flink 1.7.2 freezes, waiting indefinitely for the buffer availability

flink 1.7.2 freezes, waiting indefinitely for the buffer availability

|
Hi, We are trying to run a very simple flink pipeline, which is used to sessionize events from a kinesis stream. Its an - event time window with a 30 min gap and - trigger interval of 15 mins and - late arrival time duration of 10 hrs This is how the graph looks. 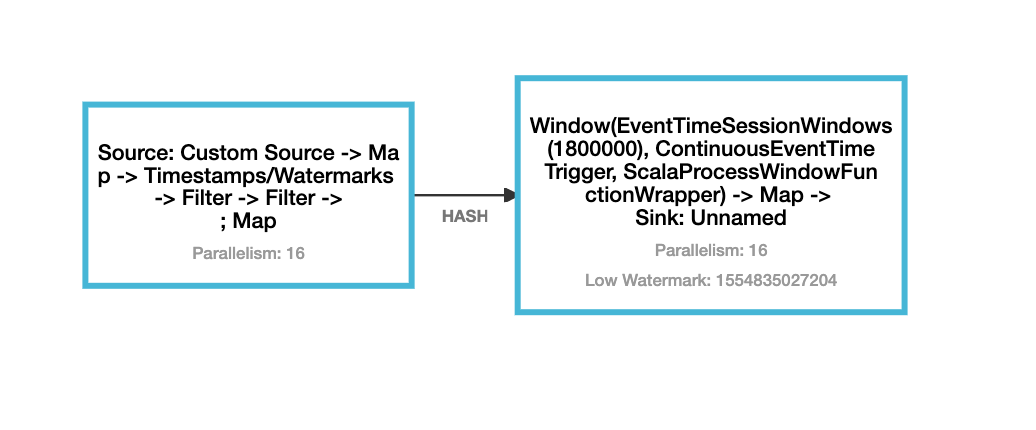 But what we are observing is that after 2-3 days of continuous run the job becomes progressively unstable and completely freezes. And the thread dump analysis revealed that it is actually indefinitely waiting at `LocalBufferPool.requestMemorySegment(LocalBufferPool.java:261)` for a memory segment to be available. And while it is waiting it holds and checkpoint lock, and therefore blocks all other threads as well, since they are all requesting for a lock on `checkpointLock` object. But we are not able to figure out why its not able to get any segment. Because there is no indication of backpressure, at least on the flink UI. And here are our job configurations:
Any ideas on what could be the issue? regards -Indraneel |
Re: flink 1.7.2 freezes, waiting indefinitely for the buffer availability
|
|
We are also seeing something very similar. Looks like a bug. It seems to get stuck in LocalBufferPool forever and the job has to be restarted. Is anyone else facing this too? On Tue, Apr 9, 2019 at 9:04 PM Indraneel R <[hidden email]> wrote:
|
|
|
Hi , Could you jstak the downstream Task (the Window) and have a look at what the window operator is doing?Best, Guowei Rahul Jain <[hidden email]> 于2019年4月10日周三 下午1:04写道:
|
Re: flink 1.7.2 freezes, waiting indefinitely for the buffer availability
|
|
Hi, We analysed that, and even some of the sink threads seem to be waiting on some lock. But it's not very clear what object it is waiting for. Async calls on Window(EventTimeSessionWindows(1800000), ContinuousEventTimeTrigger, ScalaProcessWindowFunctionWrapper) -> Map -> Sink: Unnamed (14/16) - priority:5 - threadId:0x00007fa5ac008800 - nativeId:0xf5e - nativeId (decimal):3934 - state:WAITING Attached is a complete thread dump. regards -Indraneel On Wed, Apr 10, 2019 at 10:43 AM Guowei Ma <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |