Where is the "Latest Savepoint" information saved?


|
Since this save point path is very useful to application updates, where is this information stored? Can we keep it in ZK or S3 for retrieval? 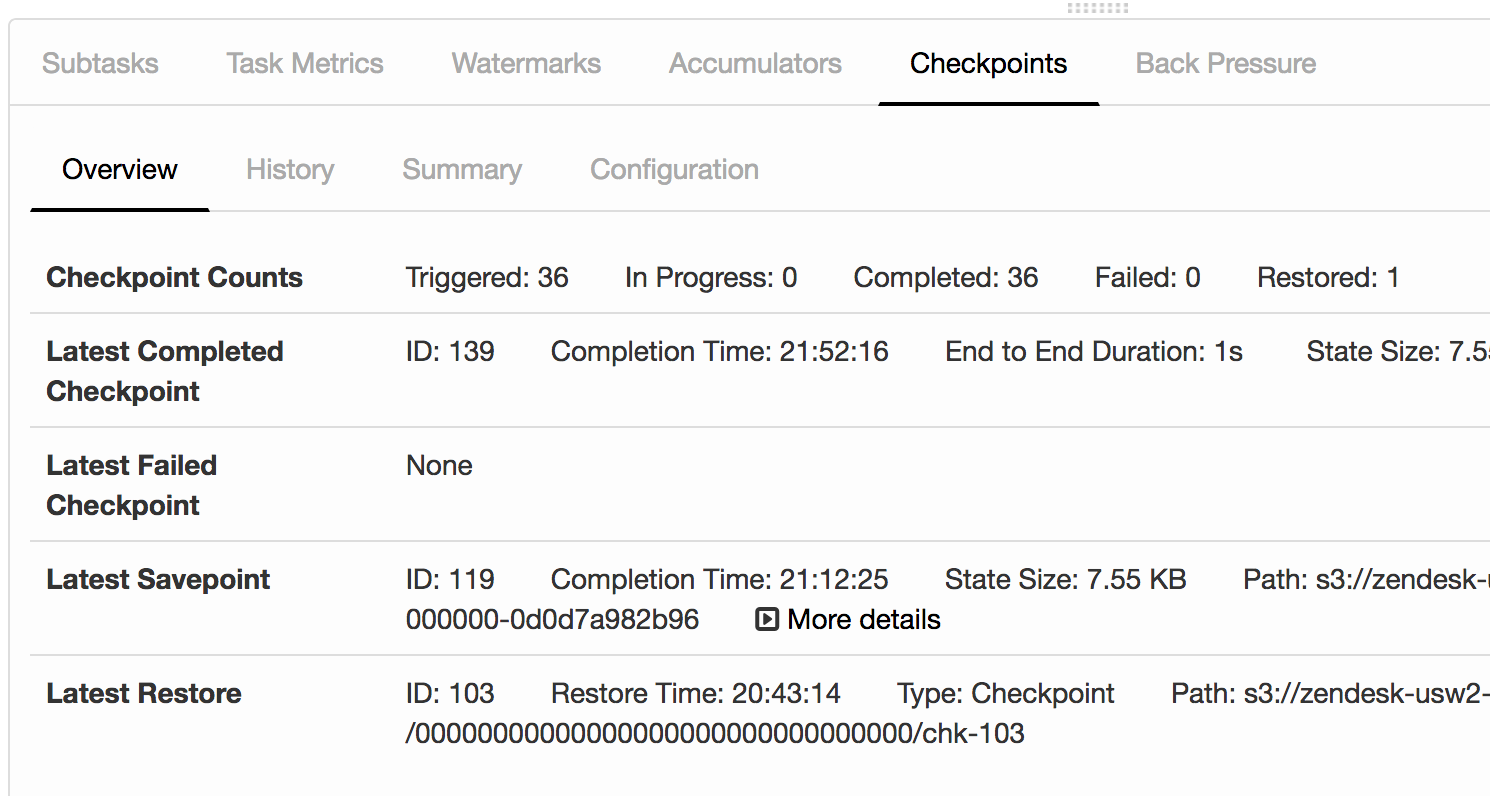 |
|
|
Hi Hao,
The savepoint path is stored in ZK, but it’s in binary format, so in order to retrieve the path you have to deserialize it back to some Flink internal object. A better approach would be using REST api to get the path. You could find it here[1]. Best, Paul Lam
|
|
|
Can we add an option to allow job cluster mode to start from the latest save point? Otherwise I have to somehow get the info from ZK, before job cluster's container started by K8s.
On Fri, Nov 9, 2018, 01:29 Paul Lam <[hidden email]> wrote:
|
Re: Where is the "Latest Savepoint" information saved?
|
|
Hey Hao and Paul,
1) Fetch checkpoint info manually from ZK (problematic, not recommended) - As Paul pointed out, this is problematic as the node is a serialized pointer (StateHandle) to a CompletedCheckpoint in the HA storage directory and not a path [1]. - I would not recommend this approach at the moment 2) Using the HTTP API to fetch the latest savepoint pointer (possible, but cumbersome) - As Paul proposed, you could use /jobs/:jobid/checkpoints to fetch checkpoint statistics about the latest savepoint - The latest savepoint is available as a separate entry under `latest.savepoint` (If I'm reading the docs [2] correctly) - You would need to manually do this before shutting down (requires custom tooling to automate) 3) Use cancelWithSavepoint - If you keep `high-availability.cluster-id` consistent between executions of your job cluster, using cancelWithSavepoint [3] should add the the savepoint to ZK before cancelling the job - On the next execution of your job cluster, Flink should automatically pick it up (no need to attach a savepoint restore path manually) I've not tried 3) myself yet, but believe it should work. If you have time to try it out, I'd be happy to hear whether it works as expected for you. – Ufuk [1] I believe this is overly complicated and should be simplified in the future. [2] Search /jobs/:jobid/checkpoints in https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html [3] https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html#job-cancellation On Fri, Nov 9, 2018 at 5:03 PM Hao Sun <[hidden email]> wrote: > > Can we add an option to allow job cluster mode to start from the latest save point? Otherwise I have to somehow get the info from ZK, before job cluster's container started by K8s. > > On Fri, Nov 9, 2018, 01:29 Paul Lam <[hidden email]> wrote: >> >> Hi Hao, >> >> The savepoint path is stored in ZK, but it’s in binary format, so in order to retrieve the path you have to deserialize it back to some Flink internal object. >> >> A better approach would be using REST api to get the path. You could find it here[1]. >> >> [1] https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html >> >> Best, >> Paul Lam >> >> >> 在 2018年11月9日,13:55,Hao Sun <[hidden email]> 写道: >> >> Since this save point path is very useful to application updates, where is this information stored? Can we keep it in ZK or S3 for retrieval? >> >> <image.png> >> >> |
|
|
This is great, I will try option 3 and let you know. Can I log some message so I know job is recovered from the latest savepoint? On Sun, Nov 11, 2018 at 10:42 AM Ufuk Celebi <[hidden email]> wrote:
|
Re: Where is the "Latest Savepoint" information saved?
|
|
I think there should be a log message, but I don't know what the exact
format is (you would need to look through it and search for something related to CompletedCheckpointStore). An alternative is the web UI checkpointing tab. It shows the latest checkpoint used for restore of the job. You should see your savepoint there. Best, Ufuk On Sun, Nov 11, 2018 at 7:45 PM Hao Sun <[hidden email]> wrote: > > This is great, I will try option 3 and let you know. > Can I log some message so I know job is recovered from the latest savepoint? > > On Sun, Nov 11, 2018 at 10:42 AM Ufuk Celebi <[hidden email]> wrote: >> >> Hey Hao and Paul, >> >> 1) Fetch checkpoint info manually from ZK (problematic, not recommended) >> - As Paul pointed out, this is problematic as the node is a serialized >> pointer (StateHandle) to a CompletedCheckpoint in the HA storage >> directory and not a path [1]. >> - I would not recommend this approach at the moment >> >> 2) Using the HTTP API to fetch the latest savepoint pointer (possible, >> but cumbersome) >> - As Paul proposed, you could use /jobs/:jobid/checkpoints to fetch >> checkpoint statistics about the latest savepoint >> - The latest savepoint is available as a separate entry under >> `latest.savepoint` (If I'm reading the docs [2] correctly) >> - You would need to manually do this before shutting down (requires >> custom tooling to automate) >> >> 3) Use cancelWithSavepoint >> - If you keep `high-availability.cluster-id` consistent between >> executions of your job cluster, using cancelWithSavepoint [3] should >> add the the savepoint to ZK before cancelling the job >> - On the next execution of your job cluster, Flink should >> automatically pick it up (no need to attach a savepoint restore path >> manually) >> >> I've not tried 3) myself yet, but believe it should work. If you have >> time to try it out, I'd be happy to hear whether it works as expected >> for you. >> >> – Ufuk >> >> [1] I believe this is overly complicated and should be simplified in the future. >> [2] Search /jobs/:jobid/checkpoints in >> https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html >> [3] https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html#job-cancellation >> >> On Fri, Nov 9, 2018 at 5:03 PM Hao Sun <[hidden email]> wrote: >> > >> > Can we add an option to allow job cluster mode to start from the latest save point? Otherwise I have to somehow get the info from ZK, before job cluster's container started by K8s. >> > >> > On Fri, Nov 9, 2018, 01:29 Paul Lam <[hidden email]> wrote: >> >> >> >> Hi Hao, >> >> >> >> The savepoint path is stored in ZK, but it’s in binary format, so in order to retrieve the path you have to deserialize it back to some Flink internal object. >> >> >> >> A better approach would be using REST api to get the path. You could find it here[1]. >> >> >> >> [1] https://ci.apache.org/projects/flink/flink-docs-release-1.6/monitoring/rest_api.html >> >> >> >> Best, >> >> Paul Lam >> >> >> >> >> >> 在 2018年11月9日,13:55,Hao Sun <[hidden email]> 写道: >> >> >> >> Since this save point path is very useful to application updates, where is this information stored? Can we keep it in ZK or S3 for retrieval? >> >> >> >> <image.png> >> >> >> >> |
|
|
Thanks, I'll check it out. On Sun, Nov 11, 2018 at 10:52 AM Ufuk Celebi <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |