Re: Flink 1.10.0 failover
Posted by Zhu Zhu on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Flink-1-10-0-failover-tp34695p34696.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Flink-1-10-0-failover-tp34695p34696.html
Sorry I did not quite understand the problem.
Do you mean a failed job does not release resources to yarn?
- if so, is the job in restarting process? A job in recovery will reuse the slots so they will not be release.
Or a failed job cannot acquire slots when it is restarted in auto-recovery?
- if so, normally the job should be in a loop like (restarting tasks -> allocating slots -> failed due to not be able to acquire enough slots -> restarting task -> ...). Would you check whether the job is in such a loop? Or the job cannot allocate enough slots even if the cluster has enough resource?
Thanks,
Zhu Zhu
seeksst <[hidden email]> 于2020年4月26日周日 上午11:21写道:
Hi,
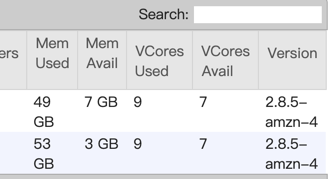
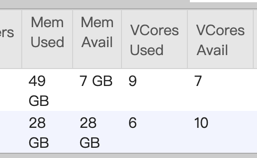
Recently, I find a problem when job failed in 1.10.0, flink didn’t release resource first.
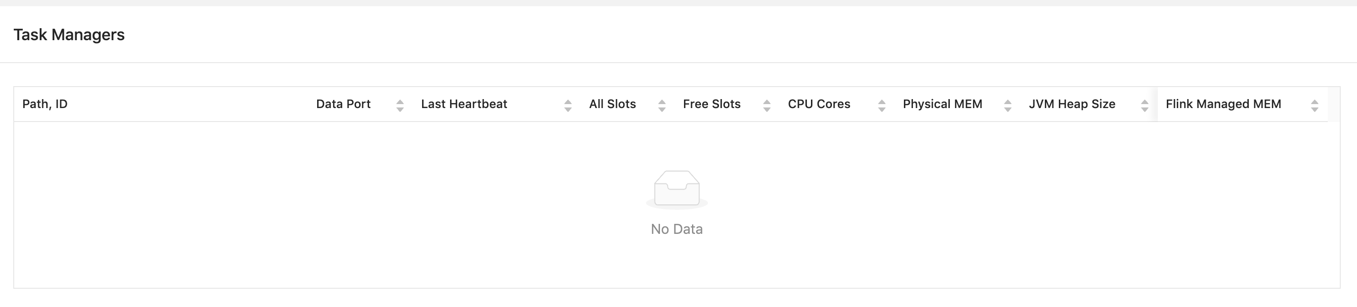
You can see I used flink on yarn, and it doesn’t allocate task manager, beacause no more memory left.
If i cancel the job, the cluster has more memory.
In 1.8.2, the job will restart normally, is this a bug?
Thanks.
| Free forum by Nabble | Edit this page |