots across all distinct pipelines of the same program, for easier "getting started" scheduling behavior. For proper deployments (or setups where you just have very , I would make sure that the program sets different "sharing groups" (via "..slotSharingGroup()") on the different streams. Also, rather than defining 100s of different sources, I would consider defining one source and making it parallel. It works better with Flink's default scheduling parameters. Hope that helps. Stephan On Mon, Jan 23, 2017 at 5:40 PM, Abhishek R. Singh <[hidden email]> wrote:
|
|
|
Hi Stephan, This did not work. For the working case I do see a better utilization of available slots. However the non working case still doesn't work. Basically I assigned a unique group to the sources in my for loop - given I have way more slots than the parallelism I seek. I know about the parallel source. Doesn't source eat up a slot (like spark)? Since my data is pre partitioned, I was merely monitoring from source (keeping it lightweight) and then fanning out to do the actual reads/work from the next (event driven) operator (after splitting the stream from source). This is more like a batch use case. However, I want to use a single streaming job to do streaming + batch. This batch job emits a application level marker that gets fanned back in to declare success/completion for the batch. Since my data is pre partitioned, my windows don't need to run globally. Also I don't know how to have a global keyBy (shuffle) and then send a app marker from source to all the operators. Which is why I keep things hand partitioned (I can send something from source to each of my partitions and they get sent to my sink for a count up to indicate completion). I can control how the markers are sent forward, and my keyBy and windowing happens with a parallelism of 1 - so I know I can reach the next stage to keep propagating my marker. Except that the pattern doesn't scale beyond 8 partitions:( -Abhishek- On Mon, Jan 23, 2017 at 10:42 AM Stephan Ewen <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |