questions about YARN deployment and HDFS integration


|
Dear All,
I am helping my team setup a Flink cluster and we would like to have high availability and easy to scale. We would like to setup a minimal cluster environment but can be easily scaled in the future. This is my simple proposal:
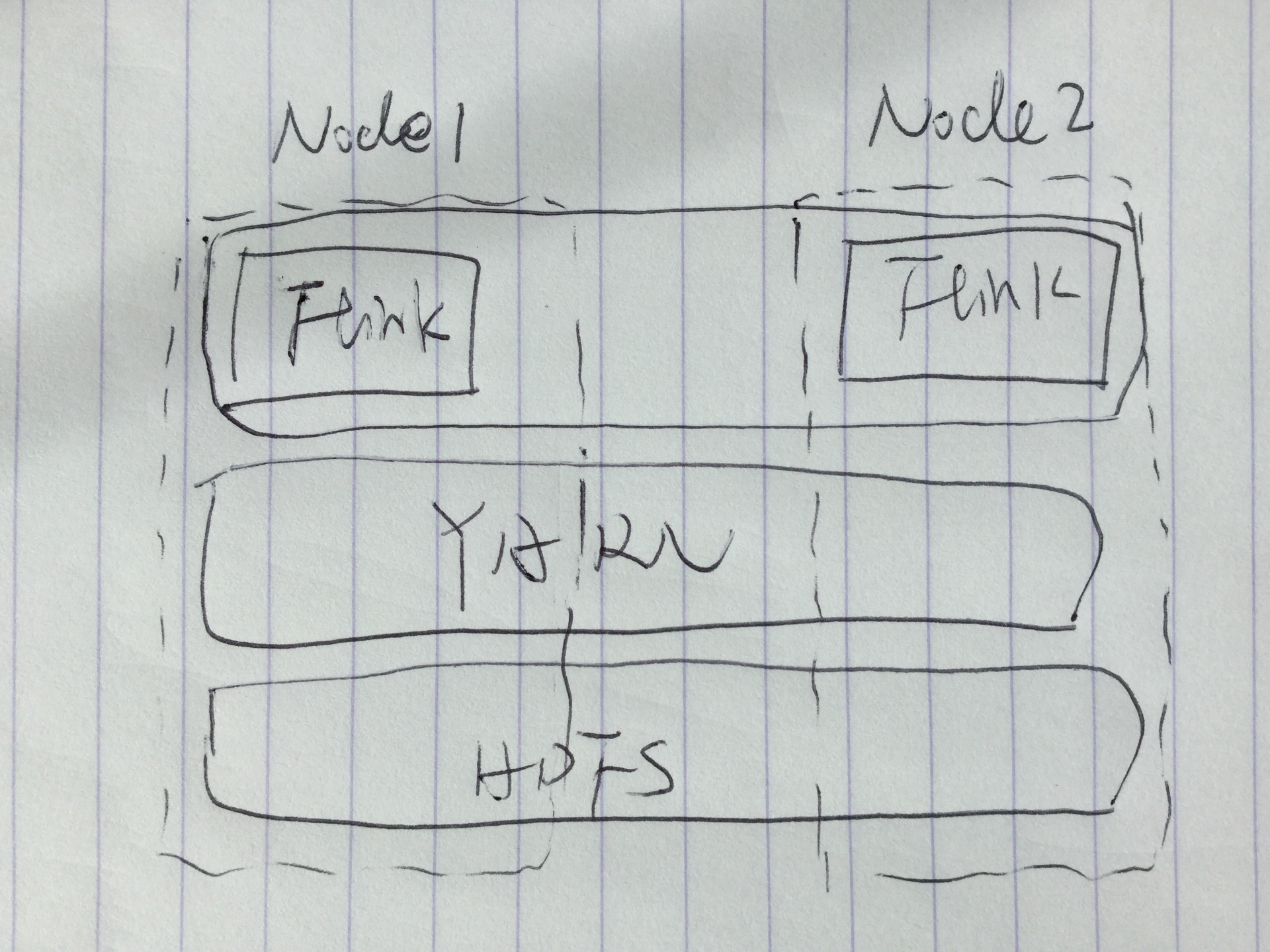 Based on it, my questions are:
Many thanks in advance!
Best regards/祝好, Chang Liu 刘畅 |
Re: questions about YARN deployment and HDFS integration
|
|
Hi Chiang,
Some of the answers you can find in line:
For both the above: When a task fails, the whole job (all the tasks) are restarted, and are rescheduled on different machines. If you use a local FS and you try to fetch state remotely upon recovery, how would the new nodes be able to locate the state on a remote machine? This is why Flink uses a distributed file system.
YARN can make sure that a new job master starts, but that master will have to fetch the state of the previous job master in order to know which jobs are running, their progress, etc.
You are right that you have to consider the above before deciding on your setup.
I hope this helps, Kostas |
|
|
Thanks for your answers :)
Best regards/祝好, Chang Liu 刘畅
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |