Why checkpoint took so long


|
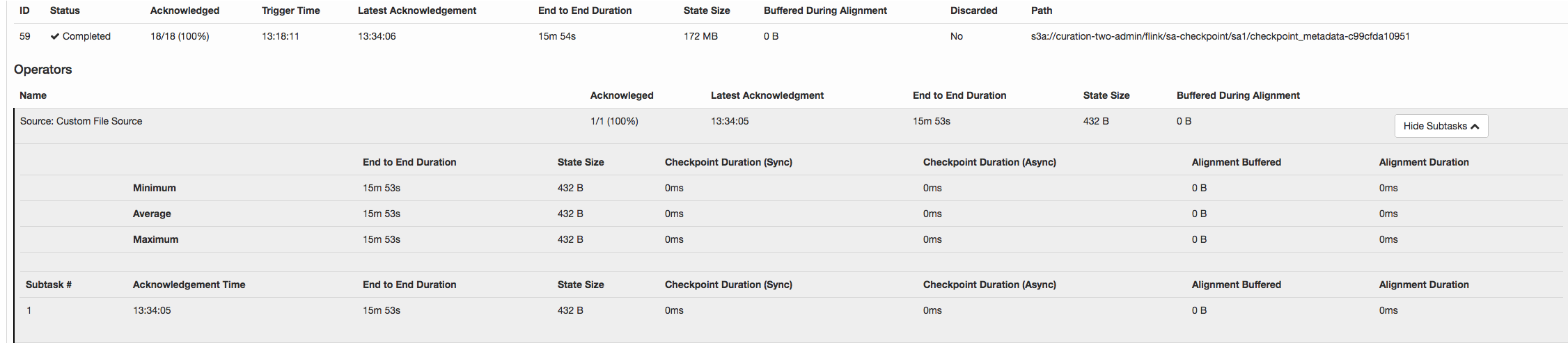
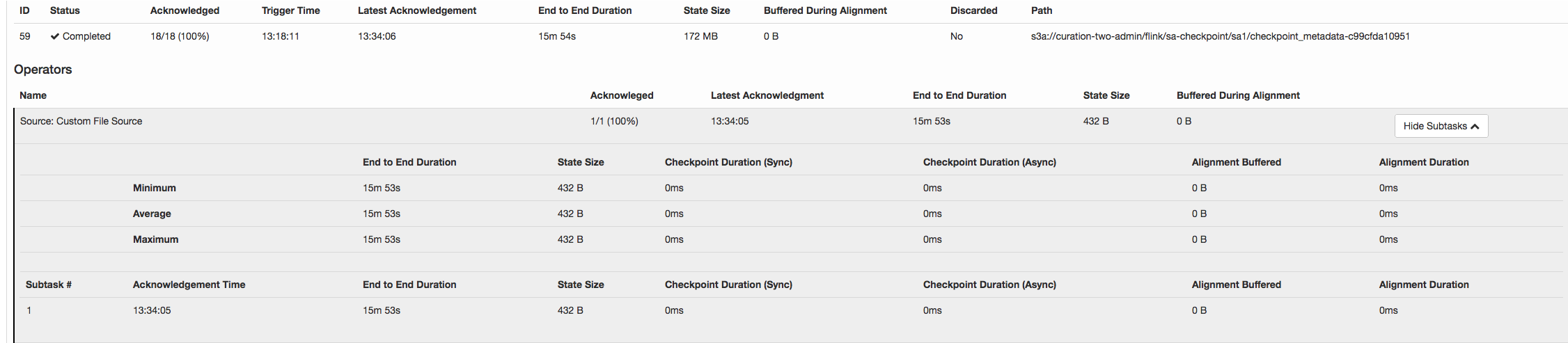
I noticed a strange thing in flink 1.3 checkpointing. Checkpoint succeeded, but took so long 15 minutes 53 seconds. Size of checkpoint metadata on s3 is just 1.7MB. Most of the time checkpoints actually fails.
aws --profile cure s3 ls --recursive --summarize --human s3://curation-two-admin/flink/sa-checkpoint/sa1/checkpoint_metadata-c99cfda10951 2018-08-16 13:34:07 1.7 MiB flink/sa-checkpoint/sa1/checkpoint_metadata-c99cfda10951 I came this discussion http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Checkpoints-very-slow-with-high-backpressure-td12762.html#a19370. But it looks like the problem was caused by high back pressure. Not the case for me. taskmanager.network.memory.max 128 MB very small, I was hoping to get faster checkpoints with smaller buffers. Reading from durable storage (s3) and don't worry about buffering reads due to slow writing. Any ideas, what can cause such slow checkpointing? Thanks. -Alex 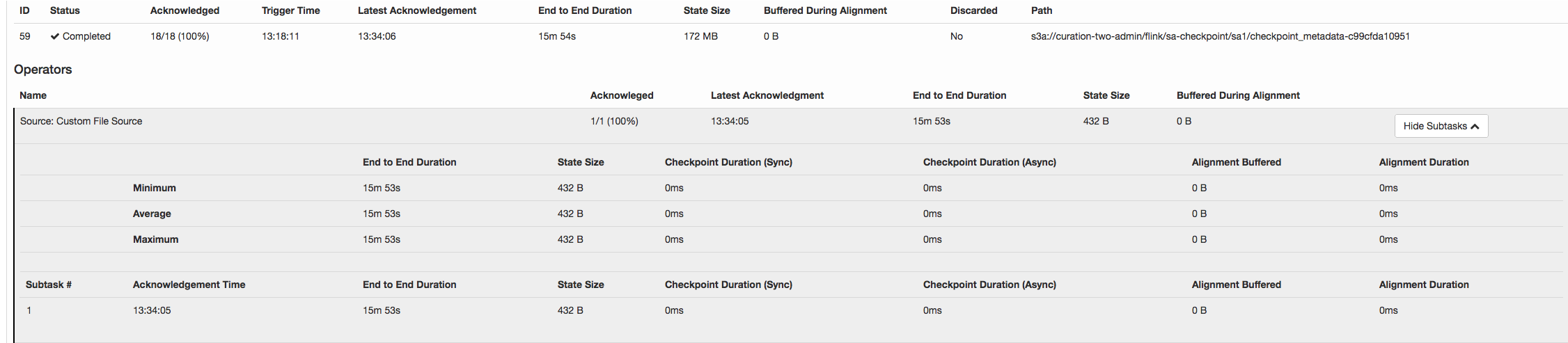 |
|
|
Hi Alex, I still have a few questions: 1) Is this file source and checkpoint logic implemented by you? . 2) Other failed checkpoints, can you give the corresponding failure log or more descriptions, such as failure due to timeout, or other reasons? Thanks, vino. Alex Vinnik <[hidden email]> 于2018年8月17日周五 上午3:03写道:
|
|
|
Vino, 1. No custom implementations for source and checkpoints. Source is json files on s3. JsonLinesInputFormat format = new JsonLinesInputFormat(new Path(customerPath), configuration); RocksDB is used as sate backend. 2. Majority of checkpoints timeout after 15 minutes. Thanks On Thu, Aug 16, 2018 at 8:48 PM vino yang <[hidden email]> wrote:
|
|
|
Hi Alex, Have you checked if Flink has caused a timeout when accessing the file system? Can you give JM's log and checkpoint specific log in TM. Thanks, vino. Alex Vinnik <[hidden email]> 于2018年8月17日周五 上午11:51写道:
|
|
|
Vino, Here is what I see in JM. 2018-08-20T15:18:09.372+0000 [org.apache.flink.runtime.checkpoint.CheckpointCoordinator] WARN Received late message for now expired checkpoint attempt 253 from e06b6c3a059ca809f519effba0b119ae of job 330e0d4fa4ab05198ed9afbcfcf0a1f7. 2018-08-20T15:18:11.430+0000 [org.apache.flink.runtime.checkpoint.CheckpointCoordinator] WARN Received late message for now expired checkpoint attempt 253 from 9d679ab858959ab3236e23a1f8e66484 of job 330e0d4fa4ab05198ed9afbcfcf0a1f7. 2018-08-20T15:18:17.890+0000 [org.apache.flink.runtime.checkpoint.CheckpointCoordinator] WARN Received late message for now expired checkpoint attempt 253 from 5704d6f11912bef272a23d813aab3d4f of job 330e0d4fa4ab05198ed9afbcfcf0a1f7. Searching for "checkpoint" in taskmanager logs return nothing. Anything specific I can search for? Thanks -Alex On Fri, Aug 17, 2018 at 7:23 AM vino yang <[hidden email]> wrote:
|
|
|
Hi Alex, This log related code is posted here: // message is for an unknown checkpoint, or comes too late (checkpoint disposed) if (recentPendingCheckpoints.contains(checkpointId)) { wasPendingCheckpoint = true; LOG.warn("Received late message for now expired checkpoint attempt {} from " + "{} of job {}.", checkpointId, message.getTaskExecutionId(), message.getJob()); } So the attempt Id contained in your log actually represents a sub task instance of a job. You can find more useful information in the JM and TM logs in conjunction with the Job id, but only if you need to adjust your log level to DEBUG, you will see more logs related to Checkpoint when you adjust. When you adjust, you can search the following log, combined with your attempt id.
log.debug("Trigger checkpoint {}@{} for {}.", checkpointId, checkpointTimestamp, executionAttemptID); Thanks, vino. Alex Vinnik <[hidden email]> 于2018年8月20日周一 下午11:51写道:
|
| Free forum by Nabble | Edit this page |