(no subject)


|
Hi all, I'm currently testing PyFlink against PySpark for batch jobs. The query I'm using is:selectMy configuration are default, created from official docker image:jobmanager.heap.size 1024m Thanks! Violeta |
|
|
Hi Violeta,
can you share your connector code with us? The plan looks quite complicated given the relatively simple query. Maybe there is some optimization potential. But before we dive deeper, I see a `Map(to: Row)` which indicates that we might work with a legacy sink connector. Did you try to run the same pipeline with only an outer join (without aggregation) or only aggregation (without the outer join)? It would be interesting to find the bottleneck. It might make sense to increase Flink's managed memory which is used for sorting. Also the JVM heap size looks pretty tiny. Regards, Timo On 08.09.20 08:30, Violeta Milanović wrote: > Hi all, I'm currently testing PyFlink against PySpark for batch jobs. > The query I'm using is:/select > max(c.first_name), > max(c.last_name), > avg(transaction_amount) as avg_ta, > avg(salary+bonus) as avg_income, > avg(salary+bonus) - avg(transaction_amount) as spending > from transactions t left join customers c on t.customer_id = c.customer_id > group by c.customer_id > > /It's really simple one, and I have 1 million data in customers and 5 > million in transactions. My output table should contains around 690k > rows. But I'm facing an issue, because when I want to sink into CSV 690k > rows, it's too slow comparing to PySpark. It's not problem when sink > table is one row, or even 100k rows, executions are way better than > PySpark. PySpark execution time is 50 seconds for this query and sink, > and PyFlink is around 120 seconds. I'm running it both in docker > container with default settings, and I increased parallelism for PyFlink > to 6, and this is execution with 6 cpus. I'm new at Flink's memory, and > as I understood to increase taskmanager.memory.process.size and > jobmanager.memory.process.size, which I tried, but it didn't help. > > My configuration are default, created from official docker image: > > jobmanager.heap.size 1024m > taskmanager.memory.size 1568m > cpu cores:6 > physical memory 11.7 > jvm head size: 512m > flink managed memory: 512m > > This is how my execution plan looks: > > 1.png > > > > Thanks! > Violeta |
|
|
Hi Timo, I actually tried many things, increasing jvm heap size and flink managed memory didn't help me. Running the same query without group by clause like this: select And execution time is 33 seconds, which is great, because is one row sink, also I tried only to join tables, but when sink is around 5 million, execution time is 986 seconds which I find strange, because it's only join, no aggregations. This is my connector code which is almost the same for both queries(output rows are different missing first and last name, because of removing group by) with group by and without group by: t_env.connect(FileSystem().path('transactions.csv')) \ Customers table is the same, only with different fields. Thanks again! |
|
|
You are using the old connectors. The new connectors are available via
SQL DDL (and execute_sql() API) like documented here: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/connectors/filesystem.html Maybe this will give your some performance boost, but certainly not enough. I will loop in someone from the SQL planner team (in CC). Regards, Timo On 08.09.20 17:27, Violeta Milanović wrote: > Hi Timo, > > I actually tried many things, increasing jvm heap size and flink managed > memory didn't help me. Running the same query without group by clause > like this: > > select > avg(transaction_amount) as avg_ta, > avg(salary+bonus) as avg_income, > avg(salary+bonus) - avg(transaction_amount) as spending > from transactions t left join customers c on t.customer_id = c.customer_id > > And execution time is 33 seconds, which is great, because is one row > sink, also I tried only to join tables, but when sink is around 5 > million, execution time is 986 seconds which I find strange, because > it's only join, no aggregations. > > This is my connector code which is almost the same for both > queries(output rows are different missing first and last name, because > of removing group by) with group by and without group by: > > t_env.connect(FileSystem().path('transactions.csv')) \ > .with_format(OldCsv().ignore_first_line().field_delimiter(",").quote_character('\"') > .field('transaction_id', DataTypes.STRING()) > .field('product_id', DataTypes.STRING()) > .field('transaction_amount', DataTypes.DOUBLE()) > .field('transaction_date', DataTypes.STRING()) > .field('customer_id', DataTypes.STRING()) > ) \ > .with_schema(Schema() > .field('transaction_id', DataTypes.STRING()) > .field('product_id', DataTypes.STRING()) > .field('transaction_amount', DataTypes.DOUBLE()) > .field('transaction_date', DataTypes.STRING()) > .field('customer_id', DataTypes.STRING()) > ) \ > .create_temporary_table('transactions') > > t_env.connect(FileSystem().path('join_output.csv')) \ > .with_format(Csv().derive_schema() > ) \ > .with_schema(Schema() > .field('avg_ta', DataTypes.DOUBLE()) > .field('avg_income', DataTypes.INT()) > .field('spending', DataTypes.DOUBLE()) > ) \ > .create_temporary_table('mySink') > > Customers table is the same, only with different fields. > > Thanks again! > > |
|
|
Hi Violeta,
I just noticed that the plan might be generated from Flink's old planner instead of the new, more performant Blink planner. Which planner are you currently using? Regards, Timo On 08.09.20 17:51, Timo Walther wrote: > You are using the old connectors. The new connectors are available via > SQL DDL (and execute_sql() API) like documented here: > > https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/connectors/filesystem.html > > > Maybe this will give your some performance boost, but certainly not > enough. I will loop in someone from the SQL planner team (in CC). > > Regards, > Timo > > > On 08.09.20 17:27, Violeta Milanović wrote: >> Hi Timo, >> >> I actually tried many things, increasing jvm heap size and flink >> managed memory didn't help me. Running the same query without group by >> clause like this: >> >> select >> avg(transaction_amount) as avg_ta, >> avg(salary+bonus) as avg_income, >> avg(salary+bonus) - avg(transaction_amount) as spending >> from transactions t left join customers c on t.customer_id = >> c.customer_id >> >> And execution time is 33 seconds, which is great, because is one row >> sink, also I tried only to join tables, but when sink is around 5 >> million, execution time is 986 seconds which I find strange, because >> it's only join, no aggregations. >> >> This is my connector code which is almost the same for both >> queries(output rows are different missing first and last name, because >> of removing group by) with group by and without group by: >> >> t_env.connect(FileSystem().path('transactions.csv')) \ >> >> .with_format(OldCsv().ignore_first_line().field_delimiter(",").quote_character('\"') >> >> .field('transaction_id', DataTypes.STRING()) >> .field('product_id', DataTypes.STRING()) >> .field('transaction_amount', DataTypes.DOUBLE()) >> .field('transaction_date', DataTypes.STRING()) >> .field('customer_id', DataTypes.STRING()) >> ) \ >> .with_schema(Schema() >> .field('transaction_id', DataTypes.STRING()) >> .field('product_id', DataTypes.STRING()) >> .field('transaction_amount', DataTypes.DOUBLE()) >> .field('transaction_date', DataTypes.STRING()) >> .field('customer_id', DataTypes.STRING()) >> ) \ >> .create_temporary_table('transactions') >> >> t_env.connect(FileSystem().path('join_output.csv')) \ >> .with_format(Csv().derive_schema() >> ) \ >> .with_schema(Schema() >> .field('avg_ta', DataTypes.DOUBLE()) >> .field('avg_income', DataTypes.INT()) >> .field('spending', DataTypes.DOUBLE()) >> ) \ >> .create_temporary_table('mySink') >> >> Customers table is the same, only with different fields. >> >> Thanks again! >> >> > |
|
|
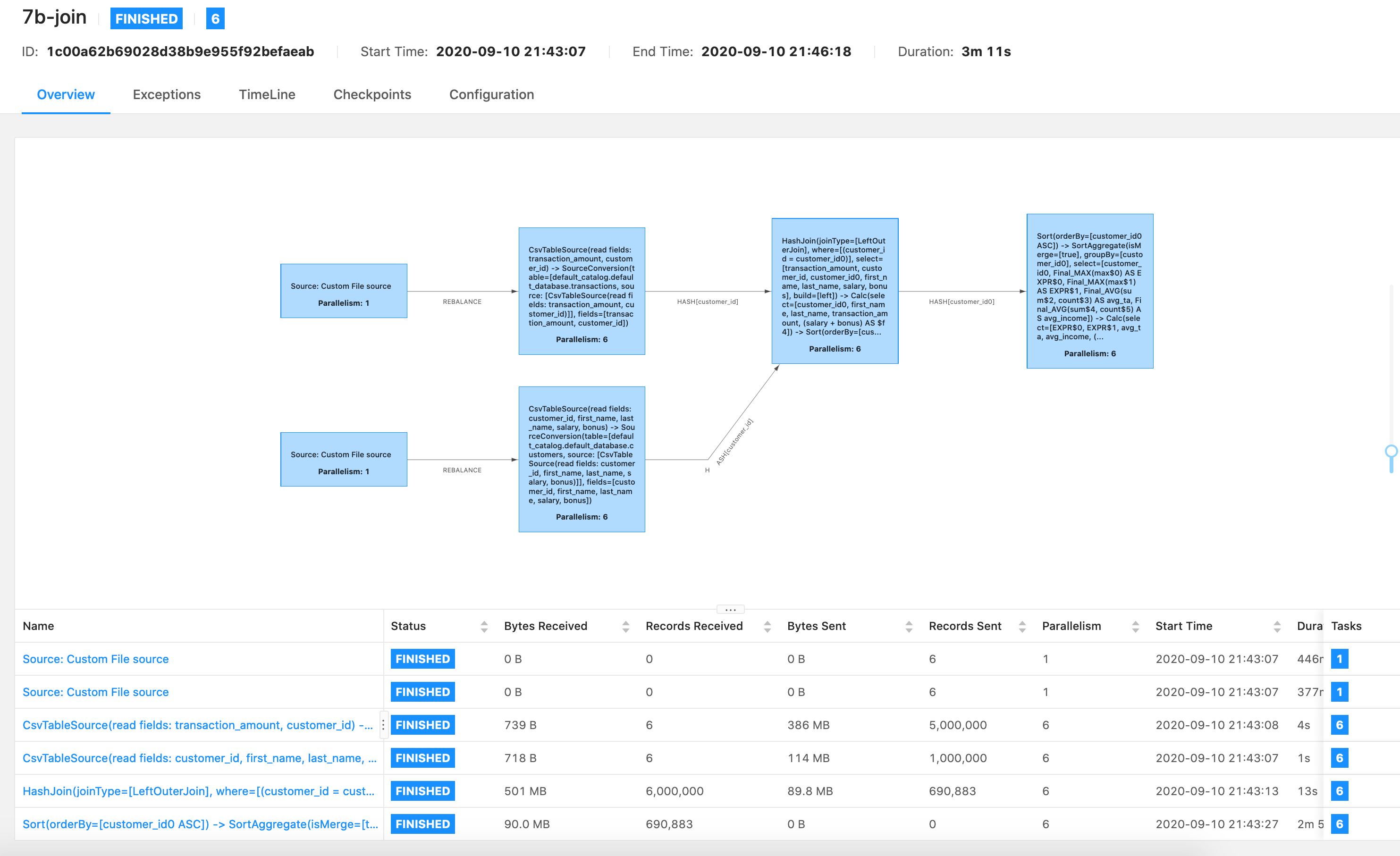
Hi Timo, Thanks for your answers, I tried again with new connectors, and blink planner and execute_sql(), plan is simpler indeed, but results are almost the same. 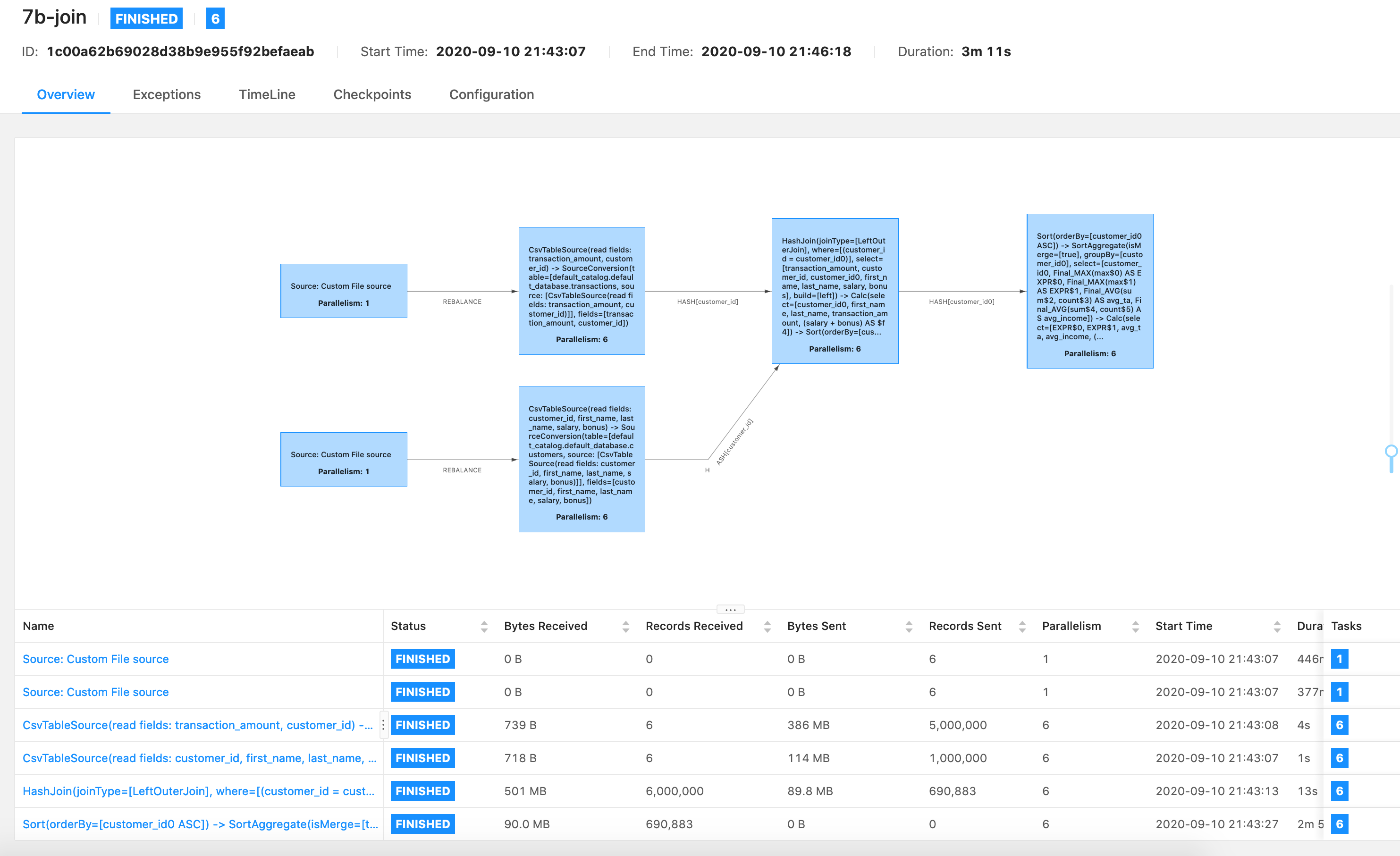 Tried both queries with 1.11 version, 7-join is old one with old connectors, sql queries and planner, and 7b is the new one with new connectors, execute_sql() and blink planner  As you can see almost the same, these are two consecutive runs of quieres. I stayed with version 1.10 and old connectors and planner for now, and version 1.10 does not support execute_sql()  Thanks, Violeta On Thu, Sep 10, 2020 at 11:45 AM Timo Walther <[hidden email]> wrote: Hi Violeta, |
|
|
Could you upload the log of the last operator, the one begins with "Sort"? Best, Kurt On Fri, Sep 11, 2020 at 4:54 AM Violeta Milanović <[hidden email]> wrote:
|
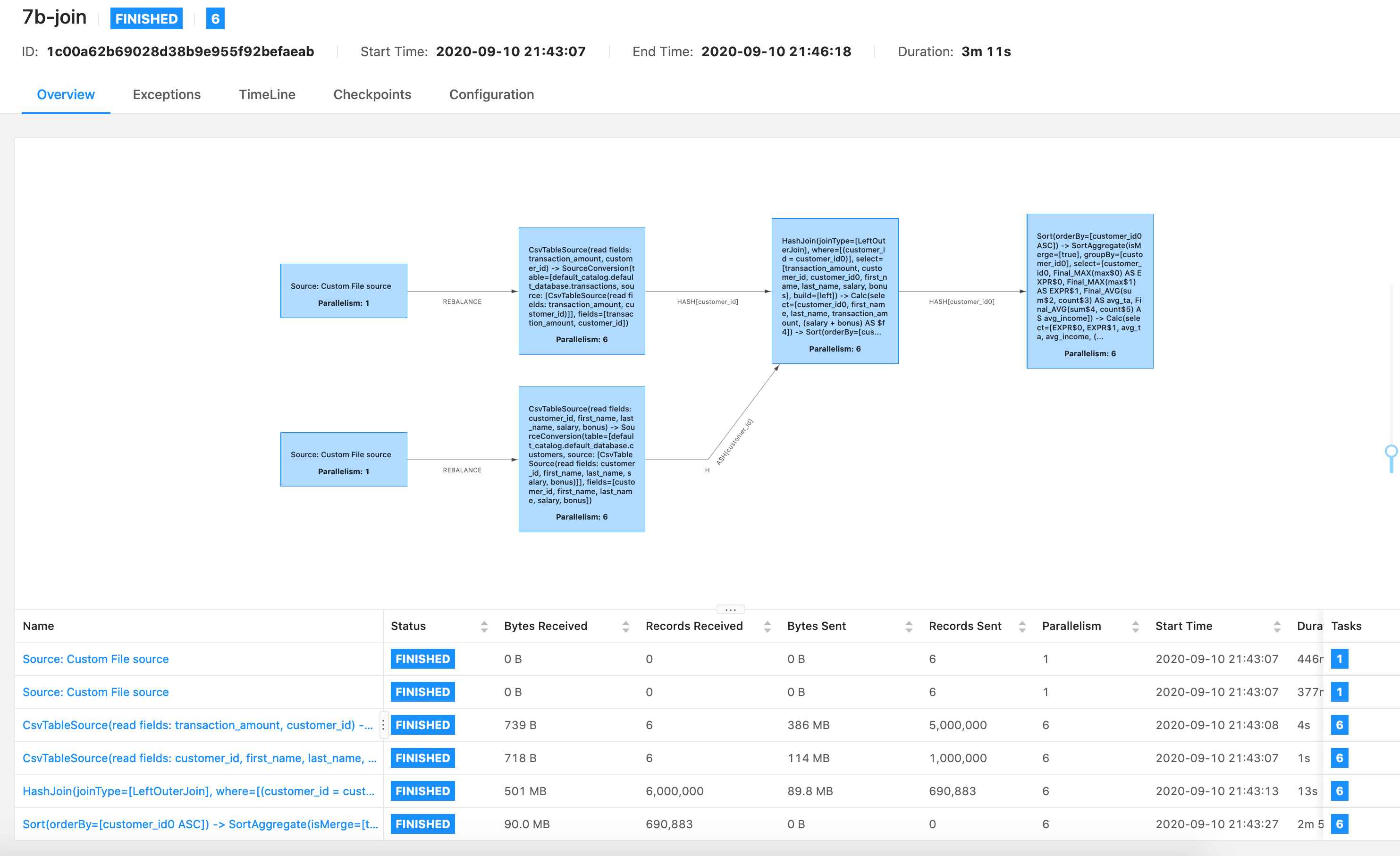


|
|
Hi Violeta, Sorry for the late reply. I'm curious why the last operator ("Sort -> SortAgg -> CsvSink") is so slow, it's input has only 90M data. Regarding to your first image, the last operator took nearly two minutes, which only writes 32M data. So I guess the CSV writer is the performance bottleneck. Could you use other sinks (e.g. print sink) instead of csv sink to check whether only the csv sink is the bottleneck. Best, Godfrey Kurt Young <[hidden email]> 于2020年9月16日周三 下午2:22写道:
|
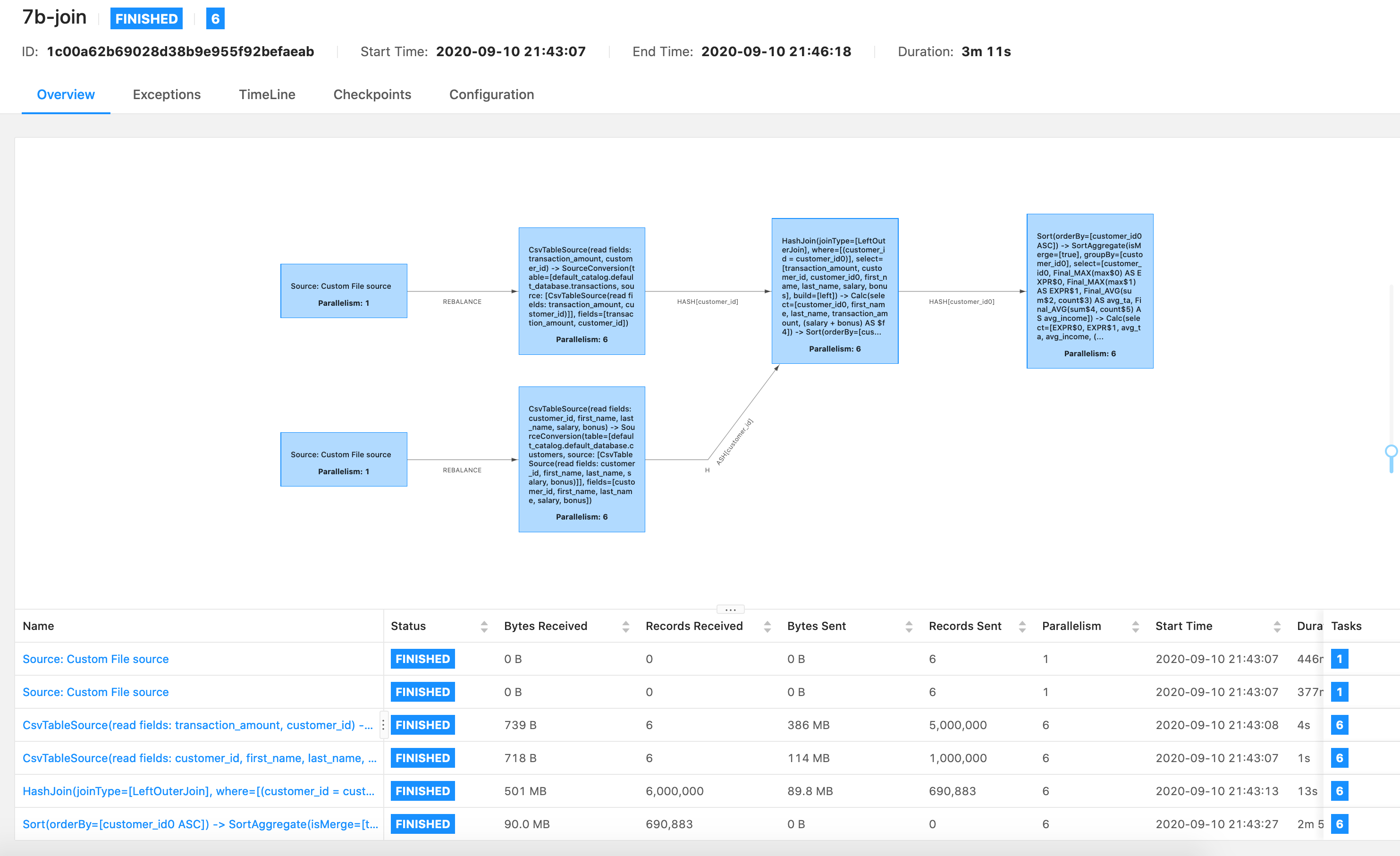


|
|
Hi Violeta, I did a similar test in my local environment based on TPCH [1] test data with scale factor 1. I started a session cluster in my local, and submitted the test query in sql client with blink planner. here is my test details: DDLs: create table lineitem ( l_orderkey bigint not null, l_partkey bigint not null, l_suppkey bigint not null, l_linenumber int not null, l_quantity double not null, l_extendedprice double not null, l_discount double not null, l_tax double not null, l_returnflag varchar not null, l_linestatus varchar not null, l_shipdate date not null, l_commitdate date not null, l_receiptdate date not null, l_shipinstruct varchar not null, l_shipmode varchar not null, l_comment varchar not null ) with ( 'connector.type'='filesystem', 'format.type'='csv', 'format.field-delimiter'='|', 'connector.path'='file:///<your_tpch_data_path>/lineitem.tbl' ); create table orders ( o_orderkey bigint not null, o_custkey bigint not null, o_orderstatus varchar not null, o_totalprice double not null, o_orderdate date not null, o_orderpriority varchar not null, o_clerk varchar not null, o_shippriority int not null, o_comment varchar not null ) with ( 'connector.type'='filesystem', 'format.type'='csv', 'format.field-delimiter'='|', 'connector.path'='file:///<your_tpch_data_path>/orders.tbl' ); create table my_sink ( o_orderstatus varchar, o_comment varchar, avg_ta double not null, avg_income double not null, spending double not null ) with ( 'connector.type'='filesystem', 'format.type'='csv', 'format.field-delimiter'='|', 'connector.path'='file:///<your_result_path>/result' ); QUERY (similar with yours) insert into my_sink select max(c.o_orderstatus), max(c.o_comment), avg(l_quantity) as avg_ta, avg(l_extendedprice+l_tax) as avg_income, avg(l_extendedprice+l_tax) - avg(l_discount) as spending from lineitem t left join orders c on t.l_orderkey = c.o_orderkey group by c.o_orderkey; And here is my execution result:  the last operator only takes 9 seconds. So, just as Kurt's mentioned, we need your execution log to do more analysis. Best, Godfrey godfrey he <[hidden email]> 于2020年9月16日周三 下午10:45写道:
|
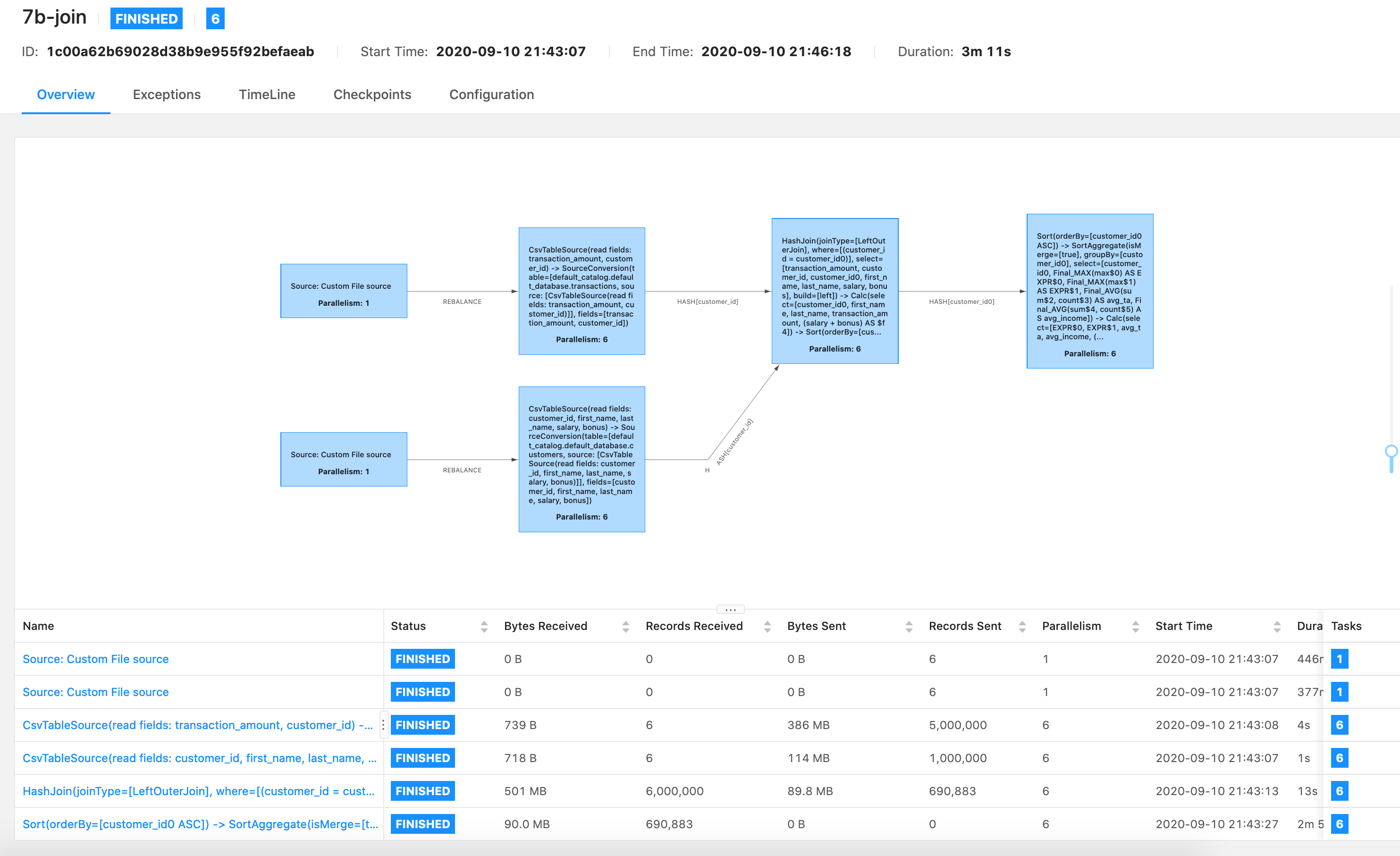


|
|
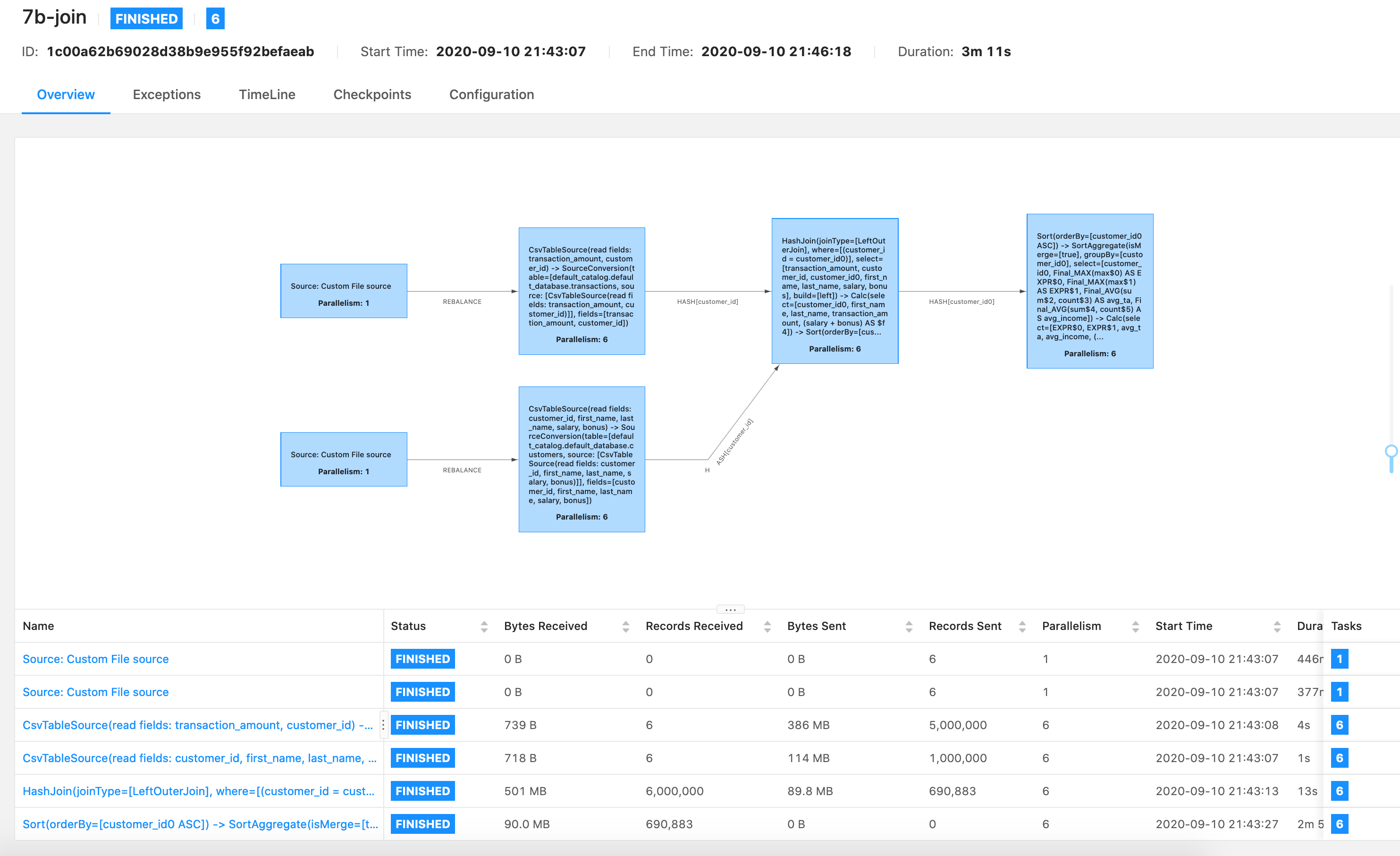
Hi Godfrey, I'm sending you my log files. Best, Violeta On Mon, Sep 21, 2020 at 3:49 AM godfrey he <[hidden email]> wrote:
|



|
|
Hi Violeta, I do not find any useful info in you logs, Only brief information shows that the last operator started running at 05:19:37,427 and finished at 05:21:41,621. 2020-09-21 05:19:37,427 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Sort(orderBy=[customer_id0 ASC]) -> SortAggregate(isMerge=[true], groupBy=[customer_id0], select=[customer_id0, Final_MAX(max$0) AS EXPR$0, Final_MAX(max$1) AS EXPR$1, Final_AVG(sum$2, count$3) AS avg_ta, Final_AVG(sum$4, count$5) AS avg_income]) -> Calc(select=[EXPR$0, EXPR$1, avg_ta, avg_income, (avg_income - avg_ta) AS spending]) -> SinkConversionToRow -> Map -> Sink: CsvTableSink(first_name, last_name, avg_ta, avg_income, spending) (1/6) (f8fa1ac890d6482446298d03061c9316) switched from DEPLOYING to RUNNING. 2020-09-21 05:21:41,621 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Sort(orderBy=[customer_id0 ASC]) -> SortAggregate(isMerge=[true], groupBy=[customer_id0], select=[customer_id0, Final_MAX(max$0) AS EXPR$0, Final_MAX(max$1) AS EXPR$1, Final_AVG(sum$2, count$3) AS avg_ta, Final_AVG(sum$4, count$5) AS avg_income]) -> Calc(select=[EXPR$0, EXPR$1, avg_ta, avg_income, (avg_income - avg_ta) AS spending]) -> SinkConversionToRow -> Map -> Sink: CsvTableSink(first_name, last_name, avg_ta, avg_income, spending) (1/6) (f8fa1ac890d6482446298d03061c9316) switched from RUNNING to FINISHED. No more detailed info is in the log files. Can you change the log level to DEBUG, or can you try to replace the csv sink with other sink ? Best, Godfrey Violeta Milanović <[hidden email]> 于2020年9月21日周一 下午1:34写道:
|



«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |