<Need help>The processing of flink sql is slow,how to accelerate it?
Posted by wydhcws@gmail.com on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Need-help-The-processing-of-flink-sql-is-slow-how-to-accelerate-it-tp31370.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Need-help-The-processing-of-flink-sql-is-slow-how-to-accelerate-it-tp31370.html
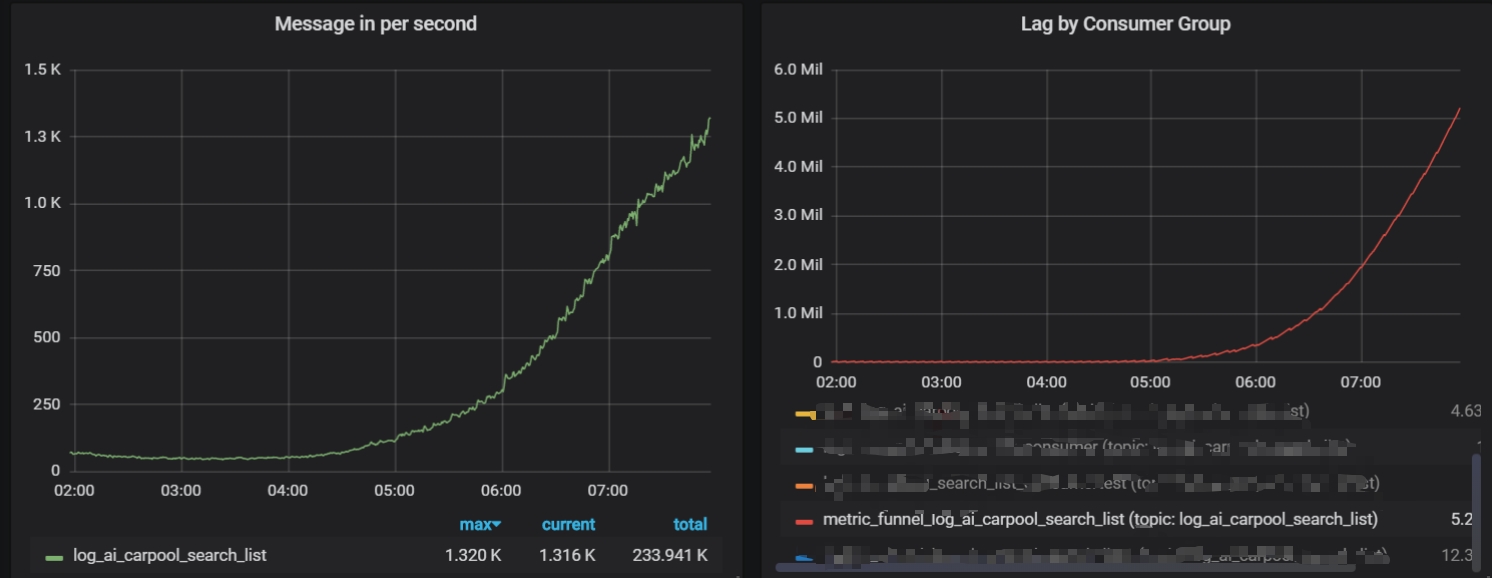
Hi all,I wrote some indicator calculation programs using flink sql, and read the data from kafka and send to influxdb after processing by flinksql. I found that when the Kafka log production speed is 10 k / min at night, there is no problem with the program, but it gradually increases to 100k / min during the day ,It became difficult for KafkaConsumer to consume data, using flink 1.9, now I feel that the layer of Flink sql execution is a bit slow, the window is scrolling for 5 minutes, currently using two solts, increasing the parallelism and tried it has no effect, Is there any solution for this? Thank you for everyone
code show as below:
val windowWidth = 5
//stream config
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(1000 * 60*5)
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
env.getCheckpointConfig.setCheckpointTimeout(60000*10)
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION)
// env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//table config
val tEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
tEnv.getConfig.setIdleStateRetentionTime(Time.minutes(1), Time.minutes(10))
tEnv.registerFunction("TimeFormatJava", new TimeFormatJava())
tEnv.registerFunction("TimeFormatUDF", TimeFormatUDF)
//Kafka Source
val kafkaProperties: Properties = new Properties
kafkaProperties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServers)
kafkaProperties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId)
kafkaProperties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"5000")
kafkaProperties.setProperty(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,"500")
var topics: util.List[String] = new util.ArrayList[String]
for (topic <- kafkaTopics.split(SPLIT)) {
topics.add(topic)
}
val kafkaConsumer: FlinkKafkaConsumer011[String] = new FlinkKafkaConsumer011[String](topics, new SimpleStringSchema, kafkaProperties)
val driverSearchDstream: DataStream[DriverSearch] = env.addSource(kafkaConsumer.setStartFromLatest()).map(msg => {
val info: String = msg.substring(msg.indexOf("{"), msg.length)
val createTime = msg.substring(0, 19)
val timeStamp = getLongTime(createTime)
val json = JSON.parseObject(info)
DriverSearch(
json.getString("driverId") + "_" + timeStamp,
json.getString("driverId"),
json.getIntValue("searchType"),
timeStamp
)
}).setParallelism(2)
val driverSearchDstreamWithEventTime: DataStream[DriverSearch] = driverSearchDstream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[DriverSearch](org.apache.flink.streaming.api.windowing.time.Time.seconds(10L)) {
override def extractTimestamp(element: DriverSearch): Long = element.timestamp
}
)
driverSearchDstream.map(info=>println(info+"time:"+System.currentTimeMillis()))
val table: Table = tEnv.fromDataStream(driverSearchDstreamWithEventTime, 'rowKey, 'driverId, 'searchType, 'timestamp.rowtime as 'w)
val sql1: String =
s"""
select TimeFormatJava(TUMBLE_END(w, INTERVAL '$windowWidth' MINUTE),8) as time_end,
searchType,
count(distinct driverId) as typeUv,
count(distinct rowKey) as typePv
from $table
group by TUMBLE(w, INTERVAL '$windowWidth' MINUTE),searchType
""".stripMargin
val resultTable1: Table = tEnv.sqlQuery(sql1)
val typeMap= immutable.Map(1->"1-goWorkSearch",2->"2-offWorkSearch",3->"3-nearbySearch",4->"4-temporarySearch",5->"5-commonSearch",6->"6-multiplySearch")
val influxStream: DataStream[InfluxDBPoint] = tEnv.toAppendStream[Row](resultTable1).map {
row => {
val typeName: String= typeMap(row.getField(1).asInstanceOf[Int])
val point = new InfluxDBPoint("Carpool_Search_Pv_Uv", row.getField(0).asInstanceOf[Long]) //udf +8hour
val fields = new util.HashMap[String,Object]()
val tags = new util.HashMap[String,String]()
fields.put("typeUv", row.getField(2))
fields.put("typePv",row.getField(3))
point.setFields(fields)
tags.put("typeName",typeName)
point.setTags(tags)
point
}
}
influxStream.map{
point=>{
println( println("influxPoint:"+point.getFields+"=="
+point.getTags+"=="+point.getMeasurement
+"=="+point.getTimestamp+"time:"+System.currentTimeMillis())
)
}
}
val influxDBConfig = InfluxDBConfig.builder("http://host:8086", "admin", "admin", "aimetric").build
influxStream.addSink(new InfluxDBSink(influxDBConfig))
env.execute()
}
def getLongTime(str:String) ={
val format = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss")
val time: Long = format.parse(str).getTime
time
| Free forum by Nabble | Edit this page |