Why did the Flink Cluster JM crash?

Why did the Flink Cluster JM crash?

|
Hi colleagues, I started the cluster all fine. Started the Beam app running in the Flink Cluster fine. Dashboard showed all tasks being consumed and open for business. I started sending data to the Beam app, and all of the sudden the Flink JM crashed. Exceptions below. Thanks+regards Amir java.lang.RuntimeException: Pipeline execution failed at org.apache.beam.runners.flink.FlinkRunner.run(FlinkRunner.java:113) at org.apache.beam.runners.flink.FlinkRunner.run(FlinkRunner.java:48) at org.apache.beam.sdk.Pipeline.run(Pipeline.java:183) at benchmark.flinkspark.flink.BenchBeamRunners.main(BenchBeamRunners.java:622) //p.run(); at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:505) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:403) at org.apache.flink.client.program.Client.runBlocking(Client.java:248) at org.apache.flink.client.CliFrontend.executeProgramBlocking(CliFrontend.java:866) at org.apache.flink.client.CliFrontend.run(CliFrontend.java:333) at org.apache.flink.client.CliFrontend.parseParameters(CliFrontend.java:1189) at org.apache.flink.client.CliFrontend.main(CliFrontend.java:1239) Caused by: org.apache.flink.client.program.ProgramInvocationException: The program execution failed: Communication with JobManager failed: Lost connection to the JobManager. at org.apache.flink.client.program.Client.runBlocking(Client.java:381) at org.apache.flink.client.program.Client.runBlocking(Client.java:355) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:65) at org.apache.beam.runners.flink.FlinkPipelineExecutionEnvironment.executePipeline(FlinkPipelineExecutionEnvironment.java:118) at org.apache.beam.runners.flink.FlinkRunner.run(FlinkRunner.java:110) ... 14 more Caused by: org.apache.flink.runtime.client.JobExecutionException: Communication with JobManager failed: Lost connection to the JobManager. at org.apache.flink.runtime.client.JobClient.submitJobAndWait(JobClient.java:140) at org.apache.flink.client.program.Client.runBlocking(Client.java:379) ... 18 more Caused by: org.apache.flink.runtime.client.JobClientActorConnectionTimeoutException: Lost connection to the JobManager. at org.apache.flink.runtime.client.JobClientActor.handleMessage(JobClientActor.java:244) at org.apache.flink.runtime.akka.FlinkUntypedActor.handleLeaderSessionID(FlinkUntypedActor.java:88) at org.apache.flink.runtime.akka.FlinkUntypedActor.onReceive(FlinkUntypedActor.java:68) at akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:167) at akka.actor.Actor$class.aroundReceive(Actor.scala:465) at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:97) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516) at akka.actor.ActorCell.invoke(ActorCell.scala:487) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:254) at akka.dispatch.Mailbox.run(Mailbox.scala:221) at akka.dispatch.Mailbox.exec(Mailbox.scala:231) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.pollAndExecAll(ForkJoinPool.java:1253) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1346) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) |
Re: Why did the Flink Cluster JM crash?
|
|
Hi Amir, what does the JM logs say? Cheers, Till On Tue, Nov 8, 2016 at 9:33 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
Clean . No errors...no exceptions :-( Thanks Till. From: Till Rohrmann <[hidden email]> To: [hidden email]; amir bahmanyari <[hidden email]> Sent: Tuesday, November 8, 2016 2:11 PM Subject: Re: Why did the Flink Cluster JM crash? Hi Amir, what does the JM logs say? Cheers, Till On Tue, Nov 8, 2016 at 9:33 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
In reply to this post by Till Rohrmann-2
OOps! sorry Till. I replicated it and I see exceptions in JM logs. How can I send the logs to you? or what "interesting" part of it do you need so I can copy/paste it here... Thanks From: Till Rohrmann <[hidden email]> To: [hidden email]; amir bahmanyari <[hidden email]> Sent: Tuesday, November 8, 2016 2:11 PM Subject: Re: Why did the Flink Cluster JM crash? Hi Amir, what does the JM logs say? Cheers, Till On Tue, Nov 8, 2016 at 9:33 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
In reply to this post by Till Rohrmann-2
Ok. There is an OOM exception...but this used to work fine with the same configurations. There are four nodes: beam1 through 4. The Kafka partitions are 4096 > 3584 deg of parallelism. jobmanager.rpc.address: beam1 jobmanager.rpc.port: 6123 jobmanager.heap.mb: 1024 taskmanager.heap.mb: 102400 taskmanager.numberOfTaskSlots: 896 taskmanager.memory.preallocate: false parallelism.default: 3584 Thanks for your valuable time Till. AnonymousParDo -> AnonymousParDo (3584/3584) (ebe8da5bda017ee31ad774c5bc5e5e88) switched from DEPLOYING to RUNNING 2016-11-08 22:51:44,471 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Source: Read(UnboundedKafkaSource) -> AnonymousParDo -> AnonymousParDo (3573/3584) (ddf5a8939c1fc4ad1e6d71f17fe5ab0b) switched from RUNNING to FAILED 2016-11-08 22:51:44,474 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Source: Read(UnboundedKafkaSource) -> AnonymousParDo -> AnonymousParDo (1/3584) (865c54432153a0230e62bf7610118ff8) switched from RUNNING to CANCELING 2016-11-08 22:51:44,474 INFO org.apache.flink.runtime.jobmanager.JobManager - Status of job e61cada683c0f7a709101c26c2c9a17c (benchbeamrunners-abahman-1108225128) changed to FAILING. java.lang.OutOfMemoryError: unable to create new native thread at java.lang.Thread.start0(Native Method) at java.lang.Thread.start(Thread.java:714) at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:950) at java.util.concurrent.ThreadPoolExecutor.ensurePrestart(ThreadPoolExecutor.java:1587) at java.util.concurrent.ScheduledThreadPoolExecutor.delayedExecute(ScheduledThreadPoolExecutor.java:334) at java.util.concurrent.ScheduledThreadPoolExecutor.schedule(ScheduledThreadPoolExecutor.java:533) at java.util.concurrent.Executors$DelegatedScheduledExecutorService.schedule(Executors.java:729) at org.apache.flink.streaming.runtime.tasks.StreamTask.registerTimer(StreamTask.java:652) at org.apache.flink.streaming.api.operators.AbstractStreamOperator.registerTimer(AbstractStreamOperator.java:250) at org.apache.flink.streaming.api.operators.StreamingRuntimeContext.registerTimer(StreamingRuntimeContext.java:92) at org.apache.beam.runners.flink.translation.wrappers.streaming.io.UnboundedSourceWrapper.setNextWatermarkTimer(UnboundedSourceWrapper.java:381) at org.apache.beam.runners.flink.translation.wrappers.streaming.io.UnboundedSourceWrapper.run(UnboundedSourceWrapper.java:233) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:78) at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:56) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:224) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:559) at java.lang.Thread.run(Thread.java:745) From: Till Rohrmann <[hidden email]> To: [hidden email]; amir bahmanyari <[hidden email]> Sent: Tuesday, November 8, 2016 2:11 PM Subject: Re: Why did the Flink Cluster JM crash? Hi Amir, what does the JM logs say? Cheers, Till On Tue, Nov 8, 2016 at 9:33 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
Hi Amir, I fear that 900 slots per task manager is a bit too many unless your machine has 900 cores. As a rule of thumb you should allocate as many slots as your machines have cores. Maybe you could try to decrease the number of slots and see if you still observe an OOM error. Cheers, Till On Wed, Nov 9, 2016 at 12:10 AM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
Thanks Till. I have been trying out many many configuration combinations to get to the peak of what I can get as a reasonable performance. And yes, when I drop the number of slots, I dont get OOM. However, I dont get the response I want either. The amount of data I send is kinda huge; about 105 G that's sent in an stretch of 3.5 hours to a 4 nodes cluster running my Beam app receiving from a 2 nodes cluster of Kafka. From what I understand, you are suggesting that to get the best performance, the total number of slots should be equal to the total number of cores distributed in the cluster. For the sake of making sure we have done that, I would go back and repeat the testing with that in mind. Fyi, the Kafka partitions are 4096. Roughly, 1024 per 16 cores per one node. Is this reasonable? Once I know the answer to this question, I will go ahead and readjust my config and repeat the test. I appreciate your response. Amir- From: Till Rohrmann <[hidden email]> To: amir bahmanyari <[hidden email]> Cc: "[hidden email]" <[hidden email]> Sent: Wednesday, November 9, 2016 1:27 AM Subject: Re: Why did the Flink Cluster JM crash? Hi Amir, I fear that 900 slots per task manager is a bit too many unless your machine has 900 cores. As a rule of thumb you should allocate as many slots as your machines have cores. Maybe you could try to decrease the number of slots and see if you still observe an OOM error. Cheers, Till On Wed, Nov 9, 2016 at 12:10 AM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
The amount of data should be fine. Try to set the number of slots to the number of cores you have available. As long as you have more Kafka topics than Flink Kafka consumers (subtasks) you should be fine. But I think you can also decrease the number of Kafka partitions a little bit. I guess that an extensive number of partitions also comes with a price. But I'm no expert there. Hope your experiments run well with these settings. Cheers, Till On Wed, Nov 9, 2016 at 8:02 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
Thanks Till. I did all of that with one difference. I have only 1 topic with 64 partitions correlating to the total number of slots in all Flink servers. Can you elaborate on "As long as you have more Kafka topics than Flink Kafka consumers (subtasks) " pls? Perhaps thats the bottleneck in my config and object creation. I send data to 1 topic across a 2 nodes Kafka cluster with 64 partitions. And KafkaIo() in Beam app is set to receive from it. How can "more Kafka topics" translate to KafkaIo() settings in Beam API? Thanks+regards Amir- From: Till Rohrmann <[hidden email]> To: amir bahmanyari <[hidden email]> Cc: "[hidden email]" <[hidden email]> Sent: Thursday, November 10, 2016 2:13 AM Subject: Re: Why did the Flink Cluster JM crash? The amount of data should be fine. Try to set the number of slots to the number of cores you have available. As long as you have more Kafka topics than Flink Kafka consumers (subtasks) you should be fine. But I think you can also decrease the number of Kafka partitions a little bit. I guess that an extensive number of partitions also comes with a price. But I'm no expert there. Hope your experiments run well with these settings. Cheers, Till On Wed, Nov 9, 2016 at 8:02 PM, amir bahmanyari <[hidden email]> wrote:
|
Re: Why did the Flink Cluster JM crash?
|
|
Hi Till. I just checked and my test finished after 19 hours with the config below. The expected Linear Road test time is 3.5 hours. I have achieved this for 1/2 data I sent yesterday. But for 105 G worth of tuples I get 19 hours. No exceptions, no errors. Clean. But almost 5 times slower than expected. Thanks again. 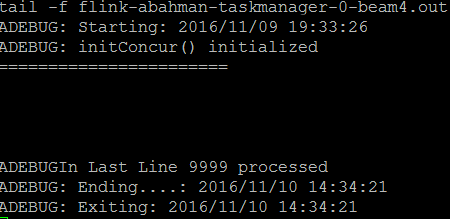 From: amir bahmanyari <[hidden email]> To: Till Rohrmann <[hidden email]> Cc: "[hidden email]" <[hidden email]> Sent: Thursday, November 10, 2016 9:35 AM Subject: Re: Why did the Flink Cluster JM crash? Thanks Till. I did all of that with one difference. I have only 1 topic with 64 partitions correlating to the total number of slots in all Flink servers. Can you elaborate on "As long as you have more Kafka topics than Flink Kafka consumers (subtasks) " pls? Perhaps thats the bottleneck in my config and object creation. I send data to 1 topic across a 2 nodes Kafka cluster with 64 partitions. And KafkaIo() in Beam app is set to receive from it. How can "more Kafka topics" translate to KafkaIo() settings in Beam API? Thanks+regards Amir- From: Till Rohrmann <[hidden email]> To: amir bahmanyari <[hidden email]> Cc: "[hidden email]" <[hidden email]> Sent: Thursday, November 10, 2016 2:13 AM Subject: Re: Why did the Flink Cluster JM crash? The amount of data should be fine. Try to set the number of slots to the number of cores you have available. As long as you have more Kafka topics than Flink Kafka consumers (subtasks) you should be fine. But I think you can also decrease the number of Kafka partitions a little bit. I guess that an extensive number of partitions also comes with a price. But I'm no expert there. Hope your experiments run well with these settings. Cheers, Till On Wed, Nov 9, 2016 at 8:02 PM, amir bahmanyari <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |