Re: About exactly once question?
Posted by Stephan Ewen on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/About-exactly-once-question-tp2545p2547.html
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/About-exactly-once-question-tp2545p2547.html
Hi!
The "exactly once" guarantees refer to the state in Flink. It means that any aggregates and any user-defined state will see each element once.
This guarantee does not automatically translate to the outputs to the outside world, as Marton said. Exactly once output is only possible (in general and in all streaming systems) if the target in the outside world cooperates.
The outside world can either participate via integrating transactionally with the checkpointing (this is the plan for JDBC sinks and future versions of Kafka), or by de-duplicating via keys (Elastic search sink).
We are currently adding some more data sinks that cooperate with the checkpointing mechanism (for example file systems, HDFS) so that end-to-end exactly once will work seamlessly with those.
Greetings,
Stephan
Stephan
On Thu, Aug 27, 2015 at 1:14 PM, Márton Balassi <[hidden email]> wrote:
Dear Zhangrucong,From your explanation it seems that you have a good general understanding of Flink's checkpointing algorithm. Your concern is valid, by default a sink C with emits tuples to the "outside world" potentially multiple times. A neat trick to solve this issue for your user defined sinks is to use the CheckpointNotifier interface to output records only after the corresponding checkpoint has been totally processed by the system, so sinks can also provid exactly once guarantees in Flink.This would mean that your SinkFunction has to implement both the Checkpointed and the CheckpointNotifier interfaces. The idea is to mark the output tuples with the correspoding checkpoint id, so then they can be emitted in a "consistent" manner when the checkpoint is globally acknowledged by the system. You buffer your output records in a collection of your choice and whenever a snapshotState of the Checkpointed interface is invoked you mark your fresh output records with the current checkpointID. Whenever the notifyCheckpointComplete is invoked you emit records with the corresponding ID.Note that this adds latency to your processing and as you potentially need to checkpoint a lot of data in the sinks I would recommend to use a HDFS as a state backend instead of the default solution.Best,MartonOn Thu, Aug 27, 2015 at 12:32 PM, Zhangrucong <[hidden email]> wrote:Hi:
The document said Flink can guarantee processing each tuple exactly-once, but I can not understand how it works.
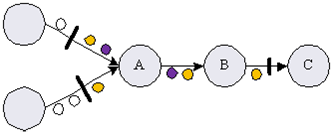
For example, In Fig 1, C is running between snapshot n-1 and snapshot n(snapshot n hasn’t been generated). After snapshot n-1, C has processed tuple x1, x2, x3 and already outputted to user, then C failed and it recoveries from snapshot n-1. In my opinion, x1, x2, x3 will be processed and outputted to user again. My question is how Flink guarantee x1,x2,x3 are processed and outputted to user only once?
Fig 1.
Thanks for answing.
| Free forum by Nabble | Edit this page |