Re: Please suggest helpful tools
Posted by Kurt Young on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Please-suggest-helpful-tools-tp32055p32143.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Please-suggest-helpful-tools-tp32055p32143.html
> but I have noticed there is no change in the list of operations with or without NOT NULL filter for JOIN keys.
I noticed that the "where" condition in these two plans are different. The without NOT NULL only has "listAgentKeyL = ucPKA" but the with NOT NULL
has "((listAgentKeyL = ucPKA) AND (...))" but truncated by the display. Could you show the full name of operators for the version which with NOT NULL?
Best,
Kurt
On Wed, Jan 15, 2020 at 2:45 AM Eva Eva <[hidden email]> wrote:
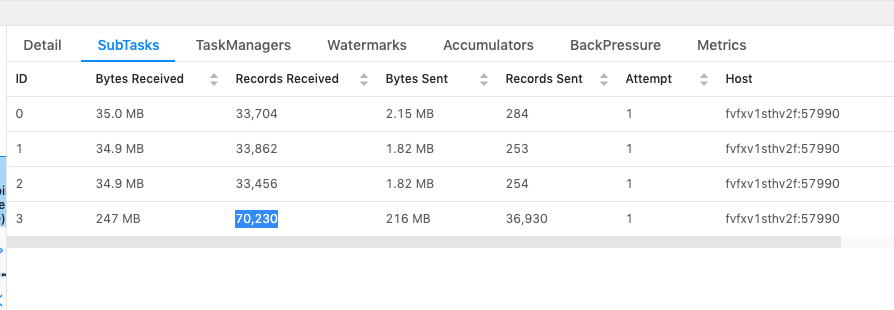
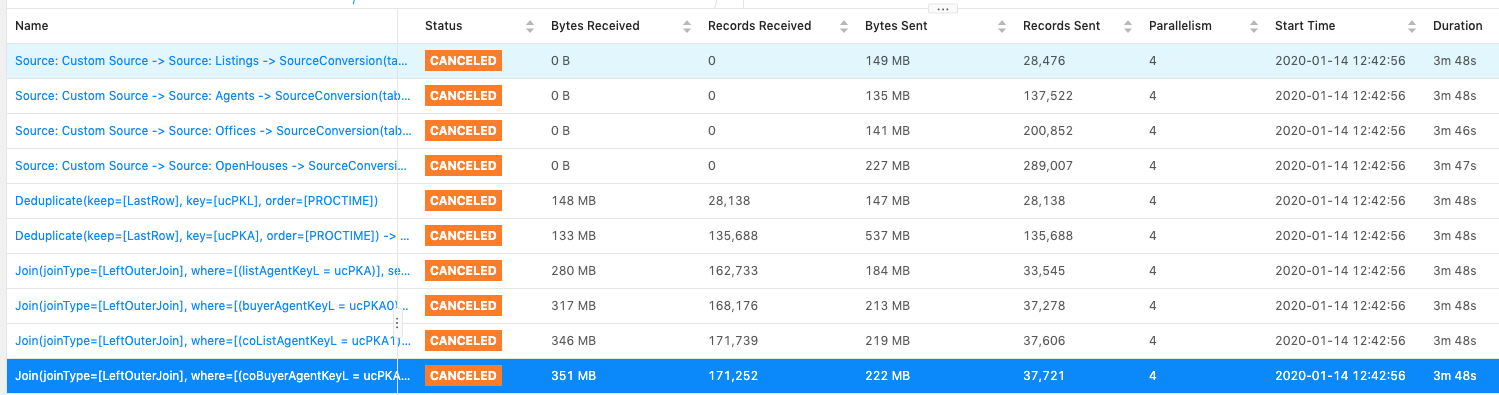
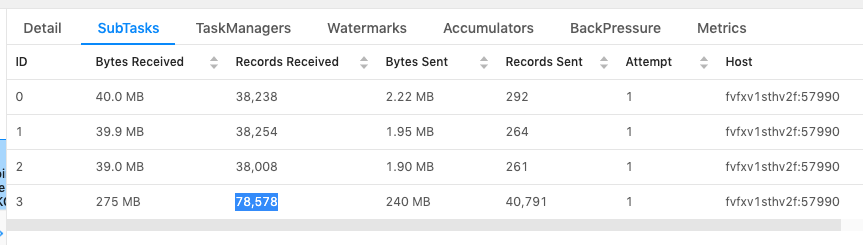
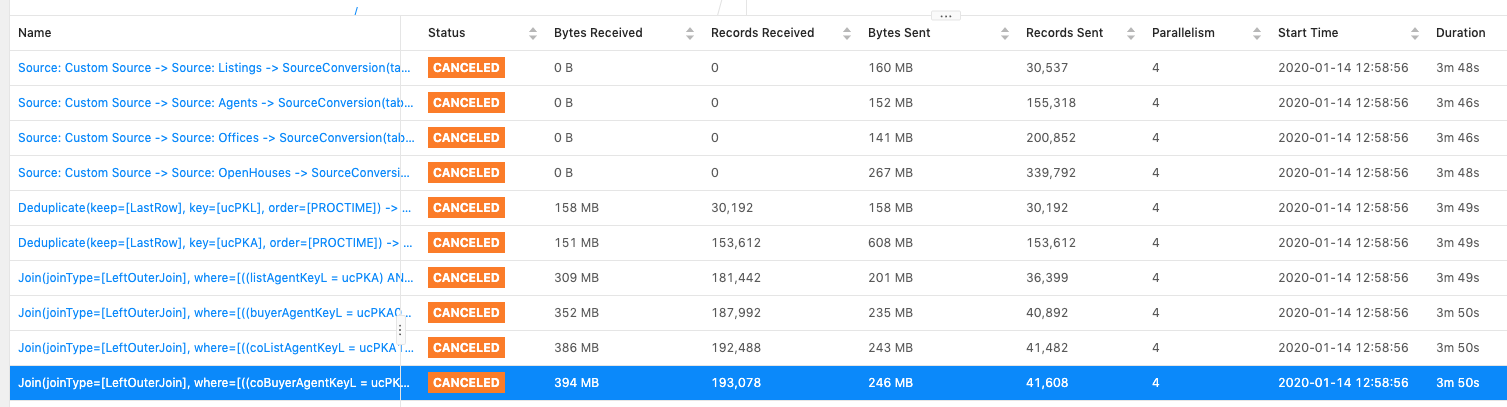
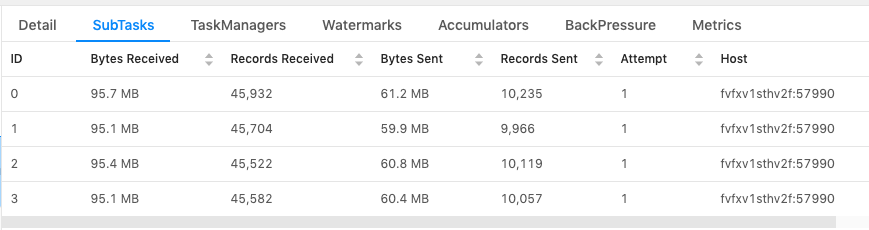
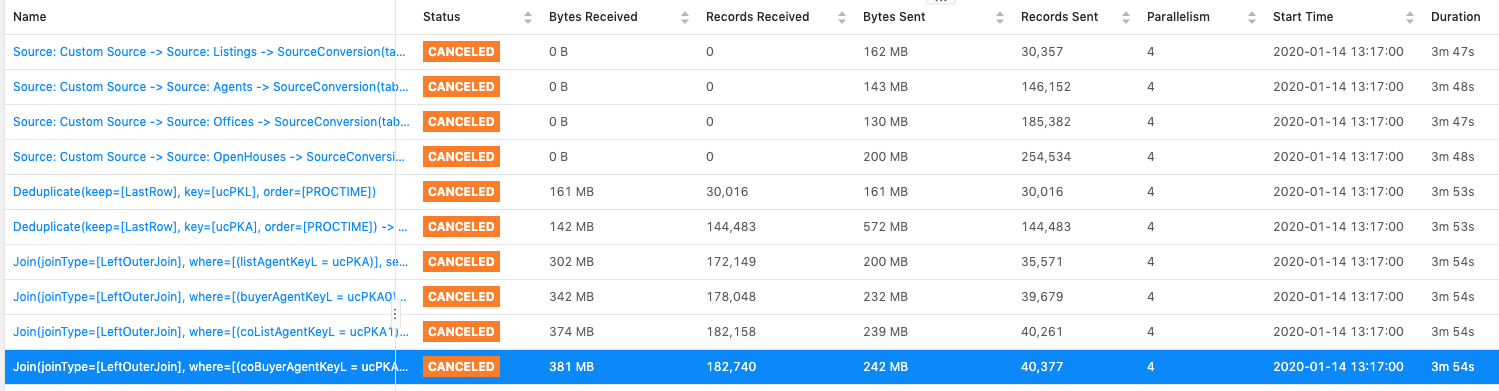
Hi Kurt,Below are the three scenarios that I tested:1. Without "NOT NULL" filter for the join key.Observation: data skew exists, as expected.Sample query:"SELECT * FROM latestListings l " +"LEFT JOIN latestAgents aa ON l.listAgentKeyL = aa.ucPKA " +
"LEFT JOIN latestAgents ab ON l.buyerAgentKeyL = ab.ucPKA " +
"LEFT JOIN latestAgents ac ON l.coListAgentKeyL = ac.ucPKA " +2. With "NOT NULL" filter for the join key.Observation: data skew exists, same as above case 1Sample query:"SELECT * FROM latestListings l " +
"LEFT JOIN latestAgents aa ON l.listAgentKeyL = aa.ucPKA AND l.listAgentKeyL IS NOT NULL " +"LEFT JOIN latestAgents ab ON l.buyerAgentKeyL = ab.ucPKA AND l.buyerAgentKeyL IS NOT NULL " +"LEFT JOIN latestAgents ac ON l.coListAgentKeyL = ac.ucPKA AND l.coListAgentKeyL IS NOT NULL" +3. I replaced all NULL values for Join keys with randomly generated values.Observation: data skew gone, absence of NULL values resulted in good data distributionI have pasted pictures to show the number of records and the list of operations.Not sure if I understood your question correctly, but I have noticed there is no change in the list of operations with or without NOT NULL filter for JOIN keys. From the task flow diagram, JOIN is kicked after DeDuplication, without any other operation in between.Thanks,EvaOn Mon, Jan 13, 2020 at 8:41 PM Kurt Young <[hidden email]> wrote:First could you check whether the added filter conditions are executed before join operators? If they arealready pushed down and executed before join, it's should be some real join keys generating data skew.Best,KurtOn Tue, Jan 14, 2020 at 5:09 AM Eva Eva <[hidden email]> wrote:Hi Kurt,Assuming I'm joining two tables, "latestListings" and "latestAgents" like below:"SELECT * FROM latestListings l " +
"LEFT JOIN latestAgents aa ON l.listAgentKeyL = aa.ucPKA " +
"LEFT JOIN latestAgents ab ON l.buyerAgentKeyL = ab.ucPKA " +
"LEFT JOIN latestAgents ac ON l.coListAgentKeyL = ac.ucPKA " +In order to avoid joining on NULL keys, are you suggesting that I change the query as below:"SELECT * FROM latestListings l " +
"LEFT JOIN latestAgents aa ON l.listAgentKeyL = aa.ucPKA AND l.listAgentKeyL IS NOT NULL " +"LEFT JOIN latestAgents ab ON l.buyerAgentKeyL = ab.ucPKA AND l.buyerAgentKeyL IS NOT NULL " +"LEFT JOIN latestAgents ac ON l.coListAgentKeyL = ac.ucPKA AND l.coListAgentKeyL IS NOT NULL" +I tried this but noticed that it didn't work as the data skew (and heavy load on one task) continued. Could you please let me know if I missed anything?Thanks,EvaOn Sun, Jan 12, 2020 at 8:44 PM Kurt Young <[hidden email]> wrote:Hi,You can try to filter NULL values with an explicit condition like "xxxx is not NULL".Best,KurtOn Sat, Jan 11, 2020 at 4:10 AM Eva Eva <[hidden email]> wrote:Thank you both for the suggestions.I did a bit more analysis using UI and identified at least one problem that's occurring with the job rn. Going to fix it first and then take it from there.Problem that I identified:I'm running with 26 parallelism. For the checkpoints that are expiring, one of a JOIN operation is finishing at 25/26 (96%) progress with corresponding SubTask:21 has "n/a" value. For the same operation I also noticed that the load is distributed poorly with heavy load being fed to SubTask:21.My guess is bunch of null values are happening for this JOIN operation and being put into the same task.Currently I'm using SQL query which gives me limited control on handling null values so I'll try to programmatically JOIN and see if I can avoid JOIN operation whenever the joining value is null. This should help with better load distribution across subtasks. And may also fix expiring checkpointing issue.Thanks for the guidance.Eva.On Fri, Jan 10, 2020 at 7:44 AM Congxian Qiu <[hidden email]> wrote:HiFor expired checkpoint, you can find something like " Checkpoint xxx of job xx expired before completing" in jobmanager.log, then you can go to the checkpoint UI to find which tasks did not ack, and go to these tasks to see what happened.If checkpoint was been declined, you can find something like "Decline checkpoint xxx by task xxx of job xxx at xxx." in jobmanager.log, in this case, you can go to the task directly to find out why the checkpoint failed.Best,CongxianYun Tang <[hidden email]> 于2020年1月10日周五 下午7:31写道:Hi Eva
If checkpoint failed, please view the web UI or jobmanager log to see why checkpoint failed, might be declined by some specific task.
If checkpoint expired, you can also access the web UI to see which tasks did not respond in time, some hot task might not be able to respond in time. Generally speaking, checkpoint expired is mostly caused by back pressure which led the checkpoint barrier did not arrive in time. Resolve the back pressure could help the checkpoint finished before timeout.
I think the doc of monitoring web UI for checkpoint [1] and back pressure [2] could help you.
[1] https://ci.apache.org/projects/flink/flink-docs-release-1.9/monitoring/checkpoint_monitoring.html
BestYun Tang
From: Eva Eva <[hidden email]>
Sent: Friday, January 10, 2020 10:29
To: user <[hidden email]>
Subject: Please suggest helpful toolsHi,
I'm running Flink job on 1.9 version with blink planner.
My checkpoints are timing out intermittently, but as state grows they are timing out more and more often eventually killing the job.
Size of the state is large with Minimum=10.2MB and Maximum=49GB (this one is accumulated due to prior failed ones), Average=8.44GB.
Although size is huge, I have enough space on EC2 instance in which I'm running job. I'm using RocksDB for checkpointing.
Logs does not have any useful information to understand why checkpoints are expiring/failing, can someone please point me to tools that can be used to investigate and understand why checkpoints are failing.
Also any other related suggestions are welcome.
Thanks,Reva.
| Free forum by Nabble | Edit this page |