What if not to keep containers across attempts in HA setup?


|
Hi,
Recently I found a bug on our YARN cluster that crashes the standby RM during a RM failover, and the bug is triggered by the keeping containers across attempts behavior of applications (see [1], a related issue but the patch is not exactly the fix, because the problem is not on recovery, but the attempt after the recovery). Since YARN is a fundamental component and a maintenance of it would affect a lot users, as a last resort I wonder if we could modify YarnClusterDescriptor and not to keep containers across attempts. IMHO, Flink application’s state is not dependent on YARN, so there is no state that must be recovered from the previous application attempt. In case of a application master failure, the taskmanagers can be shutdown and the cost is longer recovery time. Please correct me if I’m wrong. Thank you! Best, Paul Lam
|
回复: What if not to keep containers across attempts in HA setup?(Internet mail)
|
|
Hi Paul,
Could you check out your YARN property "yarn.resourcemanager.work-preserving-recovery.enabled"?
if value is false, set true and try it again.
Best,
Devin
|
|
|
Hi Devin,
Thanks for the pointer and it works! But I have no permission to change the YARN conf in production environment by myself and it would need an detailed investigation of the Hadoop team to apply the new conf, so I’m still interested in the difference between keeping and not keeping containers across application attempts. Best, Paul Lam
|
回复: Re: What if not to keep containers across attempts in HA setup?(Internet mail)
|
|
Hi Paul:
I have reviewed hadoop & Flink code.
Flink setKeepContainersAcrossApplicationAttempts to true if you set flink config high-availability to
true.
 If you set yarn.resourcemanager.work-preserving-recovery.enabled false, AM(JobManager) will
be killed by ResouceManager and start anthoer AM when failover.
Flink setKeepContainersAcrossApplicationAttempts to
true cause am start from previous attempt.
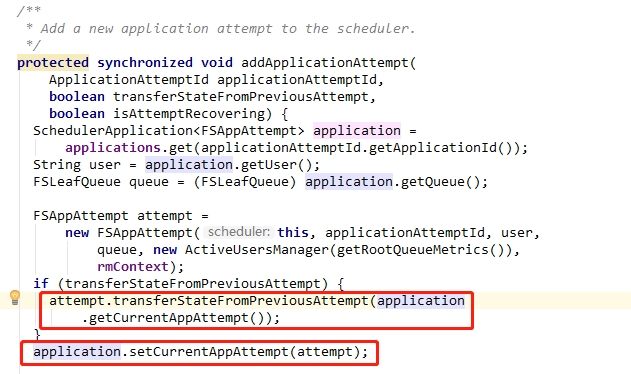 But current ResourceManager is new active, application is not set AppAttempt.
So you will see NPE exception.
I think hadoop comunnity should resolve this issue.
|
|
|
Hi Devin,
Thanks for your reasoning! It’s consistent with my observation, and I fully agree with you. Maybe we should create an issue for the Hadoop community if it is not fixed in the master branch. Best, Paul Lam
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |