Re: does flink support yarn/hdfs HA?
URL: http://deprecated-apache-flink-user-mailing-list-archive.369.s1.nabble.com/does-flink-support-yarn-hdfs-HA-tp16448p16512.html
Hi,
I think you only have to add /data/hadoop/etc/hadoop/ to the classpath and not the individual files. Could you try this out?
Cheers,
Till
Have add *-site.xml to yarn.application.classpath,please see the attached file. But still encount the same issue(ie. can't read yarn-site.xml in YarnConfiguration). Can it be possible load yarn-site.xml in HadoopUtils.java? Thus we can ignore yarn.application.classpath. ------------------------------------------------------------ ------ 发件人:Till Rohrmann <[hidden email]>发送时间:2017年11月1日(星期三) 22:41收件人:邓俊华 <[hidden email]>抄 送:Stephan Ewen <[hidden email]>; user <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?Yes, changing the
yarn.application.classpathinyarn-site.xmlwithout including theHADOOP_CONF_DIRcauses the problem. You can see the respective code hereUtils#setupYarnClassPath(Utils.java#106, the one in the module flink-yarn).I’m not entirely sure what the idiomatic Yarn way would be either including HADOOP_CONF_DIR in the classpath and assuming that all resources must be accessible from there or to allow explicit lookup of configuration files. My gut feeling is that it shouldn’t hurt to add the explicit resource loading. However, it could lead to the situation that people unknowingly load a configuration file which they thought would be read from the classpath, because the explicit loading would override the classpath resource. Not sure whether this is an issue.
Cheers,
TillOn Wed, Nov 1, 2017 at 2:45 PM, 邓俊华 <[hidden email]> wrote:HADOOP_CONF_DIR has been set in /etc/profile and can be get in ·env·.I truely set yarn.application.classpath in yarn-site.xml but not include hadoop conf dir in it,does is make the issues?------------------------------------------------------------ ------ 发件人:Till Rohrmann <[hidden email]>发送时间:2017年11月1日(星期三) 20:25收件人:邓俊华 <[hidden email]>抄 送:Stephan Ewen <[hidden email]>; user <[hidden email]>; 黄亮 <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?Quick question,
did you configure the
application.classpathin your Yarn configuration? The reason I’m asking is that theAbstractYarnDescriptorsets up the Yarn classpath and ifapplication.classpathis not configured, then it adds theHADOOP_CONF_DIRpath to the classpath. If you check the classpath which you’ve sent me, then you’ll see that the expanded HADOOP_CONF_DIR is not part of it. That either means that HADOOP_CONF_DIR has not been set for the user starting the Yarn session or that there is maybe theapplication.classpathconfigured.Cheers,
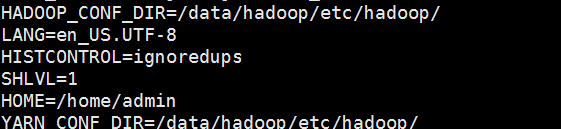
TillOn Wed, Nov 1, 2017 at 9:58 AM, 邓俊华 <[hidden email]> wrote:hi,When I use "new YarnConfiguration(HadoopUtils. getHadoopConfiguration())" in flink-1.3.2,I can't get yarn-site.xml property. So I get it from HadoopUtils. getHadoopConfiguration(). The attached file is the bin/yarn-session.sh classpath. And the HADOOP_CONF_DIR/YARN_CONF_DIR as below, I am sure there are *-site.xml.------------------------------------------------------------ ------ 发件人:Till Rohrmann <[hidden email]>发送时间:2017年11月1日(星期三) 16:32收件人:邓俊华 <[hidden email]>抄 送:Stephan Ewen <[hidden email]>; user <[hidden email]>; 黄亮 <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?Hi,
thanks for looking into the problem. I actually opened a PR [1] for fixing this but it does not include the changes to
HadoopUtilsand, thus, does not solve the problem entirely.I’m wondering why you have to add explicitly the
yarn-site.xml. TheYarnConfigurationshould add theyarn-site.xmlas a default resource which is extracted from the classpath. Could you share the classpath of the launched YarnJobManager (you find it a the top of the YarnJobManager logs). Also it would be interesting to see whatHADOOP_CONF_DIRis actually pointing to. The reason I’m asking is thatHADOOP_CONF_DIRshould be included in the classpath of the launched application master.[1] https://github.com/apache/
flink/pull/4926 Cheers,
TillOn Tue, Oct 31, 2017 at 7:11 AM, 邓俊华 <[hidden email]> wrote:hi Till,The issue can be fixed by the below solution.In org.apache.flink.yarnYarnApplicationMasterRunner.java :replace "final YarnConfigurationyarnConfig = new YarnConfiguration();" with "final YarnConfiguration yarnConfig = new YarnConfiguration(HadoopUtils. getHadoopConfiguration());" In org.apache.flink.runtime.util.HadoopUtils.java: add the below code in getHadoopConfiguration()if (new File(possibleHadoopConfPath + "/ yarn-site.xml").exists()) {
retConf.addResource(neworg.apache.hadoop.fs.Path( possibleHadoopConfPath + "/ yarn-site.xml"));
if (LOG.isDebugEnabled()) {
LOG.debug("Adding " +possibleHadoopConfPath + "/ yarn-site.xml to hadoop configuration");
}
}I am using flink-1.3.2 and I also find it happened in flink-1.4-snapshot. Hope it won't happened in new realease.------------------------------------------------------------ 发件人:邓俊华 <[hidden email]>发送时间:2017年10月31日(星期二) 11:16收件人:Till Rohrmann <[hidden email]>抄 送:Stephan Ewen <[hidden email]>; user <[hidden email]>; 黄亮 <[hidden email]>主 题:回复:does flink support yarn/hdfs HA?hi Till,I have a test with the solution you provide. But it didn't fix the issue.1> There is no 'org.apache.flink.runtime.util.HadoopUtils' in flink-1.3.2,it's in flink-1.4.0-snapshot. It can't change to final YarnConfiguration yarnConfig = new YarnConfiguration(org.apache.flink.runtime.util. .HadoopUtils.HadoopUtils getHadoopConfiguration( flinkConfiguration)); to fix the issue. 2> There is another api ''org.apache.flink.api.java.hadoop.mapred.utils. HadoopUtils" to get hdfs-site.xml and core-site.xml. So I changed to as below: final YarnConfiguration yarnConfig = new YarnConfiguration(org.apache.flink.api.java.hadoop.mapred. .utils.HadoopUtils getHadoopConfiguration()); It truelly can read hdfs/core file,but it can't read yarn-site.xml now.So can I think flink doesn't support yarn/hdfs HA for now? It support the default configuration for yarn and can't read the yarn conf with custom configuration?2017-10-31 11:14:12,860 DEBUG org.apache.hadoop.ipc.Client - IPC Client <a href="tel:(209)%20645-0263" target="_blank">(2096450263) connection to spark2/174.18.4.205:9000 from admin: stopped, remaining connections 12017-10-31 11:14:13,259 INFO org.apache.flink.yarn.YarnJobManager - Attempting to recover all jobs.2017-10-31 11:14:13,260 DEBUG org.apache.flink.runtime. jobmanager. ZooKeeperSubmittedJobGraphStor e - Retrieving all stored job ids from ZooKeeper under flink/application_ 1508845594022_0020/jobgraphs. 2017-10-31 11:14:13,261 DEBUG org.apache.zookeeper. ClientCnxn - Reading reply sessionid:0x15cf415d94c00ee, packet:: clientPath:null serverPath:null finished:false header:: 55,3 replyHeader:: 55,8592068434,0 request:: '/flink/application_ 1508845594022_0020/jobgraphs,F response:: s{8592068425,8592068425, 1509419643087,1509419643087,0, 0,0,0,0,0,8592068425} 2017-10-31 11:14:13,263 DEBUG org.apache.zookeeper. ClientCnxn - Reading reply sessionid:0x15cf415d94c00ee, packet:: clientPath:null serverPath:null finished:false header:: 56,12 replyHeader:: 56,8592068434,0 request:: '/flink/application_ 1508845594022_0020/jobgraphs,F response:: v{},s{8592068425,8592068425, 1509419643087,1509419643087,0, 0,0,0,0,0,8592068425} 2017-10-31 11:14:13,264 INFO org.apache.flink.yarn. YarnJobManager - There are no jobs to recover.2017-10-31 11:14:13,487 INFO org.apache.hadoop.ipc.Client - Retrying connect to server: 0.0.0.0/0.0.0.0:8030. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixed Sleep(maxRetries=10, sleepTime=1000 MILLISECONDS)2017-10-31 11:14:13,489 DEBUG org.apache.hadoop.ipc.Client - closing ipc connection to 0.0.0.0/0.0.0.0:8030: Connection refusedjava.net. ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl. checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl. finishConnect( SocketChannelImpl.java:744) at org.apache.hadoop.net. SocketIOWithTimeout.connect( SocketIOWithTimeout.java:206) at org.apache.hadoop.net. NetUtils.connect(NetUtils. java:531) at org.apache.hadoop.net. NetUtils.connect(NetUtils. java:495) at org.apache.hadoop.ipc.Client$ Connection.setupConnection( Client.java:614) at org.apache.hadoop.ipc.Client$ Connection.setupIOstreams( Client.java:712) at org.apache.hadoop.ipc.Client$ Connection.access$2900(Client. java:375) at org.apache.hadoop.ipc.Client. getConnection(Client.java: 1528) at org.apache.hadoop.ipc.Client. call(Client.java:1451) at org.apache.hadoop.ipc.Client. call(Client.java:1412) at org.apache.hadoop.ipc. ProtobufRpcEngine$Invoker. invoke(ProtobufRpcEngine.java: 229) at com.sun.proxy.$Proxy15. registerApplicationMaster( Unknown Source) at org.apache.hadoop.yarn.api. impl.pb.client. ApplicationMasterProtocolPBCli entImpl. registerApplicationMaster( ApplicationMasterProtocolPBCli entImpl.java:107) ------------------------------------------------------------ ------ 发件人:Till Rohrmann <[hidden email]>发送时间:2017年10月27日(星期五) 20:24收件人:邓俊华 <[hidden email]>抄 送:Stephan Ewen <[hidden email]>; user <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?Hi,
looking at the code, the
YarnConfigurationonly loads thecore-site.xmland theyarn-site.xmland does not load thehdfs-site.xml. This seems to be on purpose and, thus, we should try to add it. I think the solution could be as easy asfinal YarnConfiguration yarnConfig = new YarnConfiguration(HadoopUtils.getHadoopConfiguration( flinkConfiguration)); Do you want to open a JIRA issue and a PR for this issue?
Cheers,
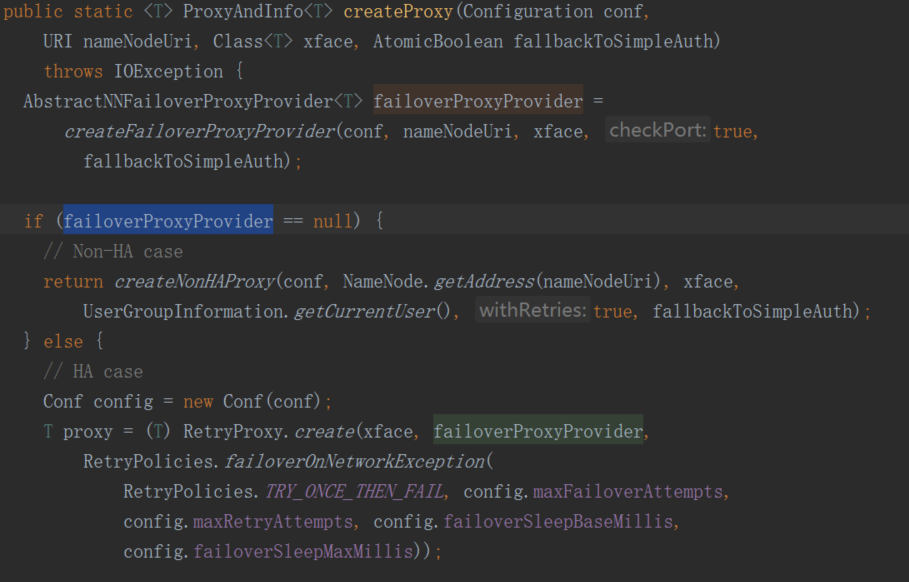
TillOn Fri, Oct 27, 2017 at 1:59 PM, 邓俊华 <[hidden email]> wrote:it pass the "final YarnConfigurationyarnConfig = new YarnConfiguration();" in https://github.com/apache/ flink/blob/master/flink-yarn/ not the conf in https://github.com/apache/src/main/java/org/apache/ flink/yarn/ YarnApplicationMasterRunner. java flink/blob/master/flink- ;filesystems/flink-hadoop-fs/ src/main/java/org/apache/ flink/runtime/util/ HadoopUtils.java See------------------------------------------------------------ ------ 发件人:Stephan Ewen <[hidden email]>发送时间:2017年10月27日(星期五) 19:50收件人:邓俊华 <[hidden email]>抄 送:user <[hidden email]>; Stephan Ewen <[hidden email]>; Till Rohrmann <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?The it should probably work to apply a similar logic to the YarnConfiguration loading as to the Hadoop Filesystem configuration loading in https://github.com/apache/flink/blob/master/flink- filesystems/flink-hadoop-fs/ src/main/java/org/apache/ flink/runtime/util/ HadoopUtils.java On Fri, Oct 27, 2017 at 1:42 PM, 邓俊华 <[hidden email]> wrote:Yes, every yarn cluster node has *-site.xml and YARN_CONF_DIR and HADOOP_CONF_DIR be configured in every yarn cluster node.------------------------------------------------------------ ------ 发件人:Stephan Ewen <[hidden email]>发送时间:2017年10月27日(星期五) 19:38收件人:user <[hidden email]>抄 送:邓俊华 <[hidden email]>; Till Rohrmann <[hidden email]>主 题:Re: does flink support yarn/hdfs HA?Hi!The HDFS config resolution logic is in [1]. It should take the environment variable into account.The problem (bug) seems to be that in the Yarn Utils, the configuration used for Yarn (AppMaster) loads purely from classpath, not from the environment variables.And that classpath does not include the proper hdfs-site.xml.Now, there are two ways I could imagine fixing that:(1) When instantiating the Yarn Configuration, also add resources from the environment variable as in [1].(2) The client (which puts together all the resources that should be in the classpath of the processes running on Yarn needs to add hadoop these config files to the resources.Are the environment variables YARN_CONF_DIR and HADOOP_CONF_DIR typically defined on the nodes of a Yarn cluster?StephanOn Fri, Oct 27, 2017 at 12:38 PM, 邓俊华 <[hidden email]> wrote:hi,Now I run spark streming on yarn with yarn/HA. I want to migrate spark streaming to flink. But it can't work. It can't conncet to hdfs logical namenode url.It always throws exception as fllow. I tried to trace the flink code and I found there maybe something wrong when read the hadoop conf.As fllow, code the failoverProxyProvider is null , so it think it's a No-HA case. The YarnConfiguration didn't read hdfs-site.xml to get "dfs.client.failover.proxy.provider.startdt" value,only yarn-site.xml and core-site.xml be read. I have configured and export YARN_CONF_DIR and HADOOP_CONF_DIR in /etc/profile and I am sure there are *-site.xml in this diretory. I can also get the value in env.Can anybody provide me some advice?2017-10-25 21:02:14,721 DEBUGorg.apache.hadoop.hdfs. BlockReaderLocal - dfs.domain.socket. path =
2017-10-25 21:02:14,755 ERRORorg.apache.flink.yarn. YarnApplicationMasterRunner - YARN Application Master initialization failed
java.lang.IllegalArgumentException: java.net.UnknownHostException: startdt
at org.apache.hadoop.security.SecurityUtil. buildTokenService( SecurityUtil.java:378)
at org.apache.hadoop.hdfs.NameNodeProxies. createNonHAProxy( NameNodeProxies.java:310)
at org.apache.hadoop.hdfs.NameNodeProxies. createProxy(NameNodeProxies. java:176)
at org.apache.hadoop.hdfs.DFSClient.<init>( DFSClient.java:678)
at org.apache.hadoop.hdfs.DFSClient.<init>( DFSClient.java:619)
at org.apache.hadoop.hdfs.DistributedFileSystem. initialize( DistributedFileSystem.java: 149)
at org.apache.hadoop.fs.FileSystem. createFileSystem(FileSystem. java:2669)
at org.apache.hadoop.fs.FileSystem.access$200( FileSystem.java:94)
at org.apache.hadoop.fs.FileSystem$Cache. getInternal(FileSystem.java: 2703)
at org.apache.hadoop.fs.FileSystem$Cache.get( FileSystem.java:2685)
at org.apache.hadoop.fs.FileSystem.get(FileSystem. java:373)
at org.apache.hadoop.fs.Path.getFileSystem(Path. java:295)
at org.apache.flink.yarn.Utils. createTaskExecutorContext( Utils.java:385)
at org.apache.flink.yarn. YarnApplicationMasterRunner. runApplicationMaster( YarnApplicationMasterRunner. java:324)
at org.apache.flink.yarn. YarnApplicationMasterRunner$1. call( YarnApplicationMasterRunner. java:195)
at org.apache.flink.yarn. YarnApplicationMasterRunner$1. call( YarnApplicationMasterRunner. java:192)
at org.apache.flink.runtime.security. HadoopSecurityContext$1.run( HadoopSecurityContext.java:43)
at java.security.AccessController.doPrivileged( Native Method)
at javax.security.auth.Subject.doAs(Subject. java:415)
at org.apache.hadoop.security.UserGroupInformation. <a href="tel:1698" style="color:#000000;font-family:Tahoma,Arial;font-size:14.0px;font-style:normal;font-variant:normal;font-weight:normal;text-transform:none" target="_blank">1698)doAs(UserGroupInformation. java:
at org.apache.flink.runtime.security. HadoopSecurityContext. runSecured( HadoopSecurityContext.java:40)
at org.apache.flink.yarn. YarnApplicationMasterRunner. run( YarnApplicationMasterRunner. java:192)
at org.apache.flink.yarn. YarnApplicationMasterRunner. main( YarnApplicationMasterRunner. java:116)
Caused by: java.net.UnknownHostException: startdt
... 23 more




| Free forum by Nabble | Edit this page |