Spread Kafka sink tasks over different nodes
Posted by Dongwon Kim-2 on
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Spread-Kafka-sink-tasks-over-different-nodes-tp18652.html
We have a standalone cluster where 1 JM and 7 TMs are running on 8 servers.
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/Spread-Kafka-sink-tasks-over-different-nodes-tp18652.html
Hi,
We have total 224 cores (as each TM has 32 slots) and we want to use all slots for a single streaming job.
The single job roughly consists of the following three types of tasks:
- Kafka source tasks (Parallelism : 7 as the number of partitions in the input topic is 7)
- Session window tasks (Parallelism : 224)
- Kafka sink tasks (Parallelism : 7 as the number of partitions in the output topic is 7)
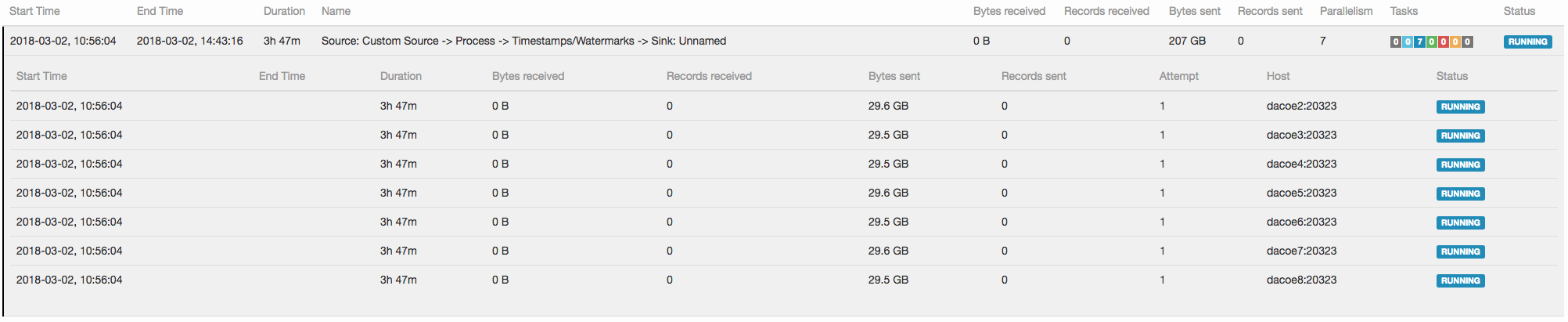
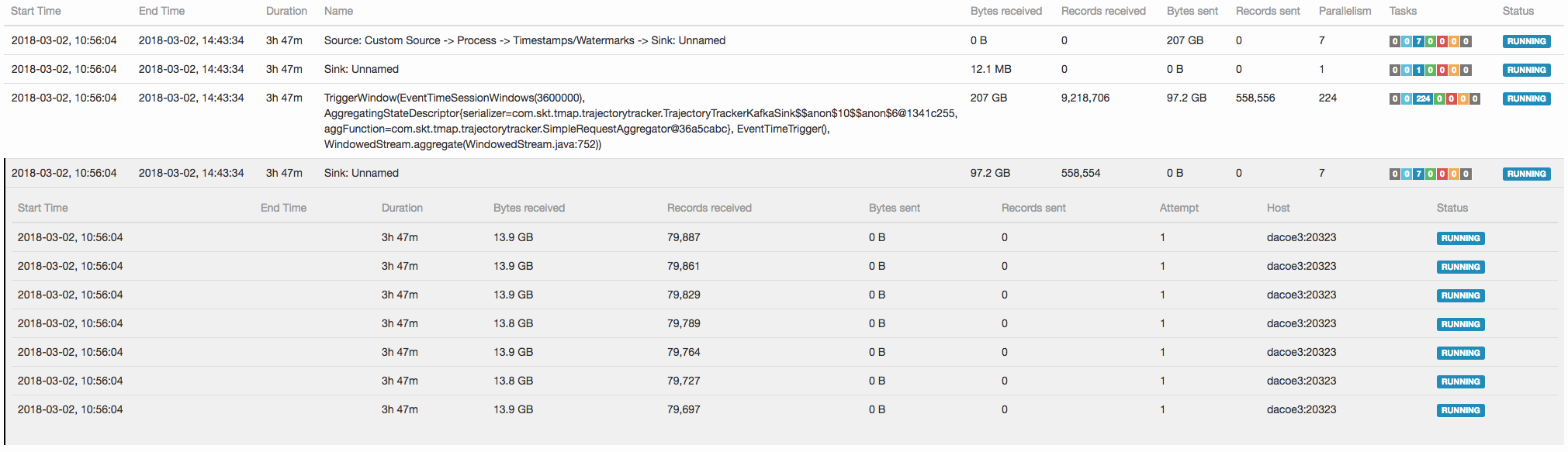
We want 7 sources and 7 sinks to be evenly scheduled over different nodes.
Source tasks are scheduled as wanted (see "1 source.png").
However, sink tasks are scheduled on a single node (see "2 sink.png").
As we use the whole standalone only for a single job, this scheduling behavior causes the output of all the 224 session window tasks to be sent to a single physical machine.
Is it because locality is only considered in Kafka source?
I also check that different partitions are taken care by different brokers for both of the input topic and the output topic in Kafka.
Do I miss something in order to spread Kafka sink tasks over different nodes?
Best,
- Dongwon
| Free forum by Nabble | Edit this page |