flink cdc postgres connector 1.1 - heartbeat.interval.ms - WAL consumption


|
Hi there,
I am using flink 1.11 and cdc connector 1.1 to stream changes from a postgres table. I see the WAL consumption is increasing gradually even though the writes to tables are very less. I am using AWS RDS, from [1] I understand that setting the parameter heartbeat.interval.ms solves this WAL consumption issue. However, I tried setting this with no success. I found a bug [2] which seems to be taking care of committing the lsn for the db to release the wal. however this seems to be only fixed in 1.3 which is compatible with flink 1.12.1. Is there any way this can be fixed in 1.11.1. Since I am using EMR and the latest flink version available is 1.11. Thanks. Hemant |
|
|
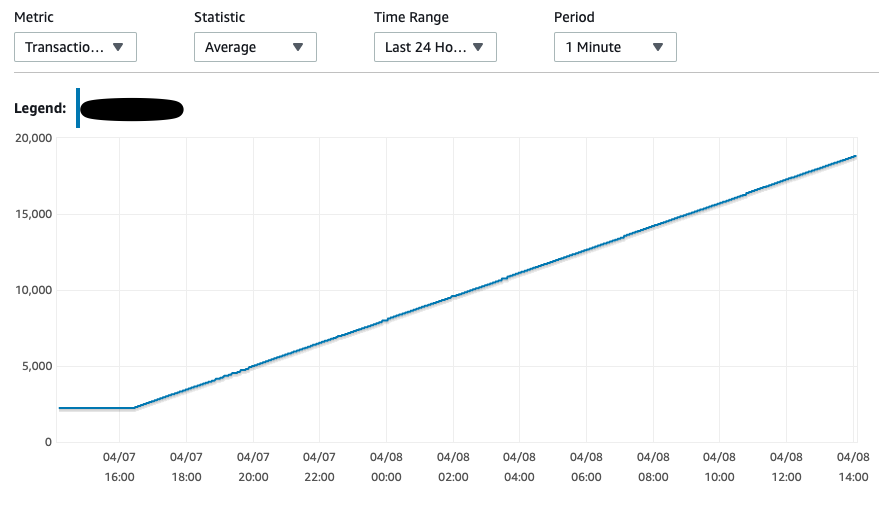
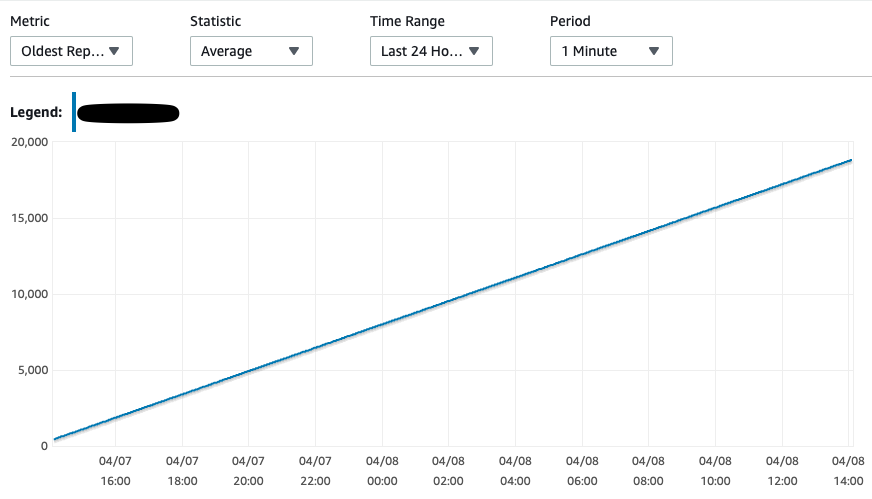
Anyone who has faced similar issues with cdc with Postgres. I see the restart_lsn and confirmed_flush_lsn constant since the snapshot replication records were streamed even though I have tried inserting a record in the whitelisted table. slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn -------------+----------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+--------------------- stream_cdc3 | pgoutput | logical | 16411 | test_cdc | f | t | 1146 | | 6872 | 62/34000828 | 62/34000860 I have passed the heartbeat.interval.ms = 1000 and could see the heartbeat events streamed to flink however the transaction log disk usage and oldest replication slot lag consistently increasing. From [1] I have also tried this - For other decoder plug-ins, it is recommended to create a supplementary table that is not monitored by Debezium. A separate process would then periodically update the table (either inserting a new event or updating the same row all over). PostgreSQL then will invoke Debezium which will confirm the latest LSN and allow the database to reclaim the WAL space. 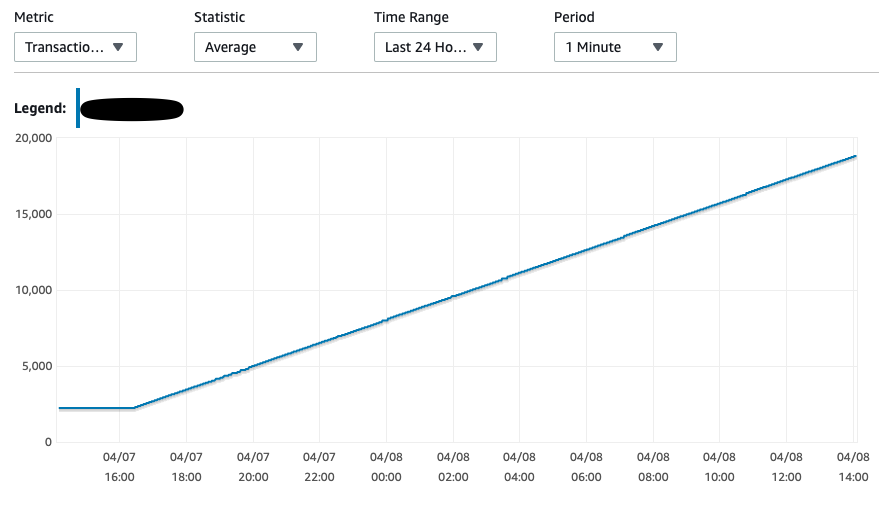 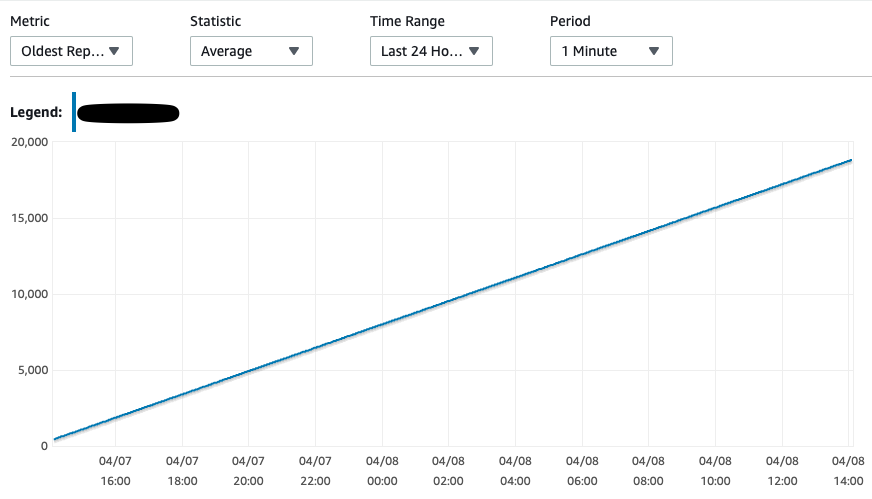 Thanks. On Wed, Apr 7, 2021 at 12:51 PM bat man <[hidden email]> wrote:
|
Re: flink cdc postgres connector 1.1 - heartbeat.interval.ms - WAL consumption
|
|
Hi Hemant, I am pulling in Jark who is most familiar with Flink's cdc connector. He might also be able to tell whether the fix can be backported. Cheers, Till On Thu, Apr 8, 2021 at 10:42 AM bat man <[hidden email]> wrote:
|
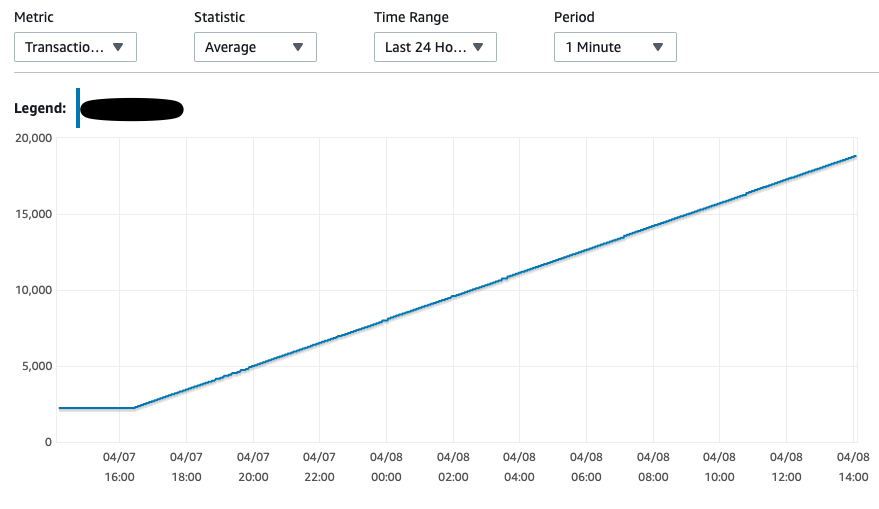
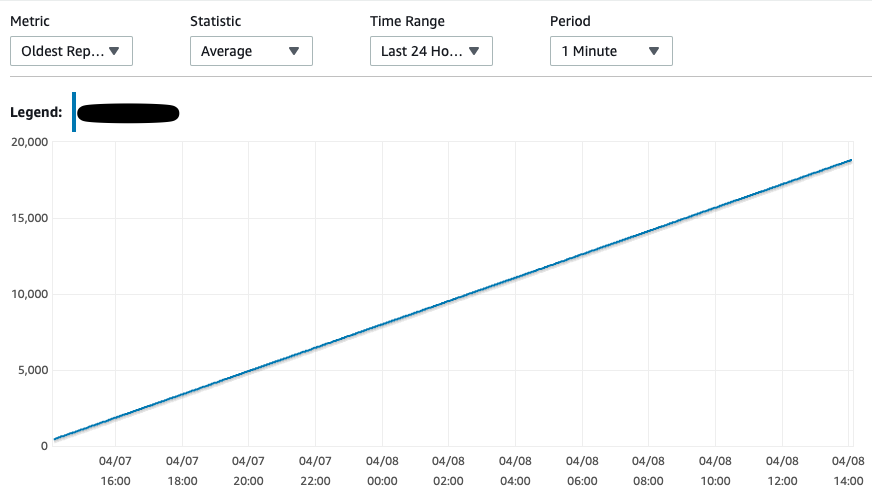
|
|
Thanks Till. Hi Jark, Any inputs, going through the code of 1.1 and 1.3 in the meantime. Thanks, Hemant On Thu, Apr 8, 2021 at 3:52 PM Till Rohrmann <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |