Re: Job Manager is taking very long time to finalize the Checkpointing.
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Job-Manager-is-taking-very-long-time-to-finalize-the-Checkpointing-tp39555p39659.html
Hi Slim
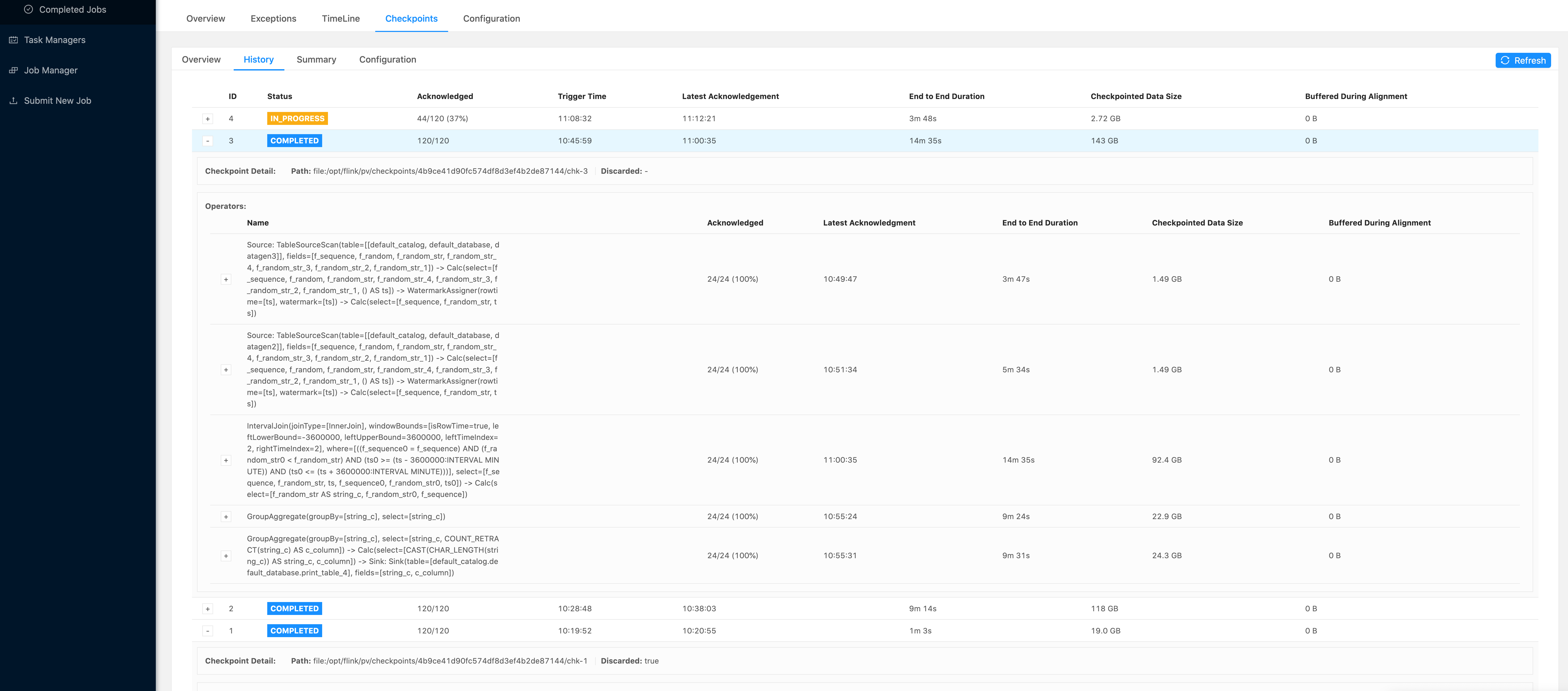
The duration of checkpoint increases due to your checkpoint size increases (from 19GB to 110GB+). I think you could click the details in the ‘interval join’ operator to see the duration and trigger time of different tasks. And the end-to-end duration of checkpoint matches as the checkpointed data size. And did you still have the problem of very large _metadata?
BTW, what I want is the JM and TM logs in detail instead of several lines of exception to see what’s your job status.
Best
Yun Tang
From: Slim Bouguerra <[hidden email]>
Date: Friday, November 20, 2020 at 5:02 AM
To: Arvid Heise <[hidden email]>
Cc: Yun Tang <[hidden email]>, "[hidden email]" <[hidden email]>
Subject: Re: Job Manager is taking very long time to finalize the Checkpointing.
sorry forgot to attach the screenshot
On Thu, Nov 19, 2020 at 12:55 PM Slim Bouguerra <[hidden email]> wrote:
@Arvid thanks will try that, The NFS server I am using should be able to have TP. In my observation the Serde is taking most of the CPU.
Please find the logs also what are your thoughts? about Source Task Data Gen is causing this aka pusing the checkpoint to JM instead of filesystem ?
The TM stacktrace https://gist.github.com/b-slim/971a069dd0754eb770d0e319a12657fb
The JM stacktrace https://gist.github.com/b-slim/24808478c3e857be563e513a3d65e223
On Thu, Nov 19, 2020 at 11:20 AM Arvid Heise <[hidden email]> wrote:
Hi Slim,
for your initial question concerning the size of _metadata. When Flink writes the checkpoint, it assumes some kind of DFS. Pretty much all known DFS implementations behave poorly for many small files. If you run a job with 5 tasks and parallelism of 120, then you'd get 600 small checkpoint files (or more depending on the configuration).
To solve it, Flink combines very small files into the _metadata according to some threshold [1]. These small files can quickly add up though. You can disable that behavior by setting the threshold to 0.
On Thu, Nov 19, 2020 at 12:57 AM Slim Bouguerra <[hidden email]> wrote:
Hi Yun,
Thanks for the help after applying your recommendation, I am getting the same issue aka very long checkpoints and then timeout
Now My guess is maybe the datagen source is pushing the checkpoint via the network to JM is there a way to double check?
IF that is the case is there a way to exclude the source operators from the checkpoints ?
Thanks
Please find the attached logs:
1 I checked the shared folder and it has the shared operator state.
2 I did set the value of fs-memory-threshold to 1kb
This the source of the SQL testing job
CREATE TABLE datagen (
f_sequence INT,
f_random INT,
f_random_str STRING,
f_random_str_4 STRING,
f_random_str_3 STRING,
f_random_str_2 STRING,
f_random_str_1 STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
-- optional options --
'rows-per-second'='500000',
'fields.f_sequence.kind'='sequence',
'fields.f_sequence.start'='1',
'fields.f_sequence.end'='200000000',
'fields.f_random.min'='1',
'fields.f_random.max'='100',
'fields.f_random_str.length'='100000',
'fields.f_random_str_4.length'='100000',
'fields.f_random_str_3.length'='100000',
'fields.f_random_str_2.length'='100000',
'fields.f_random_str_1.length'='100000'
);
---------------------------------------
With more debugging I see this exception stack on the job manager
java.io.IOException: The rpc invocation size 199965215 exceeds the maximum akka framesize.
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.createRpcInvocationMessage(AkkaInvocationHandler.java:276) [flink-dist_2.11-1.11.1.jar:1.11.1]
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.invokeRpc(AkkaInvocationHandler.java:205) [flink-dist_2.11-1.11.1.jar:1.11.1]
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.invoke(AkkaInvocationHandler.java:134) [flink-dist_2.11-1.11.1.jar:1.11.1]
at org.apache.flink.runtime.rpc.akka.FencedAkkaInvocationHandler.invoke(FencedAkkaInvocationHandler.java:79) [flink-dist_2.11-1.11.1.jar:1.11.1]
at com.sun.proxy.$Proxy25.acknowledgeCheckpoint(Unknown Source) [?:?]
at org.apache.flink.runtime.taskexecutor.rpc.RpcCheckpointResponder.acknowledgeCheckpoint(RpcCheckpointResponder.java:46) [flink-dist_2.11-1.11.1.jar:1.1
.1[]
at org.apache.flink.runtime.state.TaskStateManagerImpl.reportTaskStateSnapshots(TaskStateManagerImpl.java:117) [flink-dist_2.11-1.11.1.jar:1.11.1]
at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.reportCompletedSnapshotStates(AsyncCheckpointRunnable.java:160) [flink-dist_2.11-1.11
1.jar:1.11.1[]
at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:121) [flink-dist_2.11-1.11.1.jar:1.11.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_172]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_172]
----------------------------------------------
And sometime the JM dies with this OOM
java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3236) ~[?:1.8.0_172]
at java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:118) ~[?:1.8.0_172]
at java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:93) ~[?:1.8.0_172]
at java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:153) ~[?:1.8.0_172]
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(ObjectOutputStream.java:1877) ~[?:1.8.0_172]
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(ObjectOutputStream.java:1786) ~[?:1.8.0_172]
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1189) ~[?:1.8.0_172]
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) ~[?:1.8.0_172]
at akka.serialization.JavaSerializer$$anonfun$toBinary$1.apply$mcV$sp(Serializer.scala:324) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.serialization.JavaSerializer$$anonfun$toBinary$1.apply(Serializer.scala:324) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.serialization.JavaSerializer$$anonfun$toBinary$1.apply(Serializer.scala:324) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.serialization.JavaSerializer.toBinary(Serializer.scala:324) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.MessageSerializer$.serialize(MessageSerializer.scala:53) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter$$anonfun$serializeMessage$1.apply(Endpoint.scala:906) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter$$anonfun$serializeMessage$1.apply(Endpoint.scala:906) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter.serializeMessage(Endpoint.scala:905) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter.writeSend(Endpoint.scala:793) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter.delegate$1(Endpoint.scala:682) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter.writeLoop$1(Endpoint.scala:693) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter.sendBufferedMessages(Endpoint.scala:706) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointWriter$$anonfun$3.applyOrElse(Endpoint.scala:637) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.actor.Actor$class.aroundReceive(Actor.scala:517) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.remote.EndpointActor.aroundReceive(Endpoint.scala:458) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.actor.ActorCell.invoke(ActorCell.scala:561) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.dispatch.Mailbox.run(Mailbox.scala:225) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.dispatch.Mailbox.exec(Mailbox.scala:235) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) ~[flink-dist_2.11-1.11.1.jar:1.11.1]
On Wed, Nov 18, 2020 at 12:16 AM Yun Tang <[hidden email]> wrote:
Hi Slim
You could check the logs of taskmanager to see whether incremental checkpoint is really enabled (or you could find whether files existed under /opt/flink/pv/checkpoints/c0580ec8f55fcf1e0ceaa46fc3778b99/shared to judge).
If your configuration of rocksDB and incremental-checkpoingt is really enabled, I think the large metadata size is caused by the memory threshold [1] which will send data in bytes format back to JM directly if state handle is smaller than specific threshold.
Try to decrease this value to '1 kb' to see whether the size of meta data could also decrease.
Best
Yun Tang
From: Slim Bouguerra <[hidden email]>
Sent: Wednesday, November 18, 2020 6:16
To: [hidden email] <[hidden email]>
Subject: Job Manager is taking very long time to finalize the Checkpointing.
Originally posed to the dev list
---------- Forwarded message ---------
From: Slim Bouguerra <[hidden email]>
Date: Tue, Nov 17, 2020 at 8:09 AM
Subject: Job Manager is taking very long time to finalize the Checkpointing.
To: <[hidden email]>
Hi Devs,
I am very new to the Flink code base and working on the evaluation of the Checkpointing strategy
In my current setup I am using an NFS based file system as a checkpoint store. (NAS/NFS has a very high TP over 2GB/s on one node and I am using 12 NFS servers )
When pushing the system to some relatively medium scale aka 120 subtasks over 6 works with a total state of 100GB.
I observe that the Job manager takes over 2 minutes to finalize the checkpoint. (observed on the UI and CPU profiling of JM see the flame graph of 30 second sample)
As you can see by the attached Flames graphs the JM is very busy serializing the metadata (>org/apache/flink/runtime/checkpoint/metadata/MetadataV3Serializer.serializeOperatorState (2,875 samples, 99.65%))
Now the question is why this metadata file is so big in the order of 3GBs in my case.
How does this size scale ? num_of_tasks * num_states ?
/opt/flink/pv/checkpoints/c0580ec8f55fcf1e0ceaa46fc3778b99/chk-1
bash-4.2$ ls -all -h
-rw-r--r-- 1 flink flink 3.0G Nov 17 01:42 _metadata
The second question how to better measure the time taken by the JM to commit the transaction aka time_done_checkpoint - time_got_all_ask_form_tm
Is there a config flag I am missing to make this last step faster ?
My current configs for Checkpoints
state.backend: rocksdb
# See the PV mount path need to be the same as <mountPath: "/opt/flink/pv">
state.checkpoints.dir: file:///opt/flink/pv/checkpoints
state.savepoints.dir: file:///opt/flink/pv/savepoints
state.backend.incremental: true
# https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/config.html#checkpointing
execution.checkpointing.interval: 60000
execution.checkpointing.mode: AT_LEAST_ONCE
# hitting The rpc invocation size 19598830 exceeds the maximum akka
akka.framesize: 100485760b
# https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/config.html#heartbeat-timeout
heartbeat.timeout: 70000
# https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/config.html#execution-checkpointing-timeout
execution.checkpointing.timeout: 15minutes
some metadata about the checkpoint
{"@class":"completed","id":1,"status":"COMPLETED","is_savepoint":false,"trigger_timestamp":1605315046120,"latest_ack_timestamp":1605315093466,"state_size":12239786229,"end_to_end_duration":47346,"alignment_buffered":0,"num_subtasks":120,"num_acknowledged_subtasks":120,"tasks":{},"external_path":"file:/opt/flink/pv/checkpoints/7474752476036c14d7fdeb4e86af3638/chk-1"}
--
B-Slim
_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______
--Arvid Heise | Senior Java Developer
Follow us @VervericaData
--
Join Flink Forward - The Apache Flink Conference
Stream Processing | Event Driven | Real Time
--
Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany
--
Ververica GmbH
Registered at Amtsgericht Charlottenburg: HRB 158244 B
Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng
--
B-Slim
_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______
--
B-Slim
_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______/\/\/\_______
--
Arvid Heise | Senior Java Developer
Follow us @VervericaData
--
Join Flink Forward - The Apache Flink Conference
Stream Processing | Event Driven | Real Time
--
Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany
--
Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B
Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng
| Free forum by Nabble | Edit this page |