finite subset of an infinite data stream


|
Hello,
I need to extract a finite subset like a data buffer from an infinite data stream. The best way for me is to obtain a finite stream with data accumulated for a 1minute before (as example). But I not found any existing technique to do it.
As a possible ways how to do something near to a stream’s subset I see following cases: - some transformation operation like ‘take_while’ that produces new stream but able to switch one to FINNISHED state. Unfortunately I not found how to switch the state of a stream from a user code of transformation functions; - new DataStream or StreamSource constructors which allow to connect a data processing chain to the source stream. It may be something like mentioned take_while transform function or modified StreamSource.run method with data from the source stream.
That is I have two questions. 1) Is there any technique to extract accumulated data from a stream as a stream (to union it with another stream)? This is like pure buffer mode. 2) If the answer to first question is negative, is there something like take_while transformation or should I think about custom implementation of it? Is it possible to implement it without modification of the core of Flink?
Regards, Roman |
Re: finite subset of an infinite data stream
|
|
Hi! If you want to work on subsets of streams, the answer is usually to use windows, "stream.keyBy(...).timeWindow(Time.of(1, MINUTE))". The transformations that you want to make, do they fit into a window function? There are thoughts to introduce something like global time windows across the entire stream, inside which you can work more in a batch-style, but that is quite an extensive change to the core. Greetings, Stephan On Sun, Nov 8, 2015 at 5:15 PM, rss rss <[hidden email]> wrote:
|
|
|
Hello, thanks for the answer but windows produce periodical results. I used your example but the data source is changed to TCP stream: DataStream<String> text = env.socketTextStream("localhost", 2015, '\n'); DataStream<Tuple2<String, Integer>> wordCounts = text .flatMap(new LineSplitter()) .keyBy(0) .timeWindow(Time.of(5, TimeUnit.SECONDS)) .sum(1); wordCounts.print(); env.execute("WordCount Example"); I see an infinite results printing instead of the only list. The data source is following script: ----------------------------------------------------- #!/usr/bin/env ruby require 'socket' server = TCPServer.new 2015 loop do Thread.start(server.accept) do |client| puts Time.now.to_s + ': New client!' loop do client.puts "#{Time.now} #{[*('A'..'Z')].sample(3).join}" sleep rand(1000)/1000.0 end client.close end end ----------------------------------------------------- My purpose is to union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests. And the only result of union is interested. In this case I guess I need a way to terminate the stream. May be I wrong. Moreover it should be possible to link the streams by next request with other filtering criteria. That is create new data transformation chain after running of env.execute("WordCount Example"). Is it possible now? If not, is it possible with minimal changes of the core of Flink? Regards, Roman 2015-11-09 12:34 GMT+04:00 Stephan Ewen <[hidden email]>:
|
Re: finite subset of an infinite data stream
|
|
Hi! I don not really understand what exactly you want to do, especially the "union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests". If you want to work on substreams in general, there are two options: 1) Create the substream in a streaming window. You can "cut" the stream based on special records/events that signal that the subsequence is done. Have a look at the "Trigger" class for windows, it can react to elements and their contents: https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming_guide.html#windows-on-keyed-data-streams (secion on Advanced Windowing). 2) You can trigger sequences of batch jobs. The batch job data source (input format) can decide when to stop consuming the stream, at which point the remainder of the transformations run, and the batch job finishes. You can already run new transformation chains after each call to "env.execute()", once the execution finished, to implement the sequence of batch jobs. I would try and go for the windowing solution if that works, because that will give you better fault tolerance / high availability. In the repeated batch jobs case, you need to worry yourself about what happens when the driver program (that calls env.execute()) fails. Hope that helps... Greetings, Stephan On Mon, Nov 9, 2015 at 1:24 PM, rss rss <[hidden email]> wrote:
|
|
|
I think what you call "union" is a "connected stream" in Flink. Have a look at this example: https://gist.github.com/fhueske/4ea5422edb5820915fa4 It shows how to dynamically update a list of filters by external requests. Maybe that's what you are looking for? On Wed, Nov 11, 2015 at 12:15 PM, Stephan Ewen <[hidden email]> wrote:
|
|
|
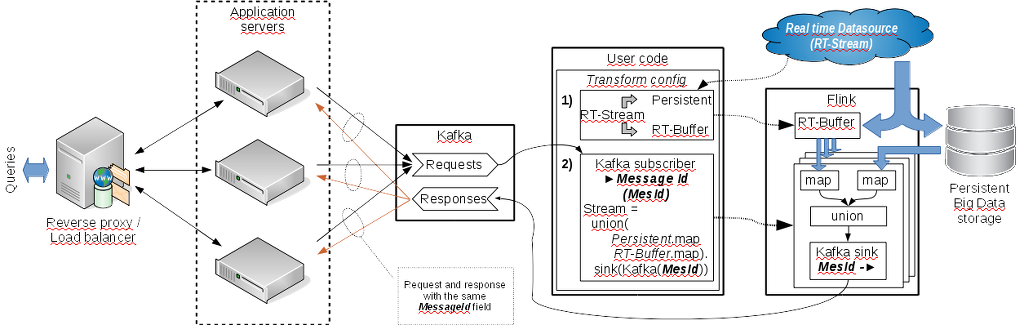
Hello, thanks, Stephan, but triggers are not that I searched. And BTW, the documentation is obsolete. There is no Count class now. I found CountTrigger only. Thanks Robert, your example may be useful for me but in some other point. I mentioned "union" as an ordinary union of similar data. It is the same as "union" in the datastream documentation. The task is very simple. We have an infinite stream of data from sensors, billing system etc. There is no matter what it is but it is infinite. We have to store the data in any persistent storage to be able to make analytical queries later. And there is a stream of user's analytical queries. But the stream of input data is big and time of saving in the persistent storage is big too. And we have not a very fast bigdata OLTP storage. That is the data extracted from the persistent storage by the user's requests probably will not contain actual data. We have to have some real time buffer (RT-Buffer in the schema) with actual data and have to union it with the data processing results from persistent storage (I don't speak about data deduplication and ordering now.). And of course the user's query are unpredictable regarding data filtering conditions. The attached schema is attempt to understand how it may be implemented with Flink. I tried to imagine how to implement it by Flink's streaming API but found obstacles. This schema is not first variant. It contains separated driver program to configure new jobs by user's queries. The reason I not found a way how to link the stream of user's queries with further data processing. But it is some near to https://gist.github.com/fhueske/4ea5422edb5820915fa4 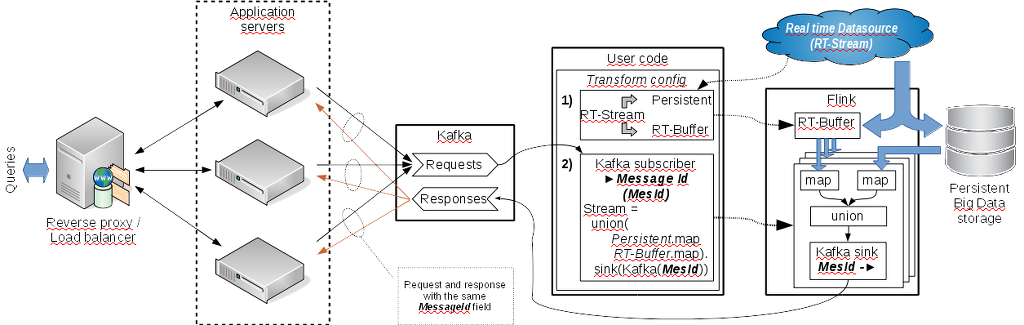 The main question is how to process each user's query combining it with actual data from the real time buffer and batch request to the persistent storage. Unfortunately I not found a decision in Streaming API only. Regards, Roman 2015-11-11 15:45 GMT+04:00 Robert Metzger <[hidden email]>:
|
|
|
Hi Roman, I've updated the documentation. It seems that it got out of sync. Thank you for notifying us about this. My colleague Aljoscha has some experimental code that is probably doing what you are looking for: A standing window (your RT-buffer) that you can query using a secondary stream (your user's queries). He'll post the code soon to this email thread. Regards, Robert On Wed, Nov 11, 2015 at 2:51 PM, rss rss <[hidden email]> wrote:
|
Re: finite subset of an infinite data stream
|
|
Hi,
I wrote a little example that could be what you are looking for: https://github.com/dataArtisans/query-window-example It basically implements a window operator with a modifiable window size that also allows querying the current accumulated window contents using a second input stream. There is a README file in the github repository, but please let me know if you need further explanations. Cheers, Aljoscha > On 18 Nov 2015, at 12:02, Robert Metzger <[hidden email]> wrote: > > Hi Roman, > > I've updated the documentation. It seems that it got out of sync. Thank you for notifying us about this. > > My colleague Aljoscha has some experimental code that is probably doing what you are looking for: A standing window (your RT-buffer) that you can query using a secondary stream (your user's queries). > He'll post the code soon to this email thread. > > Regards, > Robert > > > On Wed, Nov 11, 2015 at 2:51 PM, rss rss <[hidden email]> wrote: > Hello, > > thanks, Stephan, but triggers are not that I searched. And BTW, the documentation is obsolete. There is no Count class now. I found CountTrigger only. > > Thanks Robert, your example may be useful for me but in some other point. I mentioned "union" as an ordinary union of similar data. It is the same as "union" in the datastream documentation. > > The task is very simple. We have an infinite stream of data from sensors, billing system etc. There is no matter what it is but it is infinite. We have to store the data in any persistent storage to be able to make analytical queries later. And there is a stream of user's analytical queries. But the stream of input data is big and time of saving in the persistent storage is big too. And we have not a very fast bigdata OLTP storage. That is the data extracted from the persistent storage by the user's requests probably will not contain actual data. We have to have some real time buffer (RT-Buffer in the schema) with actual data and have to union it with the data processing results from persistent storage (I don't speak about data deduplication and ordering now.). And of course the user's query are unpredictable regarding data filtering conditions. > > The attached schema is attempt to understand how it may be implemented with Flink. I tried to imagine how to implement it by Flink's streaming API but found obstacles. This schema is not first variant. It contains separated driver program to configure new jobs by user's queries. The reason I not found a way how to link the stream of user's queries with further data processing. But it is some near to https://gist.github.com/fhueske/4ea5422edb5820915fa4 > > > <flink_streams.png> > > The main question is how to process each user's query combining it with actual data from the real time buffer and batch request to the persistent storage. Unfortunately I not found a decision in Streaming API only. > > Regards, > Roman > > 2015-11-11 15:45 GMT+04:00 Robert Metzger <[hidden email]>: > I think what you call "union" is a "connected stream" in Flink. Have a look at this example: https://gist.github.com/fhueske/4ea5422edb5820915fa4 > It shows how to dynamically update a list of filters by external requests. > Maybe that's what you are looking for? > > > > On Wed, Nov 11, 2015 at 12:15 PM, Stephan Ewen <[hidden email]> wrote: > Hi! > > I don not really understand what exactly you want to do, especially the "union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests". > > If you want to work on substreams in general, there are two options: > > 1) Create the substream in a streaming window. You can "cut" the stream based on special records/events that signal that the subsequence is done. Have a look at the "Trigger" class for windows, it can react to elements and their contents: > > https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming_guide.html#windows-on-keyed-data-streams (secion on Advanced Windowing). > > > 2) You can trigger sequences of batch jobs. The batch job data source (input format) can decide when to stop consuming the stream, at which point the remainder of the transformations run, and the batch job finishes. > You can already run new transformation chains after each call to "env.execute()", once the execution finished, to implement the sequence of batch jobs. > > > I would try and go for the windowing solution if that works, because that will give you better fault tolerance / high availability. In the repeated batch jobs case, you need to worry yourself about what happens when the driver program (that calls env.execute()) fails. > > > Hope that helps... > > Greetings, > Stephan > > > > On Mon, Nov 9, 2015 at 1:24 PM, rss rss <[hidden email]> wrote: > Hello, > > thanks for the answer but windows produce periodical results. I used your example but the data source is changed to TCP stream: > > DataStream<String> text = env.socketTextStream("localhost", 2015, '\n'); > DataStream<Tuple2<String, Integer>> wordCounts = > text > .flatMap(new LineSplitter()) > .keyBy(0) > .timeWindow(Time.of(5, TimeUnit.SECONDS)) > .sum(1); > > wordCounts.print(); > env.execute("WordCount Example"); > > I see an infinite results printing instead of the only list. > > The data source is following script: > ----------------------------------------------------- > #!/usr/bin/env ruby > > require 'socket' > > server = TCPServer.new 2015 > loop do > Thread.start(server.accept) do |client| > puts Time.now.to_s + ': New client!' > loop do > client.puts "#{Time.now} #{[*('A'..'Z')].sample(3).join}" > sleep rand(1000)/1000.0 > end > client.close > end > end > ----------------------------------------------------- > > My purpose is to union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests. And the only result of union is interested. In this case I guess I need a way to terminate the stream. May be I wrong. > > Moreover it should be possible to link the streams by next request with other filtering criteria. That is create new data transformation chain after running of env.execute("WordCount Example"). Is it possible now? If not, is it possible with minimal changes of the core of Flink? > > Regards, > Roman > > 2015-11-09 12:34 GMT+04:00 Stephan Ewen <[hidden email]>: > Hi! > > If you want to work on subsets of streams, the answer is usually to use windows, "stream.keyBy(...).timeWindow(Time.of(1, MINUTE))". > > The transformations that you want to make, do they fit into a window function? > > There are thoughts to introduce something like global time windows across the entire stream, inside which you can work more in a batch-style, but that is quite an extensive change to the core. > > Greetings, > Stephan > > > On Sun, Nov 8, 2015 at 5:15 PM, rss rss <[hidden email]> wrote: > Hello, > > > I need to extract a finite subset like a data buffer from an infinite data stream. The best way for me is to obtain a finite stream with data accumulated for a 1minute before (as example). But I not found any existing technique to do it. > > > As a possible ways how to do something near to a stream’s subset I see following cases: > > - some transformation operation like ‘take_while’ that produces new stream but able to switch one to FINISHED state. Unfortunately I not found how to switch the state of a stream from a user code of transformation functions; > > - new DataStream or StreamSource constructors which allow to connect a data processing chain to the source stream. It may be something like mentioned take_while transform function or modified StreamSource.run method with data from the source stream. > > > That is I have two questions. > > 1) Is there any technique to extract accumulated data from a stream as a stream (to union it with another stream)? This is like pure buffer mode. > > 2) If the answer to first question is negative, is there something like take_while transformation or should I think about custom implementation of it? Is it possible to implement it without modification of the core of Flink? > > > Regards, > > Roman > > > > > > > |
|
|
Hello Aljoscha,
very thanks. I tried to build your example but have an obstacle with org.apache.flink.runtime.state.AbstractStateBackend class. Where to get it? I guess it stored in your local branch only. Would you please to send me patches for public branch or share the branch with me? Best regards, Roman 2015-11-18 17:24 GMT+04:00 Aljoscha Krettek <[hidden email]>: Hi, |
Re: finite subset of an infinite data stream
|
|
Hi,
I’m very sorry, yes you would need my custom branch: https://github.com/aljoscha/flink/commits/state-enhance Cheers, Aljoscha > On 20 Nov 2015, at 10:13, rss rss <[hidden email]> wrote: > > Hello Aljoscha, > > very thanks. I tried to build your example but have an obstacle with org.apache.flink.runtime.state.AbstractStateBackend class. Where to get it? I guess it stored in your local branch only. Would you please to send me patches for public branch or share the branch with me? > > Best regards, > Roman > > > 2015-11-18 17:24 GMT+04:00 Aljoscha Krettek <[hidden email]>: > Hi, > I wrote a little example that could be what you are looking for: https://github.com/dataArtisans/query-window-example > > It basically implements a window operator with a modifiable window size that also allows querying the current accumulated window contents using a second input stream. > > There is a README file in the github repository, but please let me know if you need further explanations. > > Cheers, > Aljoscha > > > On 18 Nov 2015, at 12:02, Robert Metzger <[hidden email]> wrote: > > > > Hi Roman, > > > > I've updated the documentation. It seems that it got out of sync. Thank you for notifying us about this. > > > > My colleague Aljoscha has some experimental code that is probably doing what you are looking for: A standing window (your RT-buffer) that you can query using a secondary stream (your user's queries). > > He'll post the code soon to this email thread. > > > > Regards, > > Robert > > > > > > On Wed, Nov 11, 2015 at 2:51 PM, rss rss <[hidden email]> wrote: > > Hello, > > > > thanks, Stephan, but triggers are not that I searched. And BTW, the documentation is obsolete. There is no Count class now. I found CountTrigger only. > > > > Thanks Robert, your example may be useful for me but in some other point. I mentioned "union" as an ordinary union of similar data. It is the same as "union" in the datastream documentation. > > > > The task is very simple. We have an infinite stream of data from sensors, billing system etc. There is no matter what it is but it is infinite. We have to store the data in any persistent storage to be able to make analytical queries later. And there is a stream of user's analytical queries. But the stream of input data is big and time of saving in the persistent storage is big too. And we have not a very fast bigdata OLTP storage. That is the data extracted from the persistent storage by the user's requests probably will not contain actual data. We have to have some real time buffer (RT-Buffer in the schema) with actual data and have to union it with the data processing results from persistent storage (I don't speak about data deduplication and ordering now.). And of course the user's query are unpredictable regarding data filtering conditions. > > > > The attached schema is attempt to understand how it may be implemented with Flink. I tried to imagine how to implement it by Flink's streaming API but found obstacles. This schema is not first variant. It contains separated driver program to configure new jobs by user's queries. The reason I not found a way how to link the stream of user's queries with further data processing. But it is some near to https://gist.github.com/fhueske/4ea5422edb5820915fa4 > > > > > > <flink_streams.png> > > > > The main question is how to process each user's query combining it with actual data from the real time buffer and batch request to the persistent storage. Unfortunately I not found a decision in Streaming API only. > > > > Regards, > > Roman > > > > 2015-11-11 15:45 GMT+04:00 Robert Metzger <[hidden email]>: > > I think what you call "union" is a "connected stream" in Flink. Have a look at this example: https://gist.github.com/fhueske/4ea5422edb5820915fa4 > > It shows how to dynamically update a list of filters by external requests. > > Maybe that's what you are looking for? > > > > > > > > On Wed, Nov 11, 2015 at 12:15 PM, Stephan Ewen <[hidden email]> wrote: > > Hi! > > > > I don not really understand what exactly you want to do, especially the "union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests". > > > > If you want to work on substreams in general, there are two options: > > > > 1) Create the substream in a streaming window. You can "cut" the stream based on special records/events that signal that the subsequence is done. Have a look at the "Trigger" class for windows, it can react to elements and their contents: > > > > https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming_guide.html#windows-on-keyed-data-streams (secion on Advanced Windowing). > > > > > > 2) You can trigger sequences of batch jobs. The batch job data source (input format) can decide when to stop consuming the stream, at which point the remainder of the transformations run, and the batch job finishes. > > You can already run new transformation chains after each call to "env.execute()", once the execution finished, to implement the sequence of batch jobs. > > > > > > I would try and go for the windowing solution if that works, because that will give you better fault tolerance / high availability. In the repeated batch jobs case, you need to worry yourself about what happens when the driver program (that calls env.execute()) fails. > > > > > > Hope that helps... > > > > Greetings, > > Stephan > > > > > > > > On Mon, Nov 9, 2015 at 1:24 PM, rss rss <[hidden email]> wrote: > > Hello, > > > > thanks for the answer but windows produce periodical results. I used your example but the data source is changed to TCP stream: > > > > DataStream<String> text = env.socketTextStream("localhost", 2015, '\n'); > > DataStream<Tuple2<String, Integer>> wordCounts = > > text > > .flatMap(new LineSplitter()) > > .keyBy(0) > > .timeWindow(Time.of(5, TimeUnit.SECONDS)) > > .sum(1); > > > > wordCounts.print(); > > env.execute("WordCount Example"); > > > > I see an infinite results printing instead of the only list. > > > > The data source is following script: > > ----------------------------------------------------- > > #!/usr/bin/env ruby > > > > require 'socket' > > > > server = TCPServer.new 2015 > > loop do > > Thread.start(server.accept) do |client| > > puts Time.now.to_s + ': New client!' > > loop do > > client.puts "#{Time.now} #{[*('A'..'Z')].sample(3).join}" > > sleep rand(1000)/1000.0 > > end > > client.close > > end > > end > > ----------------------------------------------------- > > > > My purpose is to union an infinite real time data stream with filtered persistent data where the condition of filtering is provided by external requests. And the only result of union is interested. In this case I guess I need a way to terminate the stream. May be I wrong. > > > > Moreover it should be possible to link the streams by next request with other filtering criteria. That is create new data transformation chain after running of env.execute("WordCount Example"). Is it possible now? If not, is it possible with minimal changes of the core of Flink? > > > > Regards, > > Roman > > > > 2015-11-09 12:34 GMT+04:00 Stephan Ewen <[hidden email]>: > > Hi! > > > > If you want to work on subsets of streams, the answer is usually to use windows, "stream.keyBy(...).timeWindow(Time.of(1, MINUTE))". > > > > The transformations that you want to make, do they fit into a window function? > > > > There are thoughts to introduce something like global time windows across the entire stream, inside which you can work more in a batch-style, but that is quite an extensive change to the core. > > > > Greetings, > > Stephan > > > > > > On Sun, Nov 8, 2015 at 5:15 PM, rss rss <[hidden email]> wrote: > > Hello, > > > > > > I need to extract a finite subset like a data buffer from an infinite data stream. The best way for me is to obtain a finite stream with data accumulated for a 1minute before (as example). But I not found any existing technique to do it. > > > > > > As a possible ways how to do something near to a stream’s subset I see following cases: > > > > - some transformation operation like ‘take_while’ that produces new stream but able to switch one to FINISHED state. Unfortunately I not found how to switch the state of a stream from a user code of transformation functions; > > > > - new DataStream or StreamSource constructors which allow to connect a data processing chain to the source stream. It may be something like mentioned take_while transform function or modified StreamSource.run method with data from the source stream. > > > > > > That is I have two questions. > > > > 1) Is there any technique to extract accumulated data from a stream as a stream (to union it with another stream)? This is like pure buffer mode. > > > > 2) If the answer to first question is negative, is there something like take_while transformation or should I think about custom implementation of it? Is it possible to implement it without modification of the core of Flink? > > > > > > Regards, > > > > Roman > > > > > > > > > > > > > > > > |
|
|
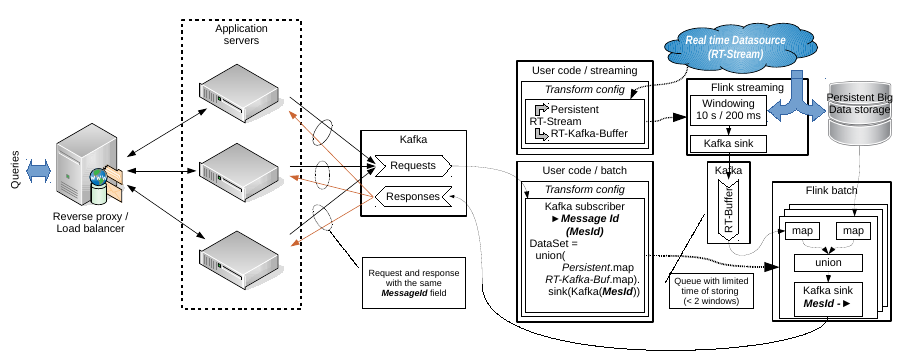
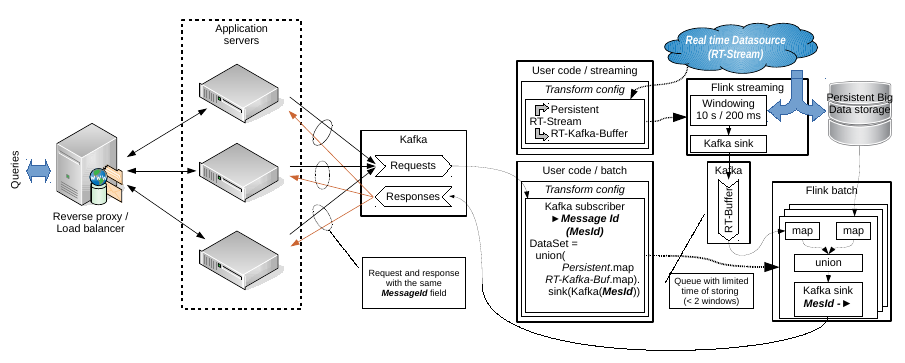
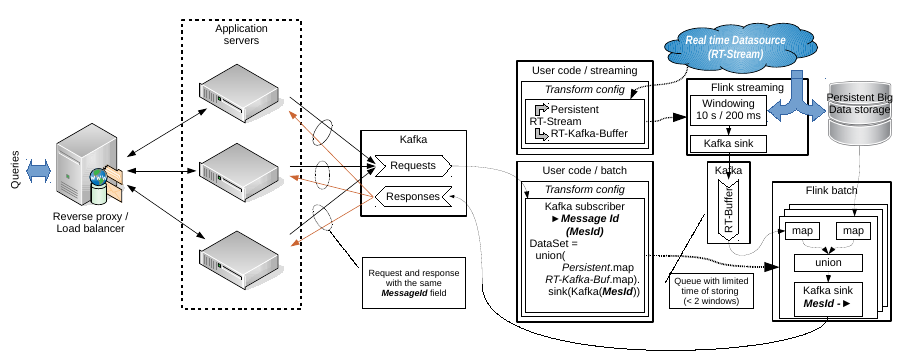
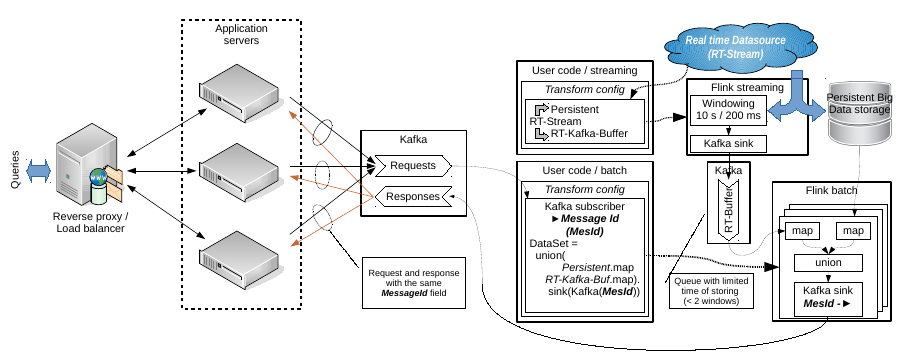
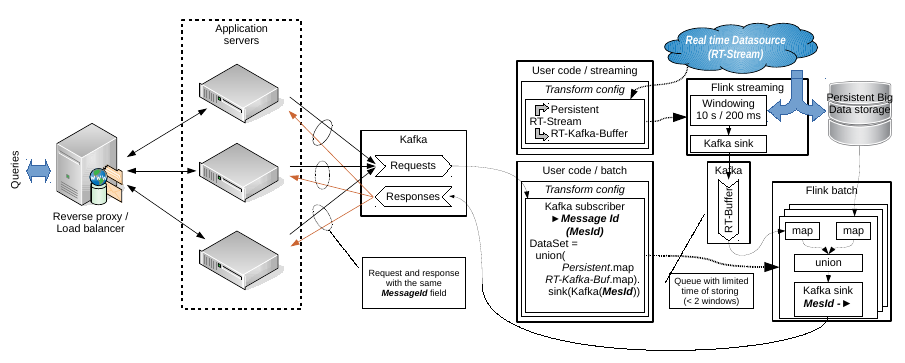
Hello Aljoscha, Thanks, I looked your code. I think, It is really useful for getting real time data from some sensors. And as a simple example it may be considered in a modern Internet of Thing context. E.g. there are some temperature sensor or sensor of water flow; and I want to build simple application when the data flow from the sensors is saved to persistent storage but a small real time buffer I want to use for visualizing on a display by a query. But at the same time my question have a second part. I need to link the real time data with data from persistent storage. And I don't see how your example may help in this. Let the input query contains some data fetch condition. In this case we have to build a separate DataSet or DataStream to a persistent storage with specified conditions. It may be SQL or simple map(...).filter("something"). But main obstacle is how to configure new data processing schema been inside the current stream transformation. E.g. being inside the connected query stream map function. Week ago I have prepared other schema of my task solving with separation of streaming and batch subsystems. See the attached image. It may be changed accordingly your example but I don't see other way to resolve the task than separate queries to persistent storage in batch part. 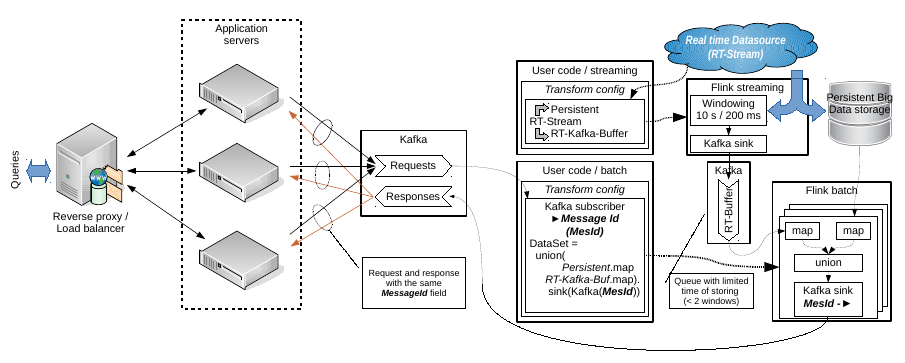 And note, this schema describes an idea about how to emulate a real time buffer by means of Kafka. Windowed stream infinitely produces data sequences and sinks ones into an external queue with limited storing time or without storing in whole. Any consumers connected to the queue are received an actual data. I don't like this idea because it is excess network communication but it looks workable. BTW: it is something like lambda/kappa architecture implementation. I don't like these terms but actually it is. Best regards, Roman 2015-11-20 13:26 GMT+04:00 Aljoscha Krettek <[hidden email]>: Hi, |
|
|
Hello, I have prepared a prototype of the batch subsystem that described in the previous mail.
https://github.com/rssdev10/flink-experiments/tree/init_by_kafka_sink_kafka It does not contain correct Kafka's serialization/deserialization
because I didn't see how to do it yet. But it contains a code for running Flink batch processing by a
message from Kafka queue -
https://github.com/rssdev10/flink-experiments/blob/init_by_kafka_sink_kafka/src/main/java/proto/flink/batch/Consumer.java
. This code is based on Kafka’s examples.Is it correct? Unfortunately the Flink's documentation does not contain examples of a custom sink implementation https://ci.apache.org/projects/flink/flink-docs-master/apis/programming_guide.html#data-sinks . Best regards, Roman 2015-11-20 16:05 GMT+03:00 rss rss <[hidden email]>:
|
|
|
Hi Roman,
I've looked through your code here: https://github.com/rssdev10/flink-experiments/blob/init_by_kafka_sink_kafka/src/main/java/proto/flink/batch/Consumer.java The implementation is not very efficient. Flink is not like spark where the job's driver is constantly interacting with the program running in the cluster. Flink will generate a plan from your code and submit it to the cluster [1]. Your code is submitting a new plan for every message in Kafka into the cluster. It will be faster to process the data locally. I still think that you can use the DataStream API of Flink. Maybe use this example as a starting point: then, use the "stream" object to perform your transformations. The output format looks good! On Sun, Nov 22, 2015 at 8:52 PM, rss rss <[hidden email]> wrote:
|
|
|
Hello Robert,
thank you for the answer. I understand the idea of stream usage but I don't understand how to use it in my task. Aljoscha wrote an example of data parts extraction by external queries. It is very useful but not enough. I have conditional queries. Simple example 'get data from the specified period' by a specified client (or sensor, or something other)'. Flink streaming API allows to configure a stream to access to a persistent storage. E.g. some DBMS with SQL interface. In this case I have to configure the stream with SQL query in a constructor like 'select * from data where timestamp > now() - 1day AND clientId == id'. But '1 day' and 'id' are parameters from the input query. I don't able to configure all possible steams to produce all possible data combinations. Therefore I decided to use batch part for running a transformation process for each input query with a list of conditions. If it possible I will glad to use streaming API only. But there are no ideas other than batch API usage. Best regards, Roman 2015-11-25 21:51 GMT+04:00 Robert Metzger <[hidden email]>:
|
Re: finite subset of an infinite data stream
|
|
Hi Roman! Is it possible to do the following: You have a queue (Kafka) with the user requests. Then you have a Flink job that reads from that queue and does a map() over the query stream. In the map() function, you do the call to the database, like this: val queryStream : DataStream[Query] = readQueriesFromKafka(); val resultStream : DataStream[Result] = queryStream.map(new RichMapFunction[Query, Result]() { var connection: DbConnection = _ val queryStatement: PreparedStatement = _ def open(cfg: Configuration) : Unit = { connection = // connect to data base query = // prepare query statement } def map(query: Query) : Result = { connection.runQuery(queryStatement, query.param1, query.param2, ...); } } Since the queries have quite a bit of latency, you could try and run them with a very parallelism, or use a threadpool executor or so... Greetings, Stephan On Thu, Nov 26, 2015 at 11:06 AM, rss rss <[hidden email]> wrote:
|
|
|
Hello Stephan, very thanks, RichMapFunction with overlapped "open" method is really that I need.2015-11-27 15:03 GMT+03:00 Stephan Ewen <[hidden email]>:
|
| Free forum by Nabble | Edit this page |