Very slow checkpoints occasionally occur

Very slow checkpoints occasionally occur

|
Hi all,
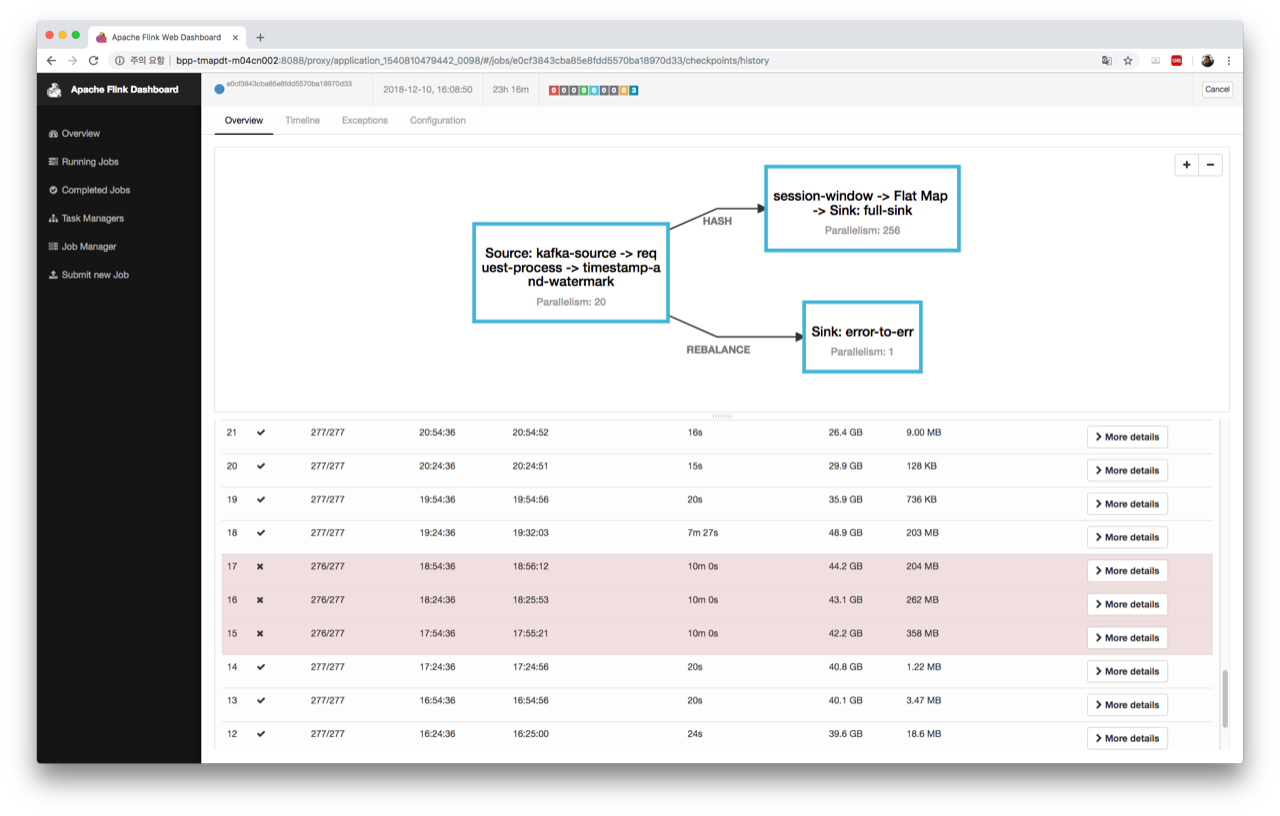
We're facing the same problem mentioned in [1] - Very slow checkpoint attempts of few tasks cause checkpoint failures and, furthermore, incur high back pressure. We're running our Flink jobs on a cluster where - 2 masters + 8 worker nodes - all nodes, even masters, are equipped with SSD's - we have a separate cluster for Kafka - we depend largely on Hadoop-2.7.3; YARN for deploying per-job clusters and HDFS for storing checkpoints and savepoints - All SSD's of each node serve as local-dirs for YARN NM and data-dirs for HDFS DN - we use RocksDB state backend - we use the latest version, flink-1.7.0 - we trigger checkpoints every 30 minutes and the size of state is not that large as shown in the attached screenshot. The job itself recovers from checkpoint failures and back pressure after a while; [2] shows that the job recovers after three failed checkpoints. Below is part of JM log message: 2018-12-10 17:24:36,150 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 14 @ 1544430276096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 17:24:57,912 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 14 for job e0cf3843cba85e8fdd5570ba18970d33 (43775252946 bytes in 21781 ms).
2018-12-10 17:54:36,133 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 15 @ 1544432076096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 18:04:36,134 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 15 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 18:24:36,156 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 16 @ 1544433876096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 18:34:36,157 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 16 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 18:54:36,138 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 17 @ 1544435676096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:04:36,139 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 17 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 19:15:44,849 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 15 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:16:37,822 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 16 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:17:12,974 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 17 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:24:36,147 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 18 @ 1544437476096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:32:05,869 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 18 for job e0cf3843cba85e8fdd5570ba18970d33 (52481833829 bytes in 449738 ms).#15, #16, and #17 fail due to a single task e81a7fb90d05da2bcec02a34d6f821e3, which is a session-window task. As shown in [3], during that period, the average checkpoint end-to-end duration for the window operation increased as follows: - #15 : 37s - #16 : 1m 4s - #17 : 1m 25s However, the average end-to-end duration for normal situations is not that long (less than 30s). During that period, back pressure affect the throughput a lot which is very frustrating. How can I get rid of checkpoint failures and back pressure? Isn't it somewhat related to HDFS clients? [2] 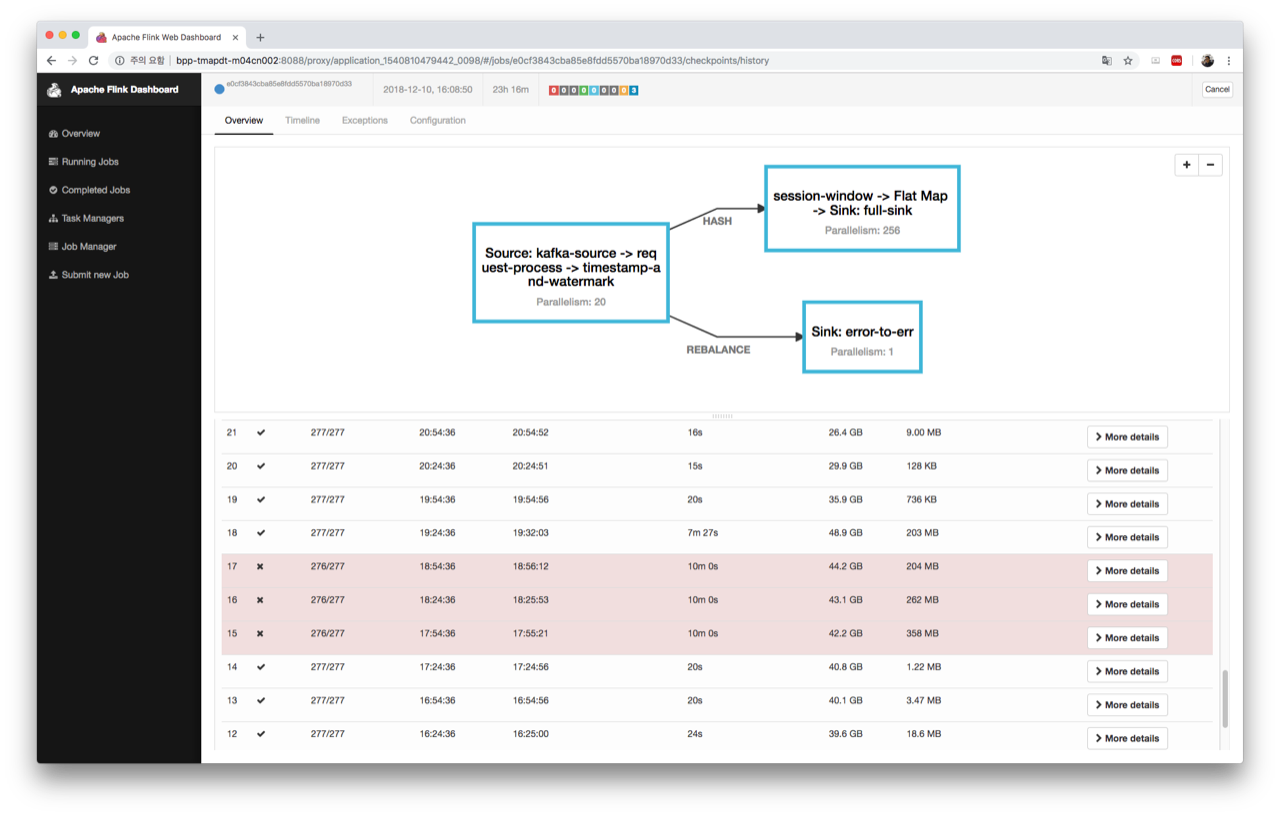 [3] |
Re: Very slow checkpoints occasionally occur
|
|
Hi,
Looking at the numbers, it seems to me that checkpoint execution (the times of the sync and async part) are always reasonable fast once they are executed on the task, but there are changes in the alignment time and the time from triggering a checkpoint to executing a checkpoint. As you are using windows and looking at the way the state size behaves before and after the problem, I might have a suggestion what could cause the problem. Before and during the problematic checkpoints, state size is rising. After the problem is gone, the state size is significantly smaller. Could it be that, as time progresses or jumps, there is a spike in session window triggering? When time moves it could be possible that suddenly a lot of windows are triggered and when a checkpoint barrier is arriving after the firing was triggered, it will have to wait until all window firing is completed for consistency reason. This would also explain the backpressure that you observe during this period, coming from a lot of / expensive window firing and future events/checkpoints can only proceed when the firing is done. You could investigate if that is what is happening and maybe take measure to avoid this, but that is highly dependent on your job logic. Best, Stefan
|
|
|
In reply to this post by Dongwon Kim-2
Hi Dongwon
From the picture you pasted here, only one task not reported checkpoint successfully, I think you should view the task manager's log of task e81a7fb90d05da2bcec02a34d6f821e3 (find the deploy message of this task attempt within job manager log to know which
container-id and host to launch it) to see is there anything wrong. Besides, you could jstack this running task process to see whether stuck in some method if possible. From my point of view, this task might be a hot-spot which receives more records or have
lower performance due to the node running this task is in high load.
What's more, very slow checkpoint of one task should not cause high back pressure in general. Only the sync-part of checkpoint would impact the topology task to process records, however, the part of duration is not long according to your picture. Generally,
processing records very slow, which caused high back pressure, would result in checkpoint slow then. This is because the task has to spend more time to process input records before processing the checkpoint barrier.
Hope my suggestion works for you.
Best
Yun Tang
From: Dongwon Kim <[hidden email]>
Sent: Tuesday, December 11, 2018 17:26 To: user Cc: Keuntae Park Subject: Very slow checkpoints occasionally occur
Hi all,
We're facing the same problem mentioned in [1] - Very slow checkpoint attempts of few tasks cause checkpoint failures and, furthermore, incur high back pressure.
We're running our Flink jobs on a cluster where
- 2 masters + 8 worker nodes
- all nodes, even masters, are equipped with SSD's
- we have a separate cluster for Kafka
- we depend largely on Hadoop-2.7.3; YARN for deploying per-job clusters and HDFS for storing checkpoints and savepoints
- All SSD's of each node serve as local-dirs for YARN NM and data-dirs for HDFS DN
- we use RocksDB state backend
- we use the latest version, flink-1.7.0
- we trigger checkpoints every 30 minutes and the size of state is not that large as shown in the attached screenshot.
The job itself recovers from checkpoint failures and back pressure after a while; [2] shows that the job recovers after three failed checkpoints.
Below is part of JM log message:
2018-12-10 17:24:36,150 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 14 @ 1544430276096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 17:24:57,912 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 14 for job e0cf3843cba85e8fdd5570ba18970d33 (43775252946 bytes in 21781 ms).
2018-12-10 17:54:36,133 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 15 @ 1544432076096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 18:04:36,134 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 15 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 18:24:36,156 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 16 @ 1544433876096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 18:34:36,157 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 16 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 18:54:36,138 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 17 @ 1544435676096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:04:36,139 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 17 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing.
2018-12-10 19:15:44,849 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 15 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:16:37,822 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 16 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:17:12,974 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 17 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:24:36,147 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 18 @ 1544437476096 for job e0cf3843cba85e8fdd5570ba18970d33.
2018-12-10 19:32:05,869 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 18 for job e0cf3843cba85e8fdd5570ba18970d33 (52481833829 bytes in 449738 ms).
#15, #16, and #17 fail due to a single task e81a7fb90d05da2bcec02a34d6f821e3,
which is a session-window task.
As shown in [3], during that period, the average checkpoint end-to-end duration for the window operation increased as follows:
- #15 : 37s
- #16 : 1m 4s
- #17 : 1m 25s
However, the average end-to-end duration for normal situations is not that long (less than 30s).
During that period, back pressure affect the throughput a lot which is very frustrating.
How can I get rid of checkpoint failures and back pressure?
Isn't it somewhat related to HDFS clients?
[2]
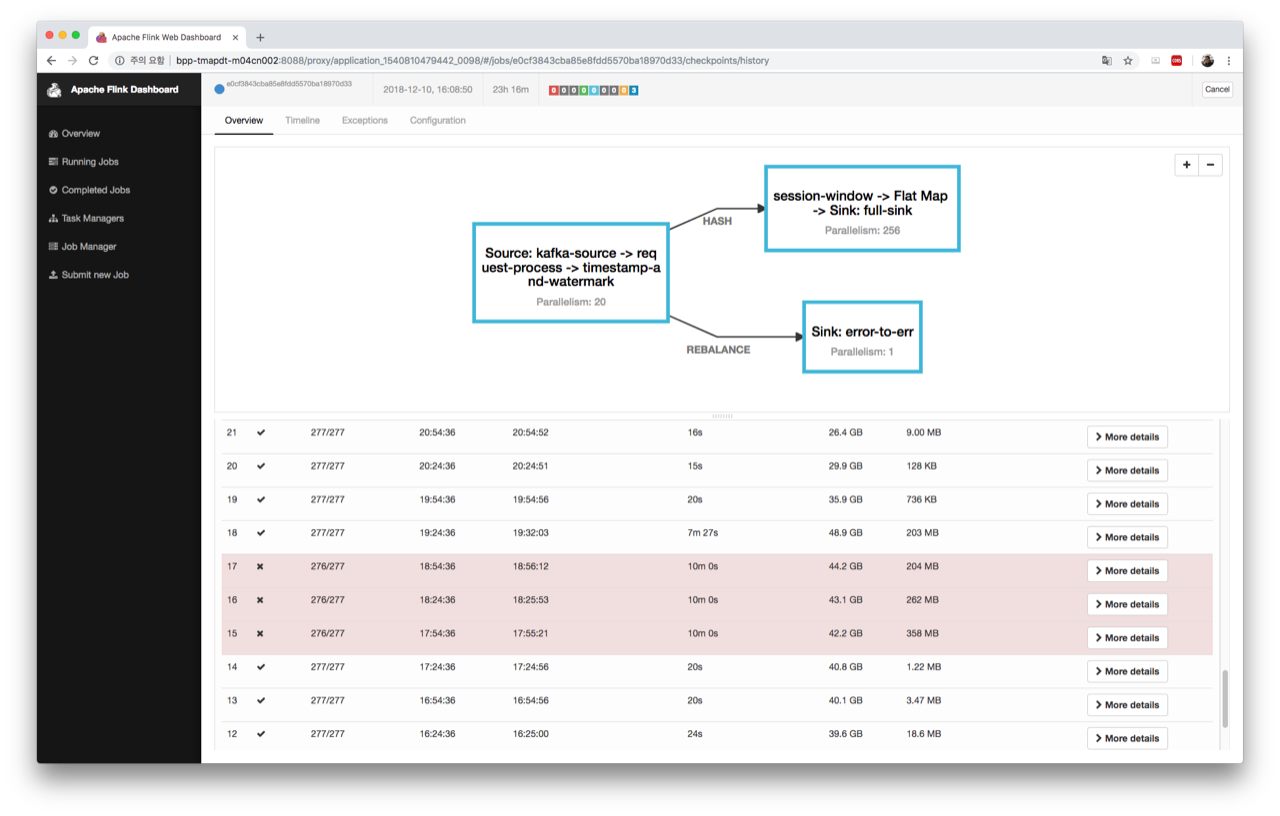 [3]
|
Re: Very slow checkpoints occasionally occur
|
|
In reply to this post by Stefan Richter
Hi Stefan, Thanks a lot for shedding a light on this! it seems to me that checkpoint execution (the times of the sync and async part) are always reasonable fast once they are executed on the task Okay, HDFS clients seem to have nothing to do with it. Thanks a lot for pointing this out. Could it be that, as time progresses or jumps, there is a spike in session window triggering? As you said, there were spikes after the period as shown in [1]. When time moves it could be possible that suddenly a lot of windows are triggered and when a checkpoint barrier is arriving after the firing was triggered, it will have to wait until all window firing is completed for consistency reason. This would also explain the backpressure that you observe during this period, coming from a lot of / expensive window firing and future events/checkpoints can only proceed when the firing is done. Should cluster load be high if Flink spends most of time for taking care of window firing? However, as shown in [2], cluster load/disk throughput/network throughput are low during the period. In addition, we've observed this problem even during the night time when user requests are much lower than this and even when message rates are decreasing. You could investigate if that is what is happening and maybe take measure to avoid this, but that is highly dependent on your job logic. I’ve implemented a custom trigger for session window [3] to trigger early firing as depicted in [4]. Could a custom trigger implementation be a source of the problem? Thanks a lot for taking a look at it :-) Best, - Dongwon [1] 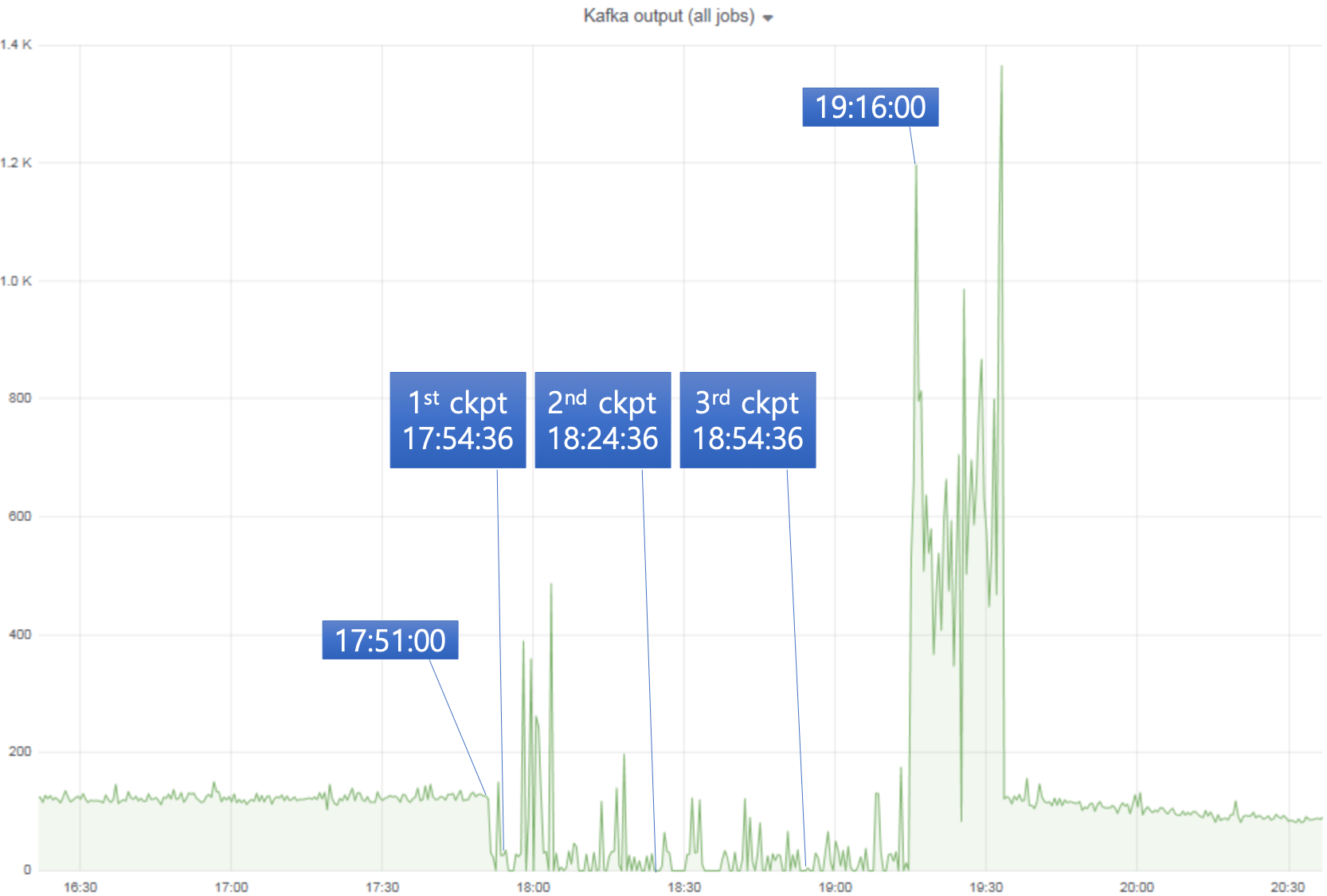 [2] 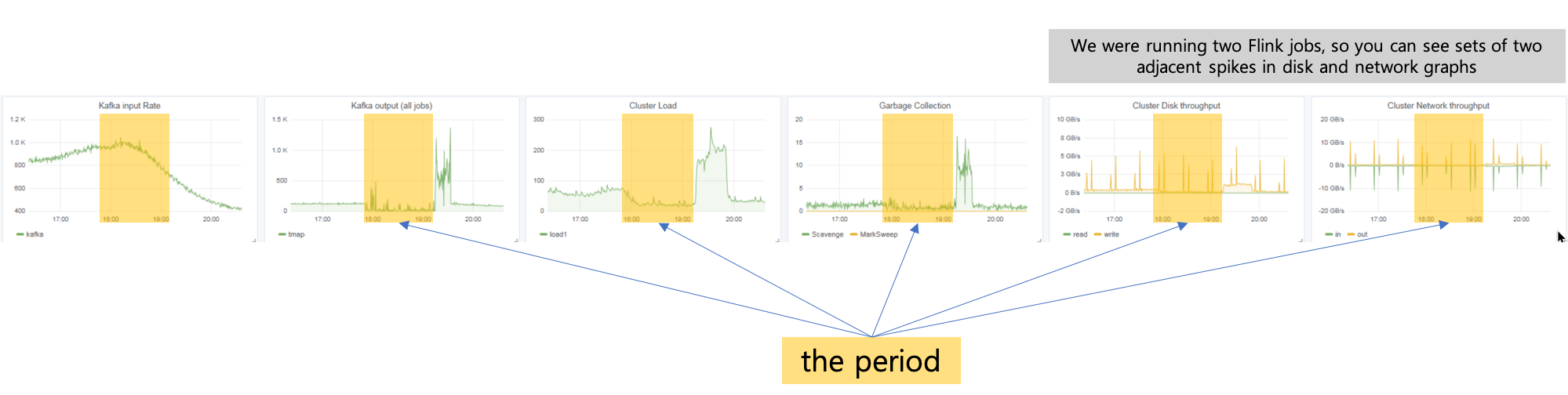 On Tue, Dec 11, 2018 at 7:54 PM Stefan Richter <[hidden email]> wrote: > > Hi, > > Looking at the numbers, it seems to me that checkpoint execution (the times of the sync and async part) are always reasonable fast once they are executed on the task, but there are changes in the alignment time and the time from triggering a checkpoint to executing a checkpoint. As you are using windows and looking at the way the state size behaves before and after the problem, I might have a suggestion what could cause the problem. Before and during the problematic checkpoints, state size is rising. After the problem is gone, the state size is significantly smaller. Could it be that, as time progresses or jumps, there is a spike in session window triggering? When time moves it could be possible that suddenly a lot of windows are triggered and when a checkpoint barrier is arriving after the firing was triggered, it will have to wait until all window firing is completed for consistency reason. This would also explain the backpressure that you observe during this period, coming from a lot of / expensive window firing and future events/checkpoints can only proceed when the firing is done. You could investigate if that is what is happening and maybe take measure to avoid this, but that is highly dependent on your job logic. > > Best, > Stefan > > On 11. Dec 2018, at 10:26, Dongwon Kim <[hidden email]> wrote: > > Hi all, > > We're facing the same problem mentioned in [1] - Very slow checkpoint attempts of few tasks cause checkpoint failures and, furthermore, incur high back pressure. > We're running our Flink jobs on a cluster where > - 2 masters + 8 worker nodes > - all nodes, even masters, are equipped with SSD's > - we have a separate cluster for Kafka > - we depend largely on Hadoop-2.7.3; YARN for deploying per-job clusters and HDFS for storing checkpoints and savepoints > - All SSD's of each node serve as local-dirs for YARN NM and data-dirs for HDFS DN > - we use RocksDB state backend > - we use the latest version, flink-1.7.0 > - we trigger checkpoints every 30 minutes and the size of state is not that large as shown in the attached screenshot. > > The job itself recovers from checkpoint failures and back pressure after a while; [2] shows that the job recovers after three failed checkpoints. > > Below is part of JM log message: > > 2018-12-10 17:24:36,150 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 14 @ 1544430276096 for job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 17:24:57,912 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 14 for job e0cf3843cba85e8fdd5570ba18970d33 (43775252946 bytes in 21781 ms). > 2018-12-10 17:54:36,133 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 15 @ 1544432076096 for job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 18:04:36,134 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 15 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing. > 2018-12-10 18:24:36,156 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 16 @ 1544433876096 for job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 18:34:36,157 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 16 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing. > 2018-12-10 18:54:36,138 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 17 @ 1544435676096 for job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 19:04:36,139 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Checkpoint 17 of job e0cf3843cba85e8fdd5570ba18970d33 expired before completing. > 2018-12-10 19:15:44,849 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 15 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 19:16:37,822 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 16 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 19:17:12,974 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 17 from e81a7fb90d05da2bcec02a34d6f821e3 of job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 19:24:36,147 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 18 @ 1544437476096 for job e0cf3843cba85e8fdd5570ba18970d33. > 2018-12-10 19:32:05,869 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 18 for job e0cf3843cba85e8fdd5570ba18970d33 (52481833829 bytes in 449738 ms). > > #15, #16, and #17 fail due to a single task e81a7fb90d05da2bcec02a34d6f821e3, which is a session-window task. > > As shown in [3], during that period, the average checkpoint end-to-end duration for the window operation increased as follows: > - #15 : 37s > - #16 : 1m 4s > - #17 : 1m 25s > However, the average end-to-end duration for normal situations is not that long (less than 30s). > During that period, back pressure affect the throughput a lot which is very frustrating. > > How can I get rid of checkpoint failures and back pressure? > Isn't it somewhat related to HDFS clients? > > > [1] http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Checkpoints-very-slow-with-high-backpressure-td12762.html > [2] > <failures.png> > [3] > <???? ????? ᆺ 2018-12-11 오후 4.25.54.png> > > |
Re: Very slow checkpoints occasionally occur
|
|
In reply to this post by Yun Tang
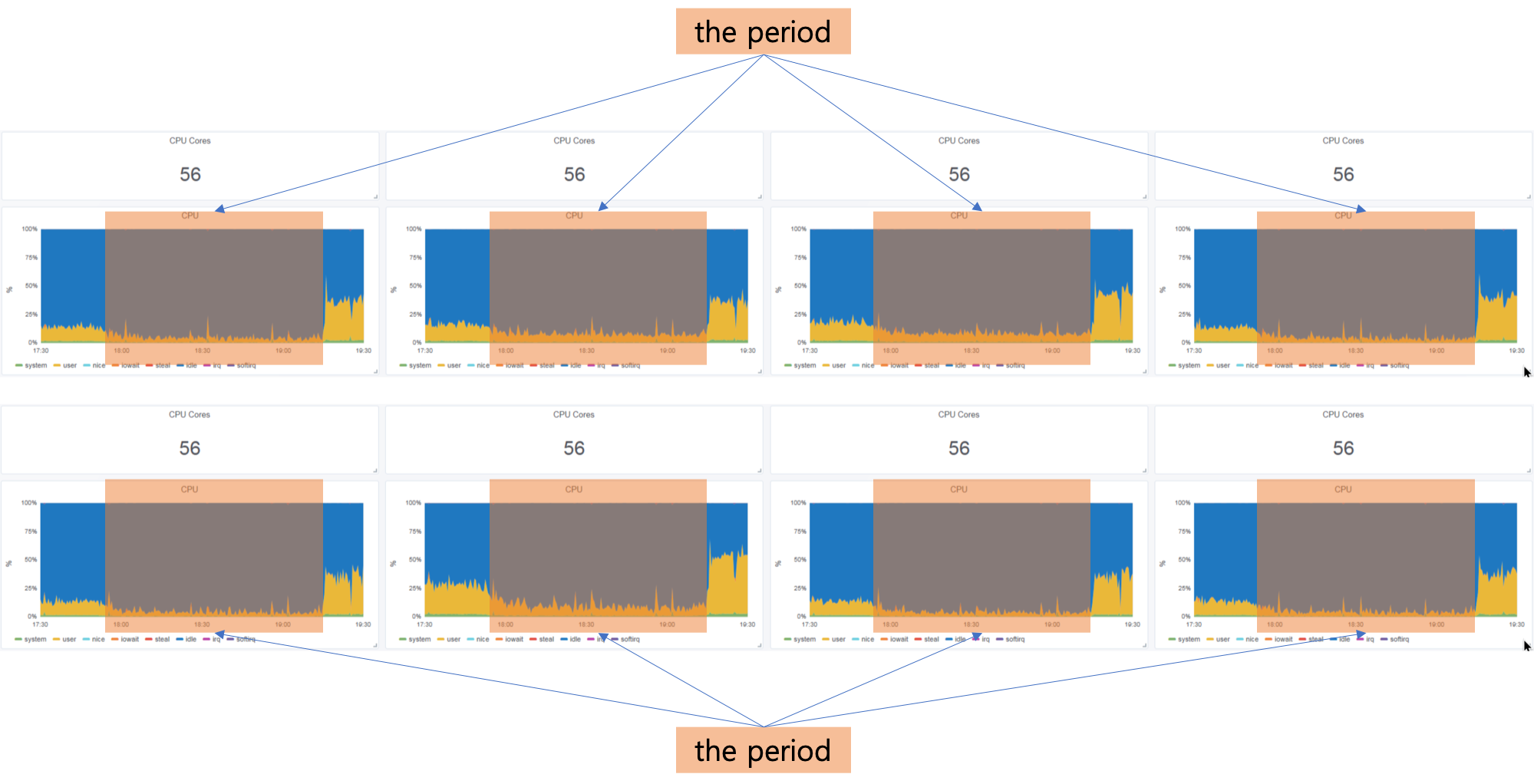
Hi Yun! Thanks a lot for your email. this task might be a hot-spot which receives more records I don't think we have partition skew. In the attached excel file [1], there are six worksheets each corresponding to a checkpoint. In each worksheet, I copy and paste the detailed information of checkpoint attempts for session window tasks. Task #244 is the one so I highlight the line 253 of each worksheet. The state size of task #244 at ckpt14, ckpt18, ckpt19 are similar to others. It task #244 were a hot spot, it would have much larger state than others. or have lower performance due to the node running this task is in high load. unfortunately, as shown in [2], all of eight worker nodes are not that busy during the period :-( What's more, very slow checkpoint of one task should not cause high back pressure in general. Only the sync-part of checkpoint would impact the topology task to process records, however, the part of duration is not long according to your picture. Generally, processing records very slow, which caused high back pressure, would result in checkpoint slow then. This is because the task has to spend more time to process input records before processing the checkpoint barrier. yeah, it seems like I need to take a closer look at my custom trigger and aggregation function. Thanks a lot :-) Regards, - Dongwon [1] application_1540810479442_0098.xlsx (attached) [2] On Wed, Dec 12, 2018 at 12:34 AM Yun Tang <[hidden email]> wrote:
|
|
|
Hi Dongwon
After reading your details of checkpoints in your attached excel file, and compare with your JM's log. I think the checkpoint-15 of task#244, which is the task with attempt id e81a7fb90d05da2bcec02a34d6f821e3, hangs for more than one hour. I strongly suggest
you could offer task manager log of this task during 2018-12-10 17:54:36 to 2018-12-10 19:15:44, in which something must happened, perhaps the sink met some problem to write. Any metrics of machine's network environment might also help. Once the task#244 went
through 19:15, the pending checkpoint 16 and 17 for this task completed very soon.
Best
Yun Tang
From: Dongwon Kim <[hidden email]>
Sent: Wednesday, December 12, 2018 0:34 To: [hidden email] Cc: user; Keuntae Park Subject: Re: Very slow checkpoints occasionally occur Hi Yun!
Thanks a lot for your email.
this task might be a hot-spot which receives more records I don't think we have partition skew.
In the attached excel file [1], there are six worksheets each corresponding to a checkpoint.
In each worksheet, I copy and paste the detailed information of checkpoint attempts for session window tasks.
Task #244 is the one so I highlight the line 253 of each worksheet.
The state size of task #244 at ckpt14, ckpt18, ckpt19 are similar to others.
It task #244 were a hot spot, it would have much larger state than others.
or have lower performance due to the node running this task is in high load. unfortunately, as shown in [2], all of eight worker nodes are not that busy during the period :-(
What's more, very slow checkpoint of one task should not cause high back pressure in general. Only the sync-part of checkpoint would impact the topology task to process records, however, the part of duration is not long according to your picture. Generally, processing records very slow, which caused high back pressure, would result in checkpoint slow then. This is because the task has to spend more time to process input records before processing the checkpoint barrier. yeah, it seems like I need to take a closer look at my custom trigger and aggregation function.
Thanks a lot :-)
Regards,
- Dongwon
[1] application_1540810479442_0098.xlsx (attached)
[2]
On Wed, Dec 12, 2018 at 12:34 AM Yun Tang <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |