checkpoint stuck with rocksdb statebackend and s3 filesystem
Posted by Tony Wei on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/checkpoint-stuck-with-rocksdb-statebackend-and-s3-filesystem-tp18679.html
 bad_tm_log.log (5M) Download Attachment
bad_tm_log.log (5M) Download Attachment
bad_tm_pic.png (292K) Download Attachment
bad_tm_stack.log (198K) Download Attachment
good_tm_log.log (4M) Download Attachment
good_tm_pic.png (188K) Download Attachment
good_tm_stack.log (140K) Download Attachment
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/checkpoint-stuck-with-rocksdb-statebackend-and-s3-filesystem-tp18679.html
Hi all,
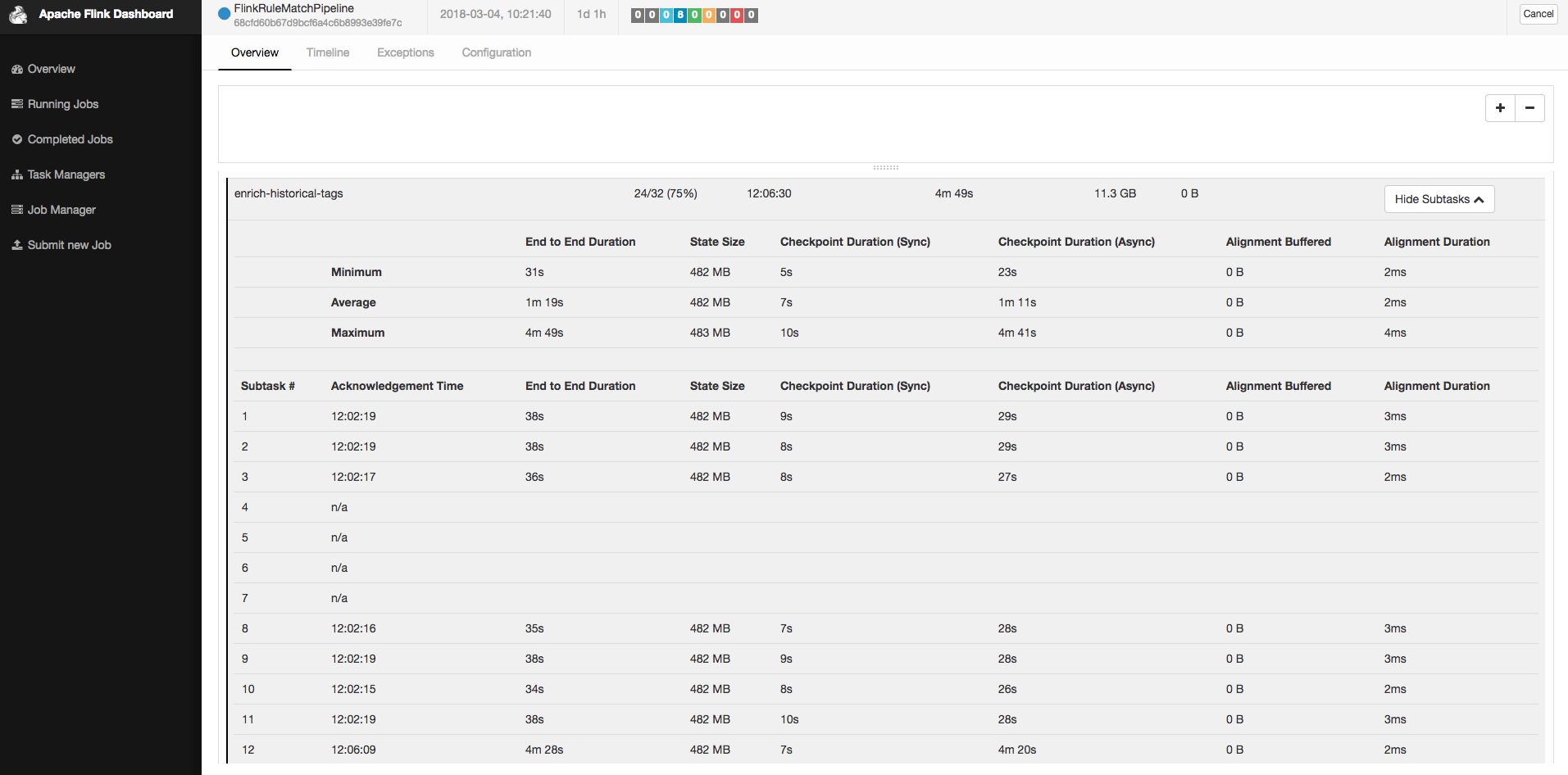
Last weekend, my flink job's checkpoint start failing because of timeout. I have no idea what happened, but I collect some informations about my cluster and job. Hope someone can give me advices or hints about the problem that I encountered.
My cluster version is flink-release-1.4.0. Cluster has 10 TMs, each has 4 cores. These machines are ec2 spot instances. The job's parallelism is set as 32, using rocksdb as state backend and s3 presto as checkpoint file system.
The state's size is nearly 15gb and still grows day-by-day. Normally, It takes 1.5 mins to finish the whole checkpoint process. The timeout configuration is set as 10 mins.
As the picture shows, not each subtask of checkpoint broke caused by timeout, but each machine has ever broken for all its subtasks during last weekend. Some machines recovered by themselves and some machines recovered after I restarted them.
I record logs, stack trace and snapshot for machine's status (CPU, IO, Network, etc.) for both good and bad machine. If there is a need for more informations, please let me know. Thanks in advance.
Best Regards,
Tony Wei.
| Free forum by Nabble | Edit this page |