checkpoint stuck with rocksdb statebackend and s3 filesystem


|
Hi all,
Last weekend, my flink job's checkpoint start failing because of timeout. I have no idea what happened, but I collect some informations about my cluster and job. Hope someone can give me advices or hints about the problem that I encountered. My cluster version is flink-release-1.4.0. Cluster has 10 TMs, each has 4 cores. These machines are ec2 spot instances. The job's parallelism is set as 32, using rocksdb as state backend and s3 presto as checkpoint file system. The state's size is nearly 15gb and still grows day-by-day. Normally, It takes 1.5 mins to finish the whole checkpoint process. The timeout configuration is set as 10 mins. 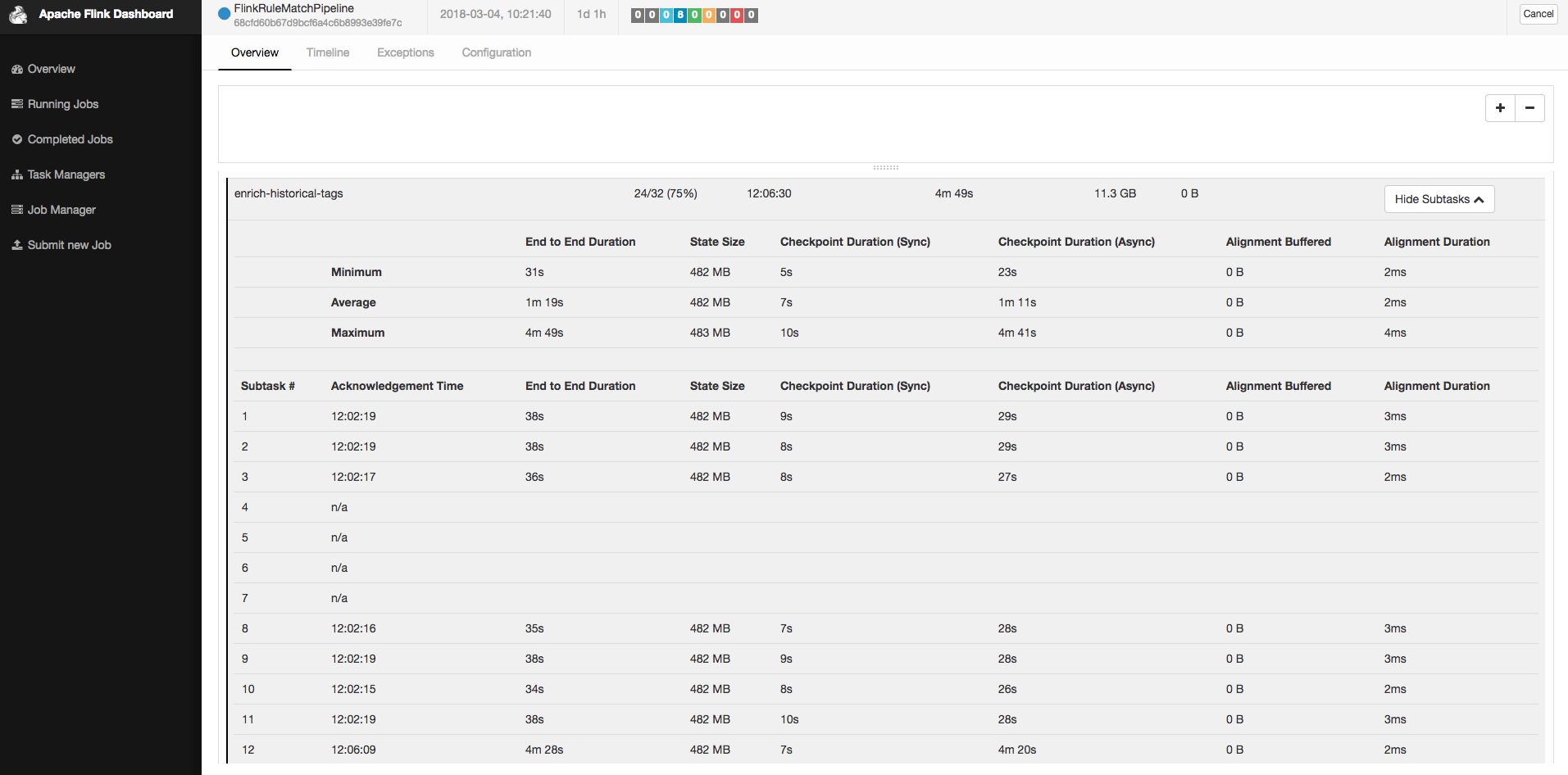 As the picture shows, not each subtask of checkpoint broke caused by timeout, but each machine has ever broken for all its subtasks during last weekend. Some machines recovered by themselves and some machines recovered after I restarted them. I record logs, stack trace and snapshot for machine's status (CPU, IO, Network, etc.) for both good and bad machine. If there is a need for more informations, please let me know. Thanks in advance. Best Regards, Tony Wei. |
Re: checkpoint stuck with rocksdb statebackend and s3 filesystem
|
|
Hi,
quick question: what is your exact checkpointing configuration? In particular, what is your value for the maximum parallel checkpoints and the minimum time interval to wait between two checkpoints? Best, Stefan > Am 05.03.2018 um 06:34 schrieb Tony Wei <[hidden email]>: > > Hi all, > > Last weekend, my flink job's checkpoint start failing because of timeout. I have no idea what happened, but I collect some informations about my cluster and job. Hope someone can give me advices or hints about the problem that I encountered. > > My cluster version is flink-release-1.4.0. Cluster has 10 TMs, each has 4 cores. These machines are ec2 spot instances. The job's parallelism is set as 32, using rocksdb as state backend and s3 presto as checkpoint file system. > The state's size is nearly 15gb and still grows day-by-day. Normally, It takes 1.5 mins to finish the whole checkpoint process. The timeout configuration is set as 10 mins. > > <chk_snapshot.png> > > As the picture shows, not each subtask of checkpoint broke caused by timeout, but each machine has ever broken for all its subtasks during last weekend. Some machines recovered by themselves and some machines recovered after I restarted them. > > I record logs, stack trace and snapshot for machine's status (CPU, IO, Network, etc.) for both good and bad machine. If there is a need for more informations, please let me know. Thanks in advance. > > Best Regards, > Tony Wei. > <bad_tm_log.log><bad_tm_pic.png><bad_tm_stack.log><good_tm_log.log><good_tm_pic.png><good_tm_stack.log> |
|
|
Hi Stefan, Here is my checkpointing configuration.
Best Regards, Tony Wei 2018-03-05 21:30 GMT+08:00 Stefan Richter <[hidden email]>: Hi, |
Re: checkpoint stuck with rocksdb statebackend and s3 filesystem
|
|
Hi,
thanks for all the info. I had a look into the problem and opened https://issues.apache.org/jira/browse/FLINK-8871 to fix this. From your stack trace, you can see many checkpointing threads are running on your TM for checkpoints that have already timed out, and I think this cascades and slows down everything. Seems like the implementation of some features like checkpoint timeouts and not failing tasks from checkpointing problems overlooked that we also require to properly communicate that checkpoint cancellation to all task, which was not needed before. Best, Stefan
|
|
|
Hi Stefan, I see. That explains why the loading of machines grew up. However, I think it is not the root cause that led to these consecutive checkpoint timeout. As I said in my first mail, the checkpointing progress usually took 1.5 mins to upload states, and this operator and kafka consumer are only two operators that have states in my pipeline. In the best case, I should never encounter the timeout problem that only caused by lots of pending checkpointing threads that have already timed out. Am I right? Since these logging and stack trace was taken after nearly 3 hours from the first checkpoint timeout, I'm afraid that we couldn't actually find out the root cause for the first checkpoint timeout. Because we are preparing to make this pipeline go on production, I was wondering if you could help me find out where the root cause happened: bad machines or s3 or flink-s3-presto packages or flink checkpointing thread. It will be great if we can find it out from those informations the I provided, or a hypothesis based on your experience is welcome as well. The most important thing is that I have to decide whether I need to change my persistence filesystem or use another s3 filesystem package, because it is the last thing I want to see that the checkpoint timeout happened very often. Thank you very much for all your advices. Best Regards, Tony Wei 2018-03-06 1:07 GMT+08:00 Stefan Richter <[hidden email]>:
|
|
|
Hi Tony, Sorry for jump into, one thing I want to remind is that from the log you provided it looks like you are using "full checkpoint", this means that the state data that need to be checkpointed and transvered to s3 will grow over time, and even for the first checkpoint it performance is slower that incremental checkpoint (because it need to iterate all the record from the rocksdb using the RocksDBMergeIterator). Maybe you can try out "incremental checkpoint", it could help you got a better performance.
Best Regards, Sihua Zhou
发自网易邮箱大师
On 03/6/2018 10:34,[hidden email] wrote:
|
|
|
Hi Sihua, Thanks for your suggestion. "incremental checkpoint" is what I will try out next and I know it will give a better performance. However, it might not solve this issue completely, because as I said, the average end to end latency of checkpointing is less than 1.5 mins currently, and it is far from my timeout configuration. I believe "incremental checkpoint" will reduce the latency and make this issue might occur seldom, but I can't promise it won't happen again if I have bigger states growth in the future. Am I right? Best Regards, Tony Wei 2018-03-06 10:55 GMT+08:00 周思华 <[hidden email]>:
|
|
|
Hi Tony, About to your question: average end to end latency of checkpoint is less than 1.5 mins, doesn't means that checkpoint won't timeout. indeed, it determined byt the max end to end latency (the slowest one), a checkpoint truly completed only after all task's checkpoint have completed. About to the problem: after a second look at the info you privode, we can found from the checkpoint detail picture that there is one task which cost 4m20s to transfer it snapshot (about 482M) to s3 and there are 4 others tasks didn't complete the checkpoint yet. And from the bad_tm_pic.png vs good_tm_pic.png, we can found that on "bad tm" the network performance is far less than the "good tm" (-15 MB vs -50MB). So I guss the network is a problem, sometimes it failed to send 500M data to s3 in 10 minutes. (maybe you need to check whether the network env is stable) About the solution: I think incremental checkpoint can help you a lot, it will only send the new data each checkpoint, but you are right if the increment state size is huger than 500M, it might cause the timeout problem again (because of the bad network performance). Best Regards, Sihua Zhou
发自网易邮箱大师
On 03/6/2018 13:02,[hidden email] wrote:
|
|
|
Hi Sihua,
Sorry for my poor expression. What I mean is the average duration of "completed" checkpoints, so I guess there are some problems that make some subtasks of checkpoint take so long, even more than 10 mins.
That is what I concerned. Because I can't determine if checkpoint is stuck makes network performance worse or network performance got worse makes checkpoint stuck. Although I provided one "bad machine" and one "good machine", that doesn't mean bad machine is always bad and good machine is always good. See the attachments. All of my TMs met this problem at least once from last weekend until now. Some machines recovered by themselves and some recovered after I restarted them. Best Regards, Tony Wei 2018-03-06 13:41 GMT+08:00 周思华 <[hidden email]>:
|
|
|
In reply to this post by gerryzhou
Sent to the wrong mailing list. Forward it to the correct one. ---------- Forwarded message ---------- From: Tony Wei <[hidden email]> Date: 2018-03-06 14:43 GMT+08:00 Subject: Re: checkpoint stuck with rocksdb statebackend and s3 filesystem To: 周思华 <[hidden email]>, Stefan Richter <[hidden email]> Cc: "[hidden email]" <[hidden email]> Hi Sihua, Thanks a lot. I will try to find out the problem from machines' environment. If you and Stefan have any new suggestions or thoughts, please advise me. Thank you ! Best Regards, Tony Wei 2018-03-06 14:34 GMT+08:00 周思华 <[hidden email]>:
|
|
|
Hi Sihua, You are right. The incremental checkpoint might release machine from high cpu loading and make the bad machines recover quickly, but I was wondering why the first checkpoint failed by timeout. You can see when the bad machine recovered, the cpu loading for each checkpoint is not so high, although there were still peeks in each checkpoint happened. I think the high cpu loading that might be caused by those timeout checkpointing threads is not the root cause. I will use the incremental checkpoint eventually but I will decide if change my persistence filesystem after we find out the root cause or stop the investigation and make the conclusion in this mailing thread. What do you think? Best Regards, Tony Wei 2018-03-06 15:13 GMT+08:00 周思华 <[hidden email]>:
|
|
|
Hi Stefan, Sihua, TLDR; after the experiment, I found that this problem might not about s3 filesystem or network io with s3. It might caused by rocksdb and io performance, but I still can't recognize who caused this problem. For more specific details, I have to introduce my flink application's detail and what I found in the experiment. The disks I used for EC2 are SSD, but they are EBS. For the application detail, there is only one keyed ProcessFunction with ValueState with scala collection data type, which represents the counting by event and date This operator with receive two type of message: one is event message and the other is overwrite state message When operator received an event message, it would update the corresponding value by event and client time and emit the event to the next operator with the "whole" collection, that's why I used ValueState not MapState or ListState. When operator received a overwrite state message, it would overwrite the corresponding value in the state. This is the design that we want to replay the state constructed by the new rules. Moreover, my key is something like user cookie, and I have a timer callback to remove those out-dated state, for example: I'm only care about the state in 6 months. For the experiment, I tried to catch the first failure to find out some cues, so I extended the checkpoint interval to a long time and use savepoint. I know savepoint is not actually same as checkpoint, but I guess the parts of store state and upload to remote filesystem are similar. After some savepoints triggered, I found that asynchronous part was stuck in full snapshot operation and time triggers in that machine were also stock and blocked the operator to process element. I recalled that I had replayed lots of states for 60 days in 4 ~ 5 hours, and the first problem happened during the replay procedure. It is just a coincidence that the callback from those keys that I replayed happened when I run the experiment. However, when I tried to disable all checkpoints and savepoints to observed if the massive keys to access rocksdb get stuck, I found the problem was disappeared. Moreover, I roll back to the original setting that checkpoint got stuck. The problem didn't happened again yet. In summary, I sill can't tell where the problem happened, since the io performance didn't touch the limitation and the problem couldn't reproduce based on the same initial states. I decide to try out incremental checkpoint to reduce this risk. I will reopen this thread with more information I can provide when the problem happen again. If you have any suggestion about my implementation that might leads to some problems or about this issue, please advice me. Thank you ver much for taking your time to pay attention on this issue!! = ) p.s. the attachment is about the experiment I mentioned above. I didn't record the stack trace because the only difference is only Time Trigger's state were runnable and the operator were blocked. Best Regards, Tony Wei 2018-03-06 17:00 GMT+08:00 周思华 <[hidden email]>:
|
Re: checkpoint stuck with rocksdb statebackend and s3 filesystem
|
|
Hi,
if processing and checkpointing are stuck in RocksDB, this could indeed hint to a problem with your IO system. The comment about using EBS could be important, as it might be a bad idea from a performance point of view to run RocksDB on EBS; did you ever compare against running it on local SSDs? Best, Stefan
|
|
|
Hi Stefan, We prepared to run it on local SSDs yesterday. However, as I said, the problem just disappeared. Of course we will replace it to local SSDs, but I'm afraid that I might be able to reproduce the same situation for both environments to compare the difference. Best Regards, Tony Wei. 2018-03-09 16:59 GMT+08:00 Stefan Richter <[hidden email]>:
|
|
|
Hi Stefan, Sihua, We finally found out the root cause. Just as you said, why the performance had been downgraded is due to EBS. My team and I wasn't familiar with EBS before. We thought its performance is not so weak as the monitor showed us. But we visited this page [1] and found that we had a big misunderstanding about EBS. All in all, our checkpoint procedure hit the burst IO performance over the maximum duration and made the IO performance downgraded. We have replaced to local SSDs and enabled incremental checkpoint mechanism as well. Our job has run healthily for more than two weeks. Thank you all for helping me to investigate and solve this issue. Best Regards, Tony Wei 2018-03-09 17:47 GMT+08:00 Tony Wei <[hidden email]>:
|
Re: checkpoint stuck with rocksdb statebackend and s3 filesystem
|
|
Cool, that is good news! Thanks for sharing this information with us,
Best, Stefan
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |