Re: Problems about pv uv in flink sql
Posted by Joshua Fan on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Flink-streaming-sql-group-by-tp34412p40865.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Flink-streaming-sql-group-by-tp34412p40865.html
Anyone can help?
On Tue, Jan 19, 2021 at 2:50 PM Joshua Fan <[hidden email]> wrote:
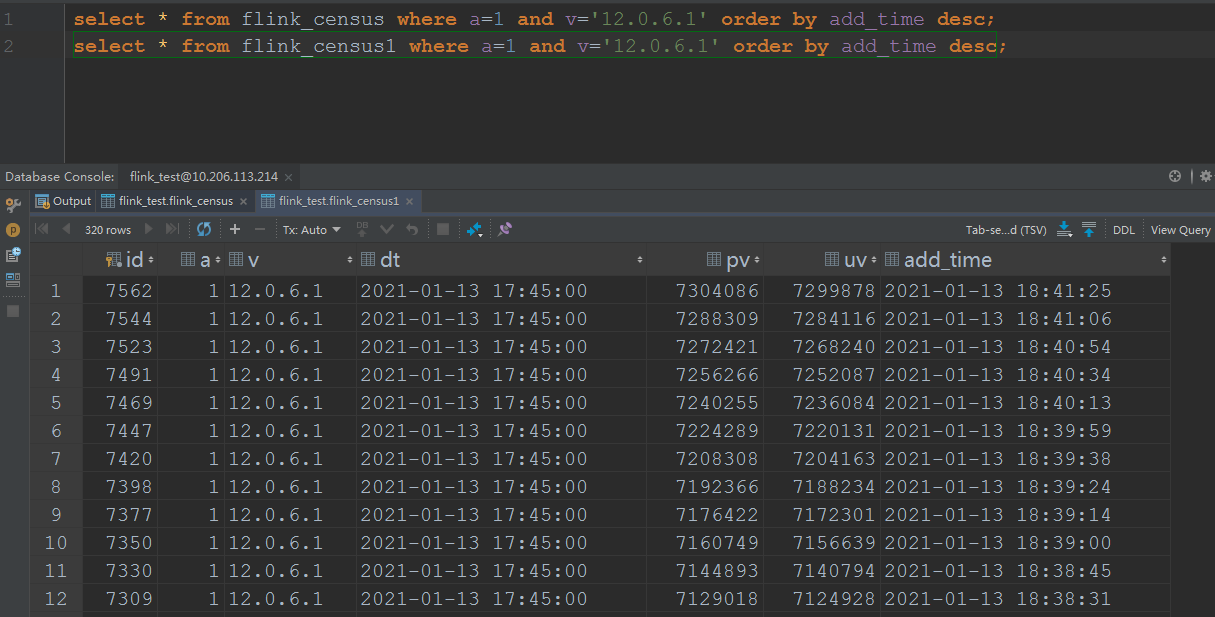
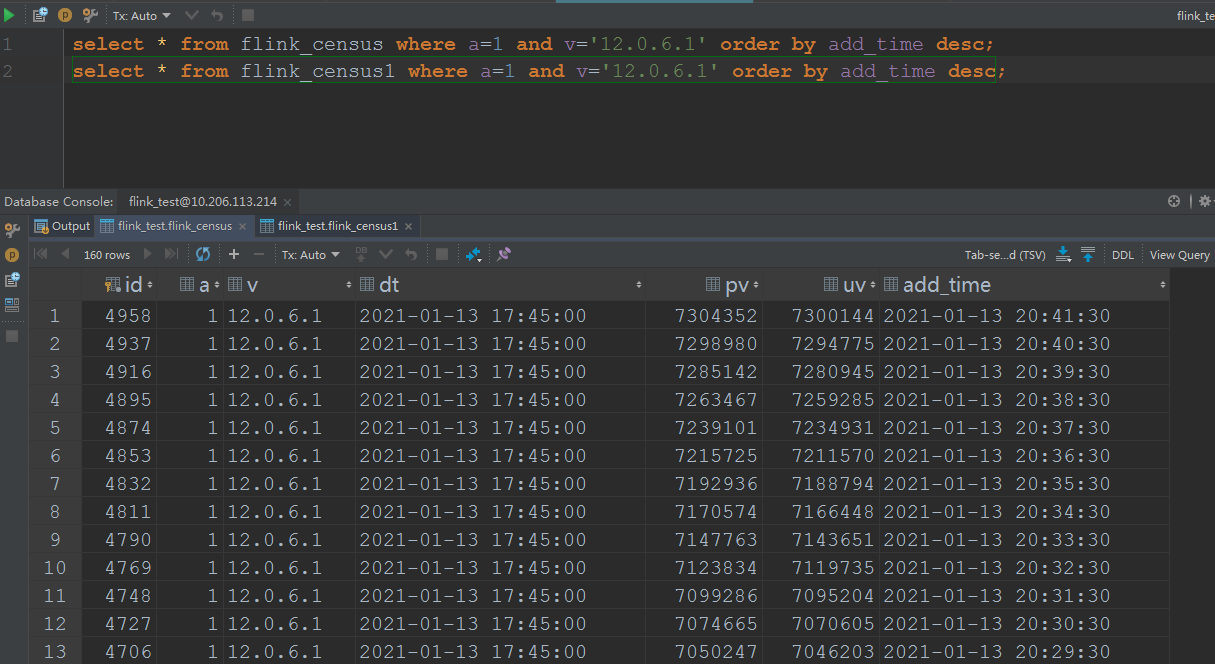
There are three more weird things about the pv uv in Flink SQL.As I described in the above email, I computed the pv uv in two method, I list them below:For the day grouping one, the sql isinsert into pvuv_sinkselect a,v,MAX(DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:00')) dt,COUNT(m2) AS pv,COUNT(DISTINCT m2) AS uv from kafkaTable GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd'),a,v;And the result of one dimension isFor the 1 day window one, the sql isinsert into pvuv_sinkselect a,v,MAX(DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:00')) dt,COUNT(m2) AS pv,COUNT(DISTINCT m2) AS uv from kafkaTable GROUP BY tumble(ts, interval '1' day),a,v;And the result of one dimension isHere are the three questions:1. According to the same cpu and memory and parallelism, but the day grouping solution is faster than the 1 day window solution, the day grouping solution cost 1 hour to consume all the data,but the 1 day window solution cost 4 hours to consume all the data.2. The final result is not the same, the pv/uv of the day grouping is 7304086/7299878, but the pv/uv of the 1 day window is 7304352/7300144, I think both of the result is not accurate, but approximate?So, how about the loss of accuracy? What is the algorithm below the count distinct?3. As the picture of the 1 day window shows, there are many records of the a=1, v=12.0.6.1, dt=2021-01-13 17:45:00, but in my last mail, I noticed the records changed always when the job begin to execute, andone record per dimension, now on the final time, it popped up so many records per dimension, it's weird.Any advice will be fully appreciated.Yours sincerelyJoshOn Tue, Jan 19, 2021 at 2:49 PM Joshua Fan <[hidden email]> wrote:HiI have learned from the community on how to do pv/uv in flink sql. One is to make a yyyyMMdd grouping, the other is to make a day window. Thank you all.I have a question about the result output. For yyyyMMdd grouping, every minute the database would get a record, and many records would be in the database as time goes on, but there would be only a few records in the database according to the day window.for example, the pv would be 12:00,100 12:01,200 12:02,300 12:03,400 according to the yyyyMMdd grouping solution, for the day window solution, there would be only one record as 12:00,100 |12:01,200|12:02,300|12:03,400.I wonder, for the day window solution, is it possible to have the same result output as the yyyyMMdd solution? because the day window solution has no worry about the state retention.Thanks.Yours sincerelyJosh
| Free forum by Nabble | Edit this page |