Memory reclaim problem on Flink Kubernetes pods
Posted by Vinay Patil on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Memory-reclaim-problem-on-Flink-Kubernetes-pods-tp37042.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Memory-reclaim-problem-on-Flink-Kubernetes-pods-tp37042.html
Hi Team,
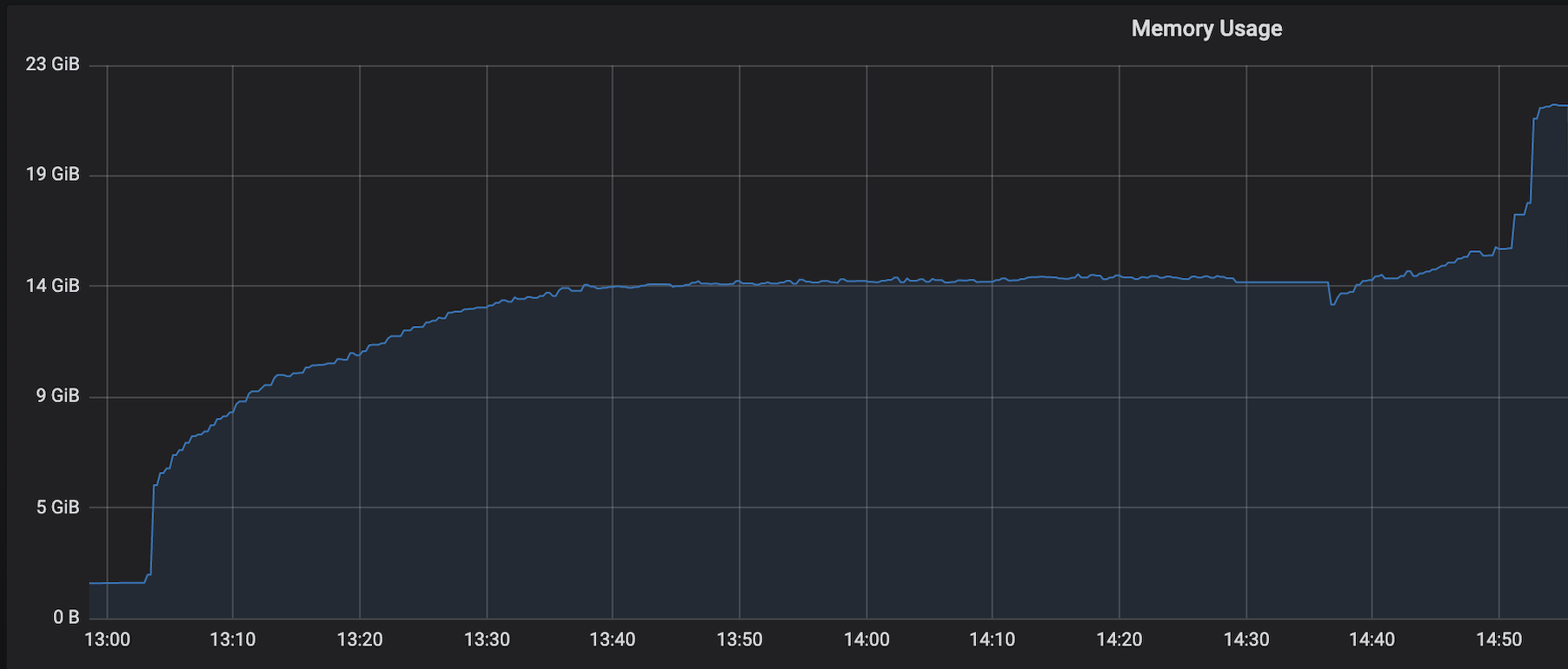
We are facing an issue where the memory is not reclaimed after the job is cancelled on the K8 session cluster, the pods were entirely used by a single job only. So, after re-submitting the same job it fails immediately. We are using RocksDb state backend where the state size is fairly small ranging from 800MB to 1GB.
Cluster Configurations: Flink 1.10.1 version
8 TM pods with 4 slots each and 16Gb per pod.
Memory Fraction ratio : 0.6
Few Observations/Concerns:
1.I have observed a weird issue where the memory usage goes beyond 16Gb for the pod , attaching a screenshot in-line.
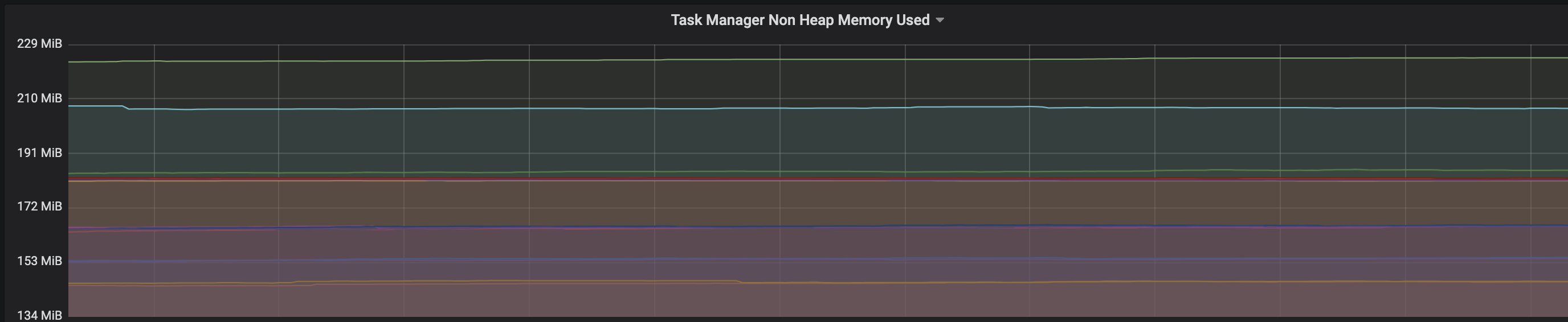
2. Plotted a graph for `flink_taskmanager_Status_JVM_Memory_NonHeap_Used` and it is under 300MB per pod
3. We thought if there is any memory leak that is causing this to happen but there is normal GC activity going on and TM heap usage is under control
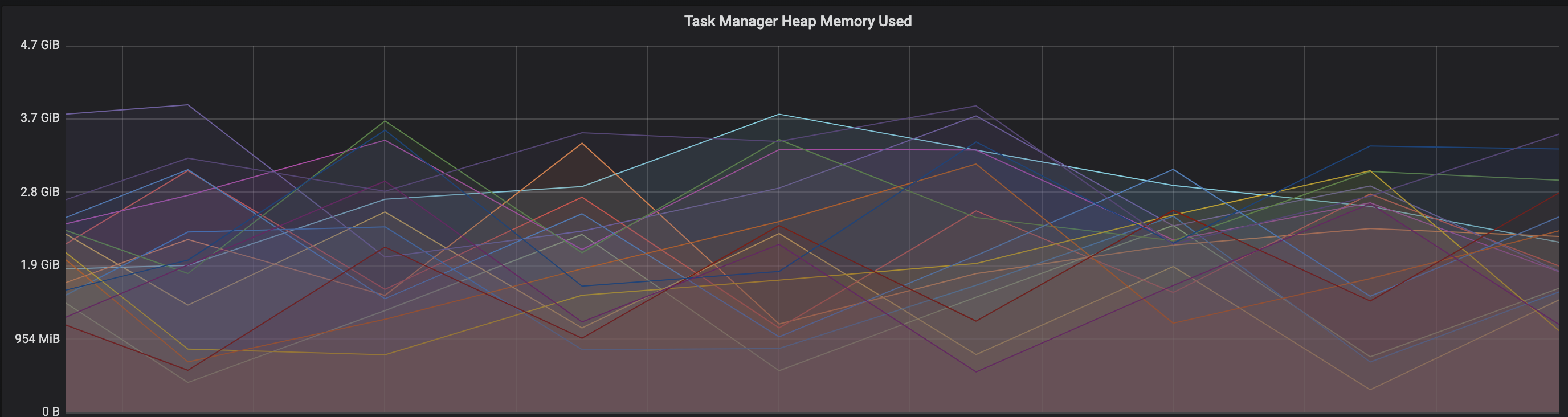
Am I missing any obvious configuration to be set ?
Regards,
Vinay Patil
| Free forum by Nabble | Edit this page |