java.lang.Exception: TaskManager was lost/killed


|
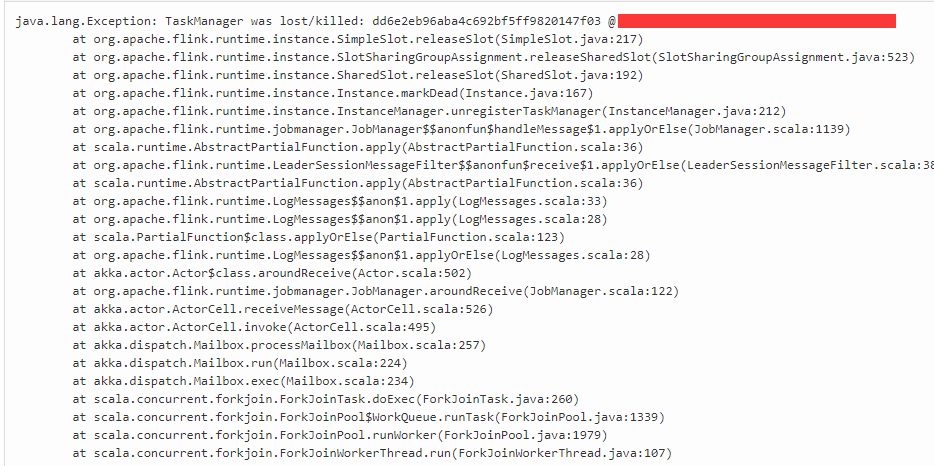 hi all, recently, i found a problem,it runs well when start. But after long run,the exception display as above,how can resolve it?
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
I have seen this when my task manager ran out of RAM. Increase the heap size.
flink-conf.yaml: taskmanager.heap.mb jobmanager.heap.mb Michael
|
|
|
thanks a lot,i will try it
在 2018-04-09 00:06:02,"TechnoMage" <[hidden email]> 写道: I have seen this when my task manager ran out of RAM. Increase the heap size.
|
Re: Re: java.lang.Exception: TaskManager was lost/killed
|
|
I've seen similar problem, but it was not a heap size, but Metaspace. It was caused by a job restarting in a loop. Looks like for each restart, Flink loads new instance of classes and very soon in runs out of metaspace. I've created a JIRA issue for this problem, but got no response from the development team on it: https://issues.apache.org/jira/browse/FLINK-9132 On Mon, Apr 9, 2018 at 11:36 AM 王凯 <[hidden email]> wrote: thanks a lot,i will try it |
Re: Re: java.lang.Exception: TaskManager was lost/killed
|
|
Hi, We had the same metaspace problem, it was solved by adding the jar file to the /lib path of every task manager, as explained here https://ci.apache.org/projects/flink/flink-docs-release-1.4/monitoring/debugging_classloading.html#avoiding-dynamic-classloading. As well we added these java options: "-XX:CompressedClassSpaceSize=100M -XX:MaxMetaspaceSize=300M -XX:MetaspaceSize=200M " From time to time we have the same problem with TaskManagers disconnecting, but the logs are not useful. We are using 1.3.2. On 9 April 2018 at 10:41, Alexander Smirnov <[hidden email]> wrote:
|
Re: Re: java.lang.Exception: TaskManager was lost/killed
|
|
Javier
"adding the jar file to the /lib path of every task manager"are you moving the job jar to the ~/flink-1.4.2/lib path ? On Mon, Apr 9, 2018 at 12:23 PM, Javier Lopez <[hidden email]> wrote:
|
Re: Re: java.lang.Exception: TaskManager was lost/killed
|
|
Hi, "are you moving the job jar to the ~/flink-1.4.2/lib path ? " -> Yes, to every node in the cluster. On 9 April 2018 at 15:37, miki haiat <[hidden email]> wrote:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
We will need more information to offer
any solution. The exception simply means that a TaskManager shut
down, for which there are a myriad of possible explanations.
Please have a look at the TaskManager logs, they may contain a hint as to why it shut down. On 09.04.2018 16:01, Javier Lopez wrote:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
We see the same running 1.4.2 on Yarn hosted on Aws EMR cluster. The only thing I can find in the logs from are SIGTERM with the code 15 or -100.
Today our simple job reading from Kinesis and writing to Cassandra was killed. The other day in another job I identified a map state.remove command to cause a task manager lost without and exception I find it frustrating that it is so hard to find the root cause. If I look on historical metrics on cpu, heap and non heap I can’t see anything that should cause a problem. So any ideas about how to debug this kind of exception is much appreciated.
Med venlig hilsen / Best regards Lasse Nedergaard
|
|
|
Same story here, 1.3.2 on K8s. Very hard to find reasons on why a TM is killed. Not likely caused by memory leak. If there is a logger I have turn on please let me know.
On Mon, Apr 9, 2018, 13:41 Lasse Nedergaard <[hidden email]> wrote:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
In reply to this post by Chesnay Schepler
Hi Chesnay,
Don’t know if this helps, but I’d run into this as well, though I haven’t hooked up YourKit to analyze exactly what’s causing the memory problem.
E.g. after about 3.5 hours running locally, it failed with memory issues. In the TaskManager logs, I start seeing exceptions in my code…. java.lang.OutOfMemoryError: GC overhead limit exceeded And then eventually... 2018-04-07 21:55:25,686 WARN org.apache.flink.runtime.accumulators.AccumulatorRegistry - Failed to serialize accumulators for task. java.lang.OutOfMemoryError: GC overhead limit exceeded Immediately after this, one of my custom functions gets a close() call, and I see a log msg about it "switched from RUNNING to FAILED”. After this, I see messages that the job is being restarted, but the TaskManager log output abruptly ends. In the Job Manager log, this is what is output following the time of the last TaskManager logging output: 2018-04-07 21:57:33,702 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 129 @ 1523163453702 2018-04-07 21:58:43,916 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [<a href="akka.tcp://flink@kens-mbp.hsd1.ca.comcast.net:63780" class="">akka.tcp://flink@...:63780] has failed, address is now gated for [5000] ms. Reason: [Disassociated] 2018-04-07 21:58:51,084 WARN akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780 2018-04-07 21:58:51,086 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://[hidden email]:63780] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://[hidden email]:63780]] Caused by: [Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780] 2018-04-07 21:59:01,047 WARN akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780 2018-04-07 21:59:01,050 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://[hidden email]:63780] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://[hidden email]:63780]] Caused by: [Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780] 2018-04-07 21:59:11,057 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://[hidden email]:63780] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://[hidden email]:63780]] Caused by: [Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780] 2018-04-07 21:59:11,058 WARN akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780 2018-04-07 21:59:21,049 WARN akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780 2018-04-07 21:59:21,049 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://[hidden email]:63780] has failed, address is now gated for [5000] ms. Reason: [Association failed with [akka.tcp://[hidden email]:63780]] Caused by: [Connection refused: kens-mbp.hsd1.ca.comcast.net/192.168.3.177:63780] 2018-04-07 21:59:21,056 WARN akka.remote.RemoteWatcher - Detected unreachable: [akka.tcp://[hidden email]:63780] 2018-04-07 21:59:21,063 INFO org.apache.flink.runtime.jobmanager.JobManager - Task manager akka.tcp://[hidden email]:63780/user/taskmanager terminated. 2018-04-07 21:59:21,064 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - FetchUrlsFunction for sitemap -> ParseSiteMapFunction -> OutlinkToStateUrlFunction (1/1) (3e9374d1bf5fdb359e3a624a4d5d659b) switched from RUNNING to FAILED. java.lang.Exception: TaskManager was lost/killed: c51d3879b6244828eb9fc78c943007ad @ kens-mbp.hsd1.ca.comcast.net (dataPort=63782) — Ken
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
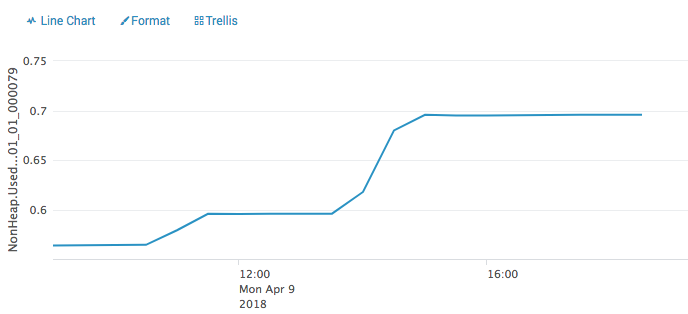
Hi. I found the exception attached below, for our simple job. It states that our task-manager was killed du to exceed memory limit on 2.7GB. But when I look at Flink metricts just 30 sec before it use 1.3 GB heap and 712 MB Non-Heap around 2 GB. So something else are also using memory inside the conatianer any idea how to figure out what? As a side note we use RockDBStateBackend with this configuration env.getCheckpointConfig().setMinPauseBetweenCheckpoints((long)(config.checkPointInterval * 0.75));Where checkpointDataUri point to S3 Lasse Nedergaard 2018-04-09 16:52:01,239 INFO org.apache.flink.yarn.YarnFlinkResourceManager - Diagnostics for container container_1522921976871_0001_01_000079 in state COMPLETE : exitStatus=Pmem limit exceeded (-104) diagnostics=Container [pid=30118,containerID=container_1522921976871_0001_01_000079] is running beyond physical memory limits. Current usage: 2.7 GB of 2.7 GB physical memory used; 4.9 GB of 13.4 GB virtual memory used. Killing container. Dump of the process-tree for container_1522921976871_0001_01_000079 : |- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE |- 30136 30118 30118 30118 (java) 245173 68463 5193723904 703845 /usr/lib/jvm/java-openjdk/bin/java -Xms2063m -Xmx2063m -Dlog.file=/var/log/hadoop-yarn/containers/application_1522921976871_0001/container_1522921976871_0001_01_000079/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskManager --configDir . |- 30118 30116 30118 30118 (bash) 0 0 115818496 674 /bin/bash -c /usr/lib/jvm/java-openjdk/bin/java -Xms2063m -Xmx2063m -Dlog.file=/var/log/hadoop-yarn/containers/application_1522921976871_0001/container_1522921976871_0001_01_000079/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskManager --configDir . 1> /var/log/hadoop-yarn/containers/application_1522921976871_0001/container_1522921976871_0001_01_000079/taskmanager.out 2> /var/log/hadoop-yarn/containers/application_1522921976871_0001/container_1522921976871_0001_01_000079/taskmanager.err 2018-04-09 16:51:26,659 DEBUG org.trackunit.tm2.LogReporter - gauge.ip-10-1-1-181.taskmanager.container_1522921976871_0001_01_000079.Status.JVM.Memory.Heap.Used=1398739496 2018-04-09 16:51:26,659 DEBUG org.trackunit.tm2.LogReporter - gauge.ip-10-1-1-181.taskmanager.container_1522921976871_0001_01_000079.Status.JVM.Memory.NonHeap.Used=746869520 2018-04-09 23:52 GMT+02:00 Ken Krugler <[hidden email]>:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
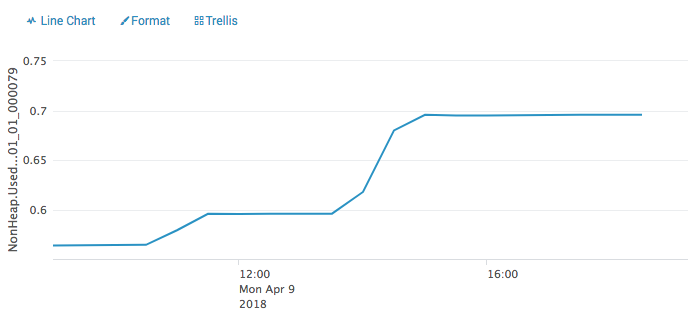 This graph shows Non-Heap . If the same pattern exists it make sense that it will try to allocate more memory and then exceed the limit. I can see the trend for all other containers that has been killed. So my question is now, what is using non-heap memory? From http://mail-archives.apache.org/mod_mbox/flink-user/201707.mbox/%3CCANC1h_u0dQQvbysDAoLLbEmeWaxiimTMFjJCribPfpo0iDLZ_g@...%3E it look like RockDb could be guilty. I have job using incremental checkpointing and some without, some optimised for FLASH_SSD. all have same pattern Lasse 2018-04-10 8:52 GMT+02:00 Lasse Nedergaard <[hidden email]>:
|
|
|
Can you use third party site for the graph ?
I cannot view it. Thanks -------- Original message -------- From: Lasse Nedergaard <[hidden email]> Date: 4/10/18 12:25 AM (GMT-08:00) To: Ken Krugler <[hidden email]> Cc: user <[hidden email]>, Chesnay Schepler <[hidden email]> Subject: Re: java.lang.Exception: TaskManager was lost/killed This graph shows Non-Heap . If the same pattern exists it make sense that it will try to allocate more memory and then exceed the limit. I can see the trend for all other containers that has been killed. So my question is now, what is using non-heap memory? From http://mail-archives.apache.org/mod_mbox/flink-user/201707.mbox/%3CCANC1h_u0dQQvbysDAoLLbEmeWaxiimTMFjJCribPfpo0iDLZ_g@...%3E it look like RockDb could be guilty. I have job using incremental checkpointing and some without, some optimised for FLASH_SSD. all have same pattern Lasse 2018-04-10 8:52 GMT+02:00 Lasse Nedergaard <[hidden email]>:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
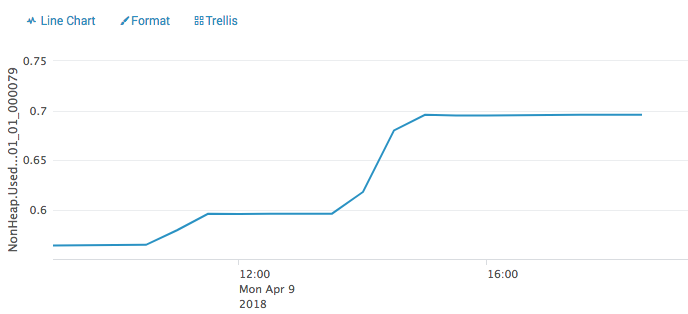
This time attached. 2018-04-10 10:41 GMT+02:00 Ted Yu <[hidden email]>:
|
|
|
In reply to this post by Lasse Nedergaard
On Tue, Apr 10, 2018 at 12:25 AM, Lasse Nedergaard <[hidden email]> wrote:
|
|
|
Hi Lasse, I met that before. I think maybe the non-heap memory trend of the graph you attached is the "expected" result ... Because rocksdb will keep the a "filter (bloom filter)" in memory for every opened sst file by default, and the num of the sst file will increase by time, so it looks like a leak. There is a issue(https://issues.apache.org/jira/browse/FLINK-7289) Stefan created to track this, and the page(https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB) from RocksDB's wiki could give you a better understand of the memory used by RocksDB, and Stefan please correct me if I bring any wrong information above. Best Regards, Sihua Zhou On 04/11/2018 09:55,[hidden email] wrote:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
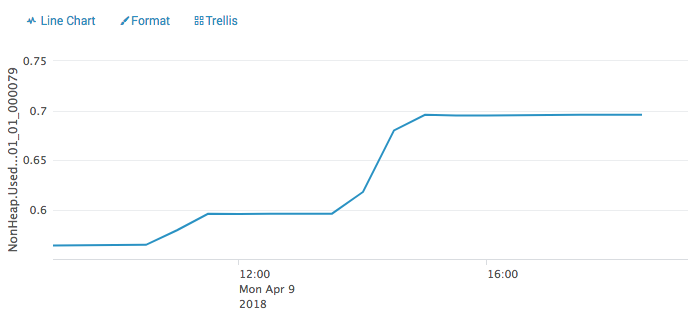
Hi. Anyone that from top of your head can tell me how I can see the memory usage inside a Yarn container running on EMR? I need to go into these details as I yesterday created a new cluster with task-managers allocated 20 GB mem, and they was killed during the night and the heap and non-heap was way below the allocated memory (see attatchment) so I would like to figure out what is using all the memory, RocksDB, aws Kinesis procedure daemon or something else. Lasse Nedergaard 2018-04-11 04:38:28,105 INFO org.apache.flink.yarn.YarnFlinkResourceManager - Diagnostics for container container_1523368093942_0004_01_000006 in state COMPLETE : exitStatus=Pmem limit exceeded (-104) diagnostics=Container [pid=14155,containerID=container_1523368093942_0004_01_000006] is running beyond physical memory limits. Current usage: 19.5 GB of 19.5 GB physical memory used; 29.5 GB of 97.7 GB virtual memory used. Killing container.
Dump of the process-tree for container_1523368093942_0004_01_000006 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 14173 14155 14155 14155 (java) 731856 128928 31159238656 5120164 /usr/lib/jvm/java-openjdk/bin/java -Xms15000m -Xmx15000m -Dlog.file=/var/log/hadoop-yarn/containers/application_1523368093942_0004/container_1523368093942_0004_01_000006/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskManager --configDir .
|- 14155 14153 14155 14155 (bash) 0 0 115818496 664 /bin/bash -c /usr/lib/jvm/java-openjdk/bin/java -Xms15000m -Xmx15000m -Dlog.file=/var/log/hadoop-yarn/containers/application_1523368093942_0004/container_1523368093942_0004_01_000006/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskManager --configDir . 1> /var/log/hadoop-yarn/containers/application_1523368093942_0004/container_1523368093942_0004_01_000006/taskmanager.out 2> /var/log/hadoop-yarn/containers/application_1523368093942_0004/container_1523368093942_0004_01_000006/taskmanager.err
|- 3579 14173 14155 14155 (kinesis_produce) 150 25 406056960 3207 /tmp/amazon-kinesis-producer-native-binaries/kinesis_producer_d93825f806782576ef9f09eef67a2baeadfec35c -o /tmp/amazon-kinesis-producer-native-binaries/amz-aws-kpl-out-pipe-f8b715df -i /tmp/amazon-kinesis-producer-native-binaries/amz-aws-kpl-in-pipe-f787eee9 -c 0800328401080110FFFFFFFF0F18809003220028BB0330F403388080C00240F02E480050005A0060BB036A04696E666F70187A05736861726482010864657461696C65648A01164B696E6573697350726F64756365724C6962726172799001E0D403980101A00164A80164B001B0EA01BA010965752D776573742D31C001F02EC80101D00101D8010A -k 08FFFFFFFFFFFFFFFF7F4A44080012400A14414B49414A4F52573753514F355143324B57414112286F78693674774B524A3243616665464C4F7535304F2B506B597369562B47545368526C762B625932 -t -w 08FFFFFFFFFFFFFFFF7F4A44080112400A14414B49414A4F52573753514F355143324B57414112286F78693674774B524A3243616665464C4F7535304F2B506B597369562B47545368526C762B625932
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143 2018-04-11 5:03 GMT+02:00 周思华 <[hidden email]>:
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
I’ve been able to hook up YourKit (commercial Java profiler) to tasks running in EMR.
IIRC there was a bit of pain to get the right port open (AWS security group configuration fun) — Ken
|
Re: java.lang.Exception: TaskManager was lost/killed
|
|
Hi. I have news, not sure it is good. I have tried to limit RocksDb with the configuration mention from the links provided, but it didn't solved the problem. (se the configuration below.). I build a new cluster with 19 GB mem allocated, 8 vcores and thereby 8 slots. Out heap is around 6 GB and non-heap around 1.6 GB, so plenty of free memory but our task managers still get killed with 2018-04-12 11:18:15,807 INFO org.apache.flink.yarn.YarnFlinkResourceManager - Diagnostics for container container_1523368093942_0004_01_000073 in state COMPLETE : exitStatus=Pmem limit exceeded (-104) diagnostics=Container [pid=13279,containerID=container_1523368093942_0004_01_000073] is running beyond physical memory limits. Current usage: 19.6 GB of 19.5 GB physical memory used; 30.7 GB of 97.7 GB virtual memory used. Killing container. I also did a heap dump on the container and it shows the same utilisation as Flink metrics regarding memory use. This morning we played around with our Cassandra cluster and we lost qurum and then our jobs inserting into Cassandra failed all the time and get restarted because of this. Right away the frequencies of task manager kills increased. Looking at https://issues.apache.org/jira/browse/FLINK-7289 explains the same problem that a restart cause a leak (not sure where, and who should clean it up) and therefore we see our task managers get killed. It also make sense as our new pipeline fails more than the old one, as we get exceptions from AWS kinesis producer, and the old pipeline didn't use kinesis producer. Problem described here https://github.com/awslabs/amazon-kinesis-producer/issues/39#issuecomment-379759277 So my conclusion right now is that Flink on EMR doesn't manage to restarts job without leaks, and we therefore can't rely on restart and have to protect us as much as possible against external errors. Not always an easy task. Next I will try is to exchange RocksDb with FsStateBackend to see if it's RockDbs that cause the problem, or something else. Please let me know it have have miss anything. Lasse Nedergaard Rocks db configuration final long blockCacheSize = 64 * SizeUnit.MB; 2018-04-11 16:27 GMT+02:00 Ken Krugler <[hidden email]>:
|
| Free forum by Nabble | Edit this page |