Very long checkpointing sync times.

Very long checkpointing sync times.

|
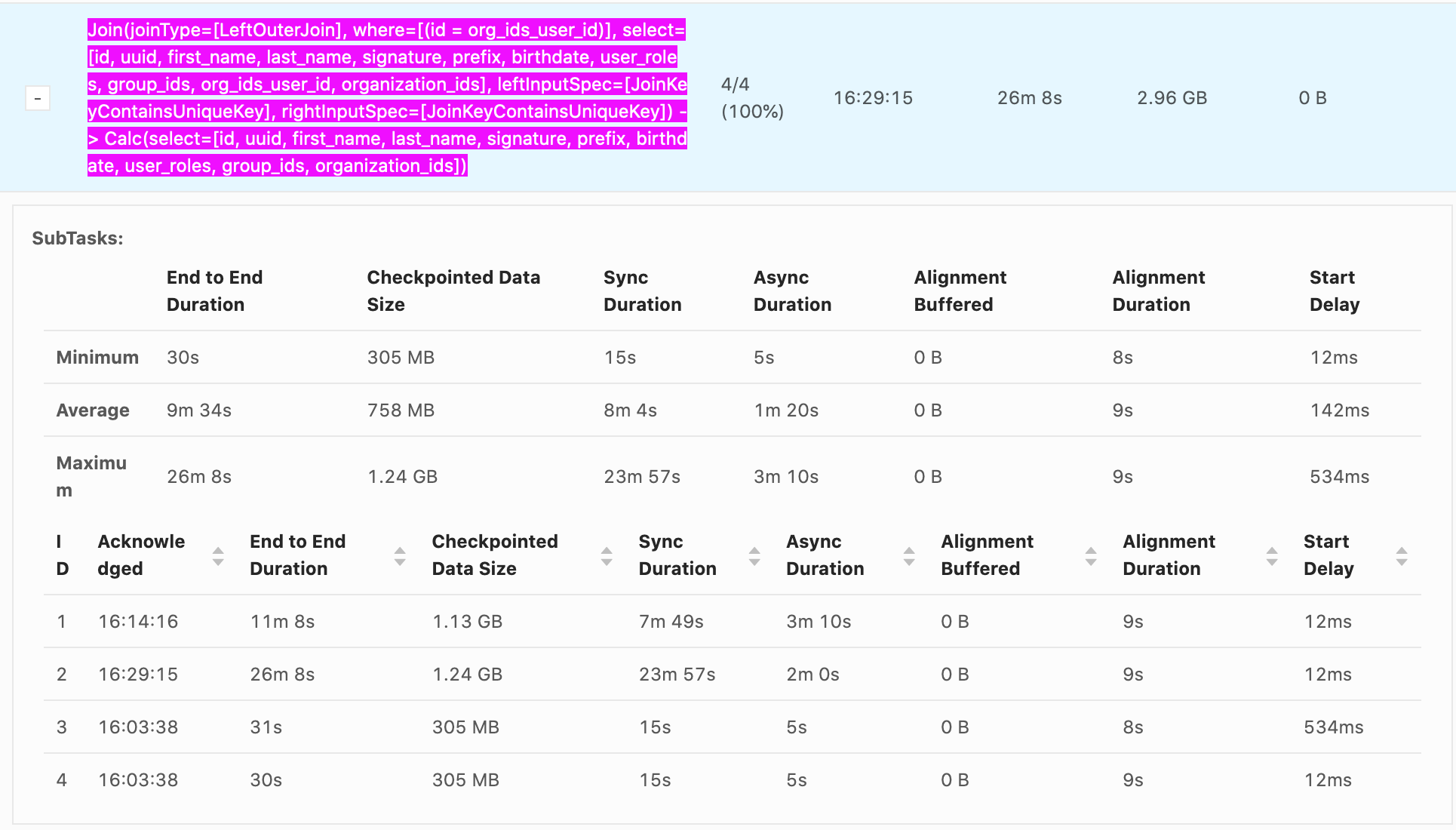
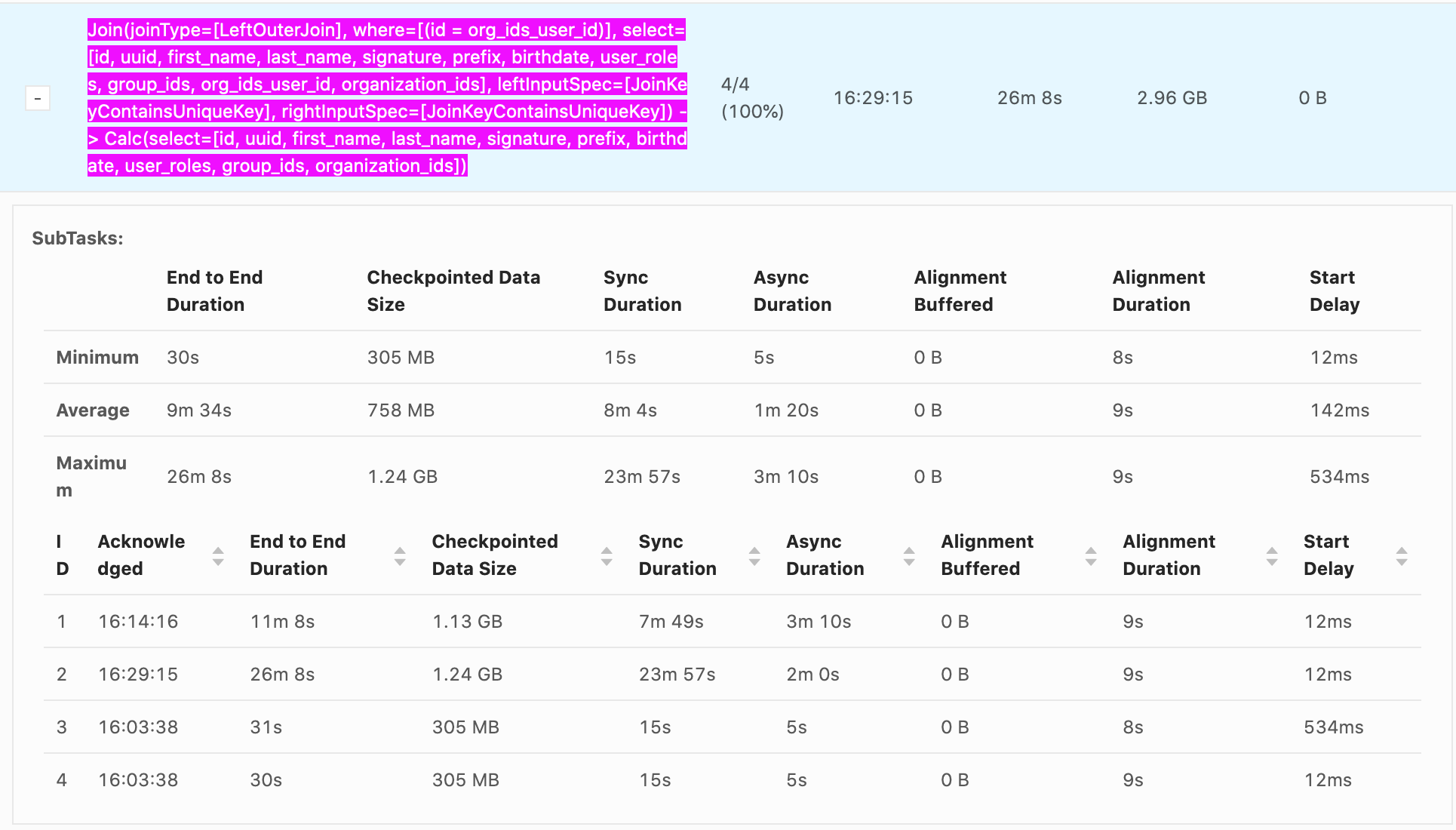
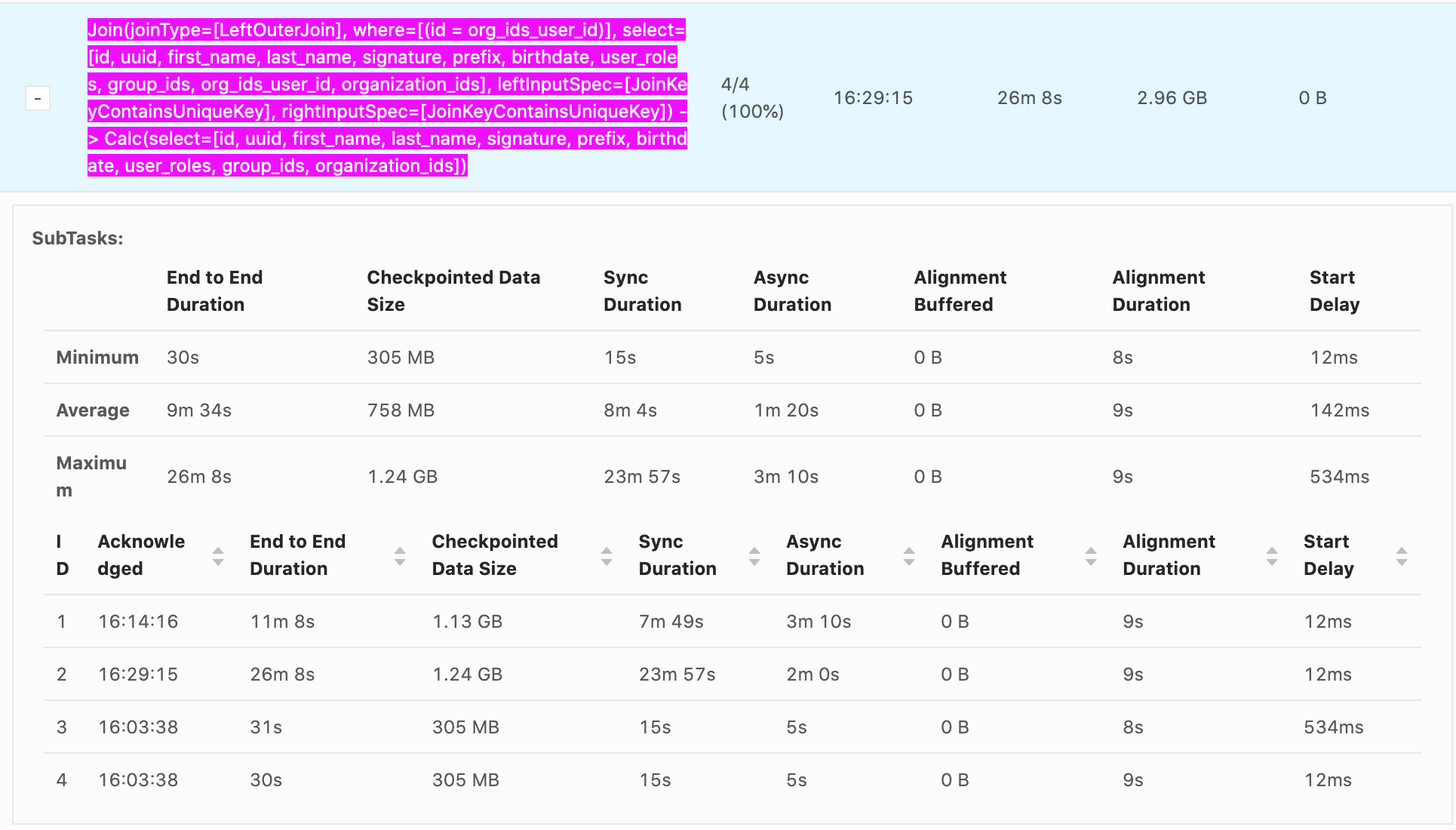
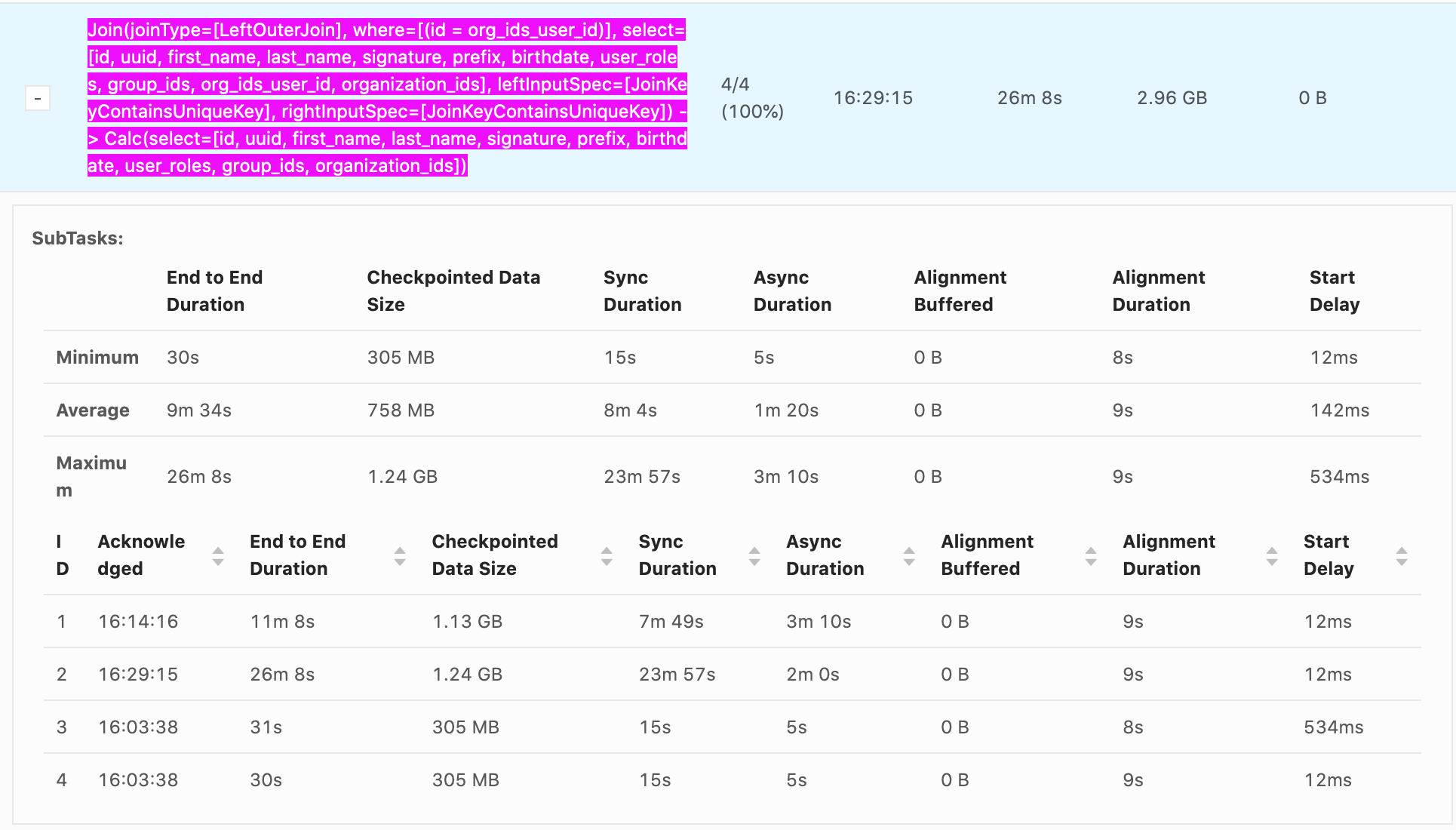
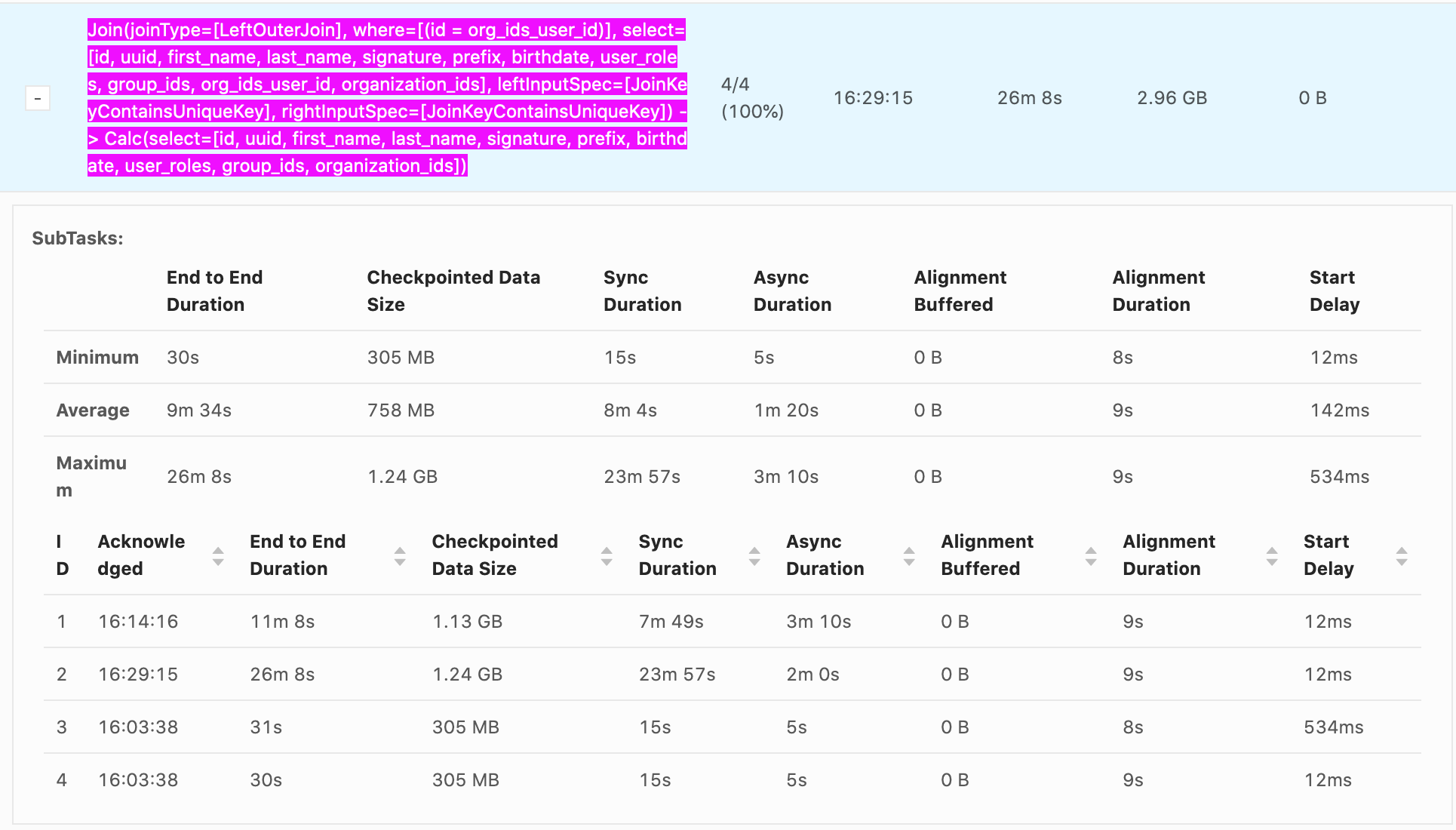
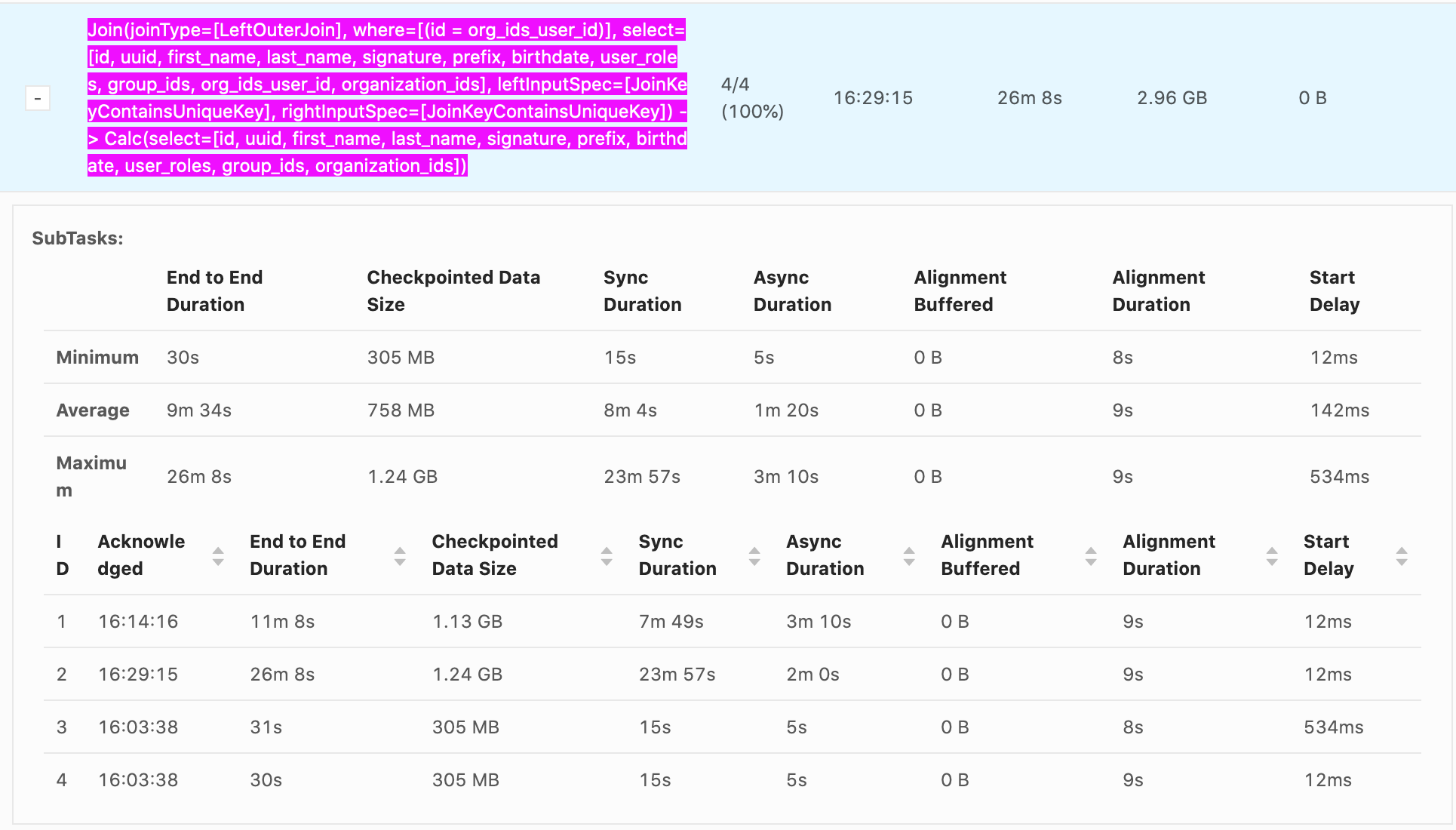
Hello, Our checkpointing times can reach nearly 30 min, it's generally from Sync Duration which seems to be related non-linearly to the size of the data being checkpointed. e.g. recorded values Sync Duration -> Checkpoint Data Size 22s -> 732 MB 23m 57s -> 1.24 GB 7m 49s -> 1.13 GB 11s -> 33.0 MB 10s -> 867 MB 12s -> 250 MB It seems that as soon as a GB is exceeded the checkpoint time increases explosively. Incremental checkpoints are turned on. RocksDB is our state backend. Checkpoints go to S3. System is 16 vCPUS and 100 GB of memory are given to Flink. The vast majority of the time is from Sync Duration, Async Duration is almost always an order of magnitude faster, Alignment duration is almost always within 10-20s which isn't as big of an issue. What is happening during Sync Duration which could cause such long checkpoints? Are there any recommended methods to optimize it? Example photo: 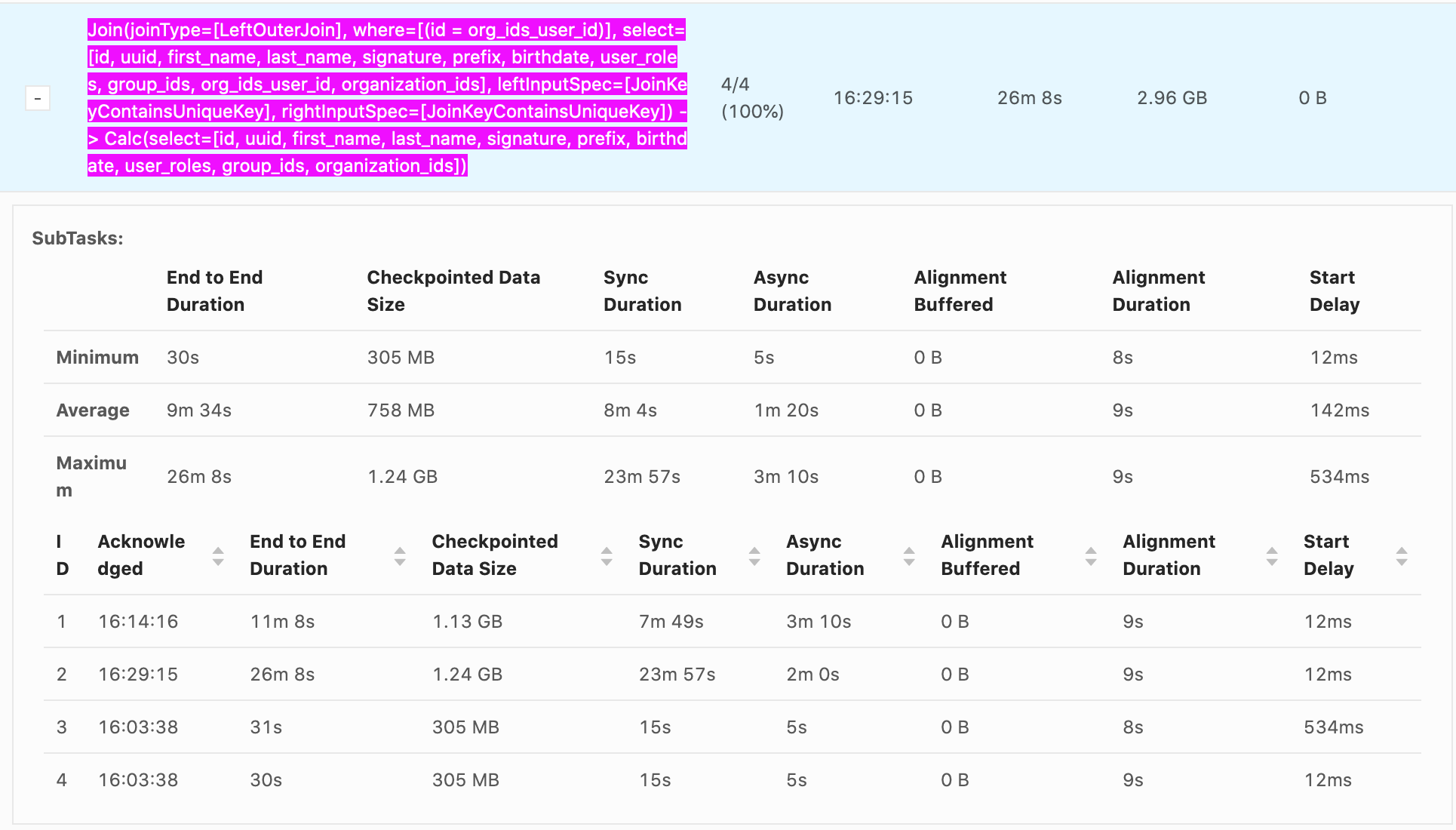 Thanks! -- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
Hi Rex.
The sync phase of RocksDB incremental checkpoint is only calling checkpoint.createCheckpoint [1] which mainly involves memory flush to disk and file hard links. To be honest, it's really weird when you could have such long time to finish sync phase with just
1GB data in total. Have you ever checked what the thread is doing via jstack and disk io usage when the sync phase of that sub-task happened?
Best
Yun Tang
From: Rex Fenley <[hidden email]>
Sent: Saturday, January 9, 2021 9:35 To: user <[hidden email]> Cc: Brad Davis <[hidden email]> Subject: Very long checkpointing sync times. Hello,
Our checkpointing times can reach nearly 30 min, it's generally from Sync Duration which seems to be related non-linearly to the size of the data being checkpointed.
e.g. recorded values
Sync Duration -> Checkpoint Data Size
22s
-> 732 MB
23m 57s -> 1.24 GB 7m 49s -> 1.13 GB 11s -> 33.0 MB 10s -> 867 MB 12s -> 250 MB It seems that as soon as a GB is exceeded the checkpoint time increases explosively.
Incremental checkpoints are turned on. RocksDB is our state backend. Checkpoints go to S3. System is 16 vCPUS and 100 GB of memory are given to Flink.
The vast majority of the time is from Sync Duration, Async Duration is almost always an order of magnitude faster, Alignment duration is almost always within 10-20s which isn't as big of an issue.
What is happening during Sync Duration which could cause such long checkpoints? Are there any recommended methods to optimize it?
Example photo:
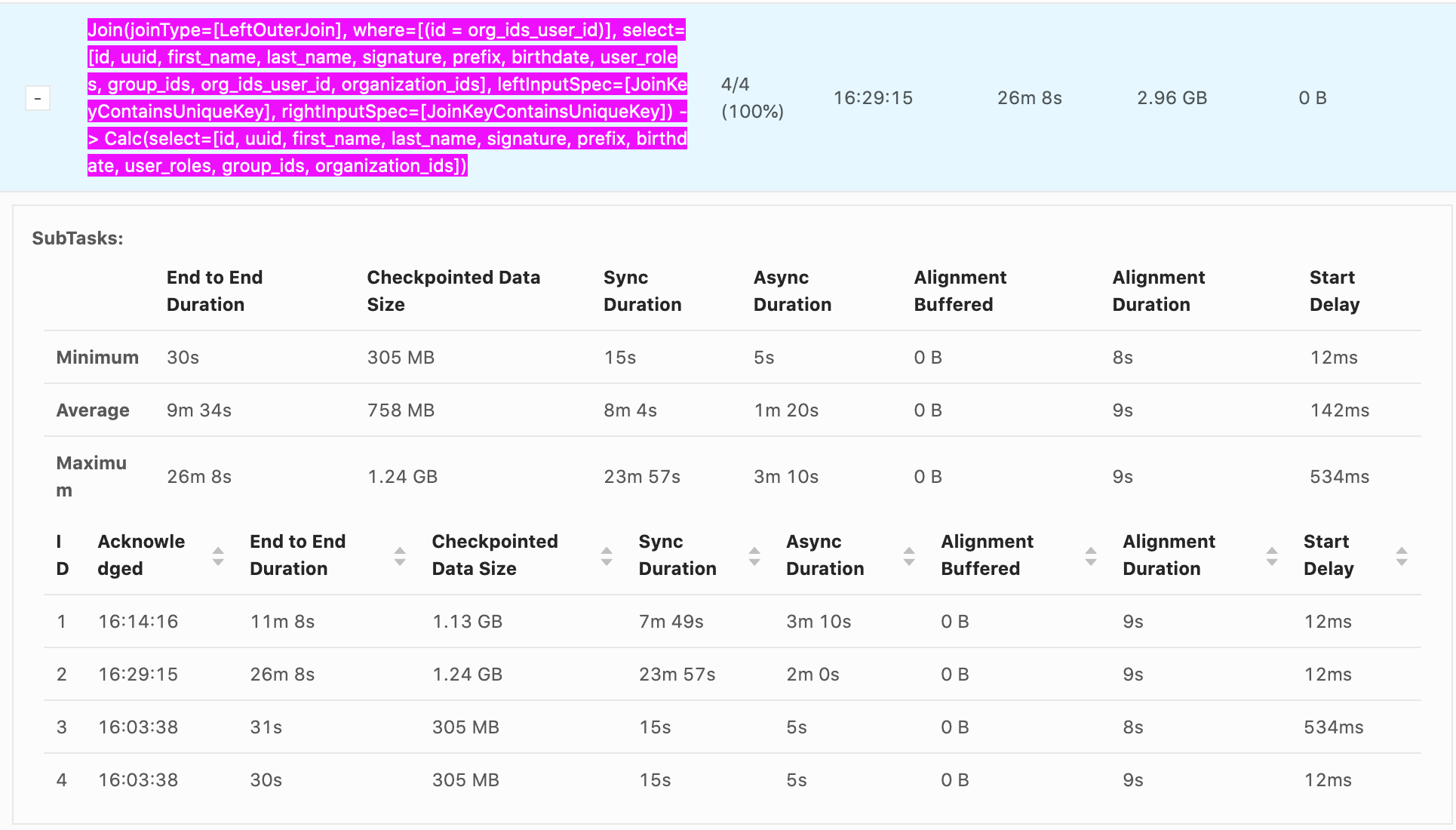 Thanks!
--
Rex Fenley
|
Software Engineer - Mobile and Backend
Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
I ended up setting ``` RocksDBStateBackend stateBackend = new RocksDBStateBackend(getStateUrl(), true); stateBackend.setPredefinedOptions(PredefinedOptions.FLASH_SSD_OPTIMIZED); ``` which sets the compaction concurrency to 4 it looks like and now we're seeing more stable/consistent checkpointing times at ~1-3 min and majority due to alignment time, a little attributed to async time. We want to drop the alignment time and async time now. Thanks! On Mon, Jan 11, 2021 at 4:10 AM Yun Tang <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
In reply to this post by Yun Tang
Hi
It seems given more background threads to RocksDB could help reduce checkpointing time in your case. Maybe you could also use async-profiler [1] to see the stack frame.
To reduce the alignment time, you could turn on AT-LEAST-ONCE mode [2] or choose unaligned checkpoints [3].
To reduce the async time, you could increase the thread number of uploading files [4]
If you want to know which thread to look, just focus on the main thread of StreamTask, which starts with the operator name.
Best
Yun Tang
From: Brad Davis <[hidden email]>
Sent: Tuesday, January 12, 2021 8:59 To: Yun Tang <[hidden email]> Subject: Re: Very long checkpointing sync times. I've tried running jstack but given the dozens (hundreds?) of threads it's sometimes hard to determine what we're looking for. I know that a number of the threads related to a given operator are given custom names... is there documentation on
what thread names one can look for for a given operator?
On Mon, Jan 11, 2021 at 4:10 AM Yun Tang <[hidden email]> wrote:
|
Re: Very long checkpointing sync times.
|
|
Hi, This is all great information, thank you. If we were to move to unaligned checkpointing or to "at least once", that would speed up checkpointing time, but would it speed up the how fast records are processed? As far as I understand, alignment time is a function of how fast records are making it through the system, simply getting rid of alignment time won't actually speed up whatever the bottleneck is, will it? We're hoping to get our end-to-end latency down to under a minute, making checkpoints faster is part of that, but really we need data flowing end-to-end that quickly and I think checkpointing time is a symptom of that larger issue. Is my thinking here correct? On Mon, Jan 11, 2021 at 6:39 PM Yun Tang <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
|
|
Hi Rex,
Reducing alignment time could help mitigate the influence on processing records. If you want to speed up processing records, the correct way is to find solution to increase throughput.
Increase the parallelism, detect whether existed hottest data and detect what caused backpressure would help increase the throughput.
Best
Yun Tang
From: Rex Fenley <[hidden email]>
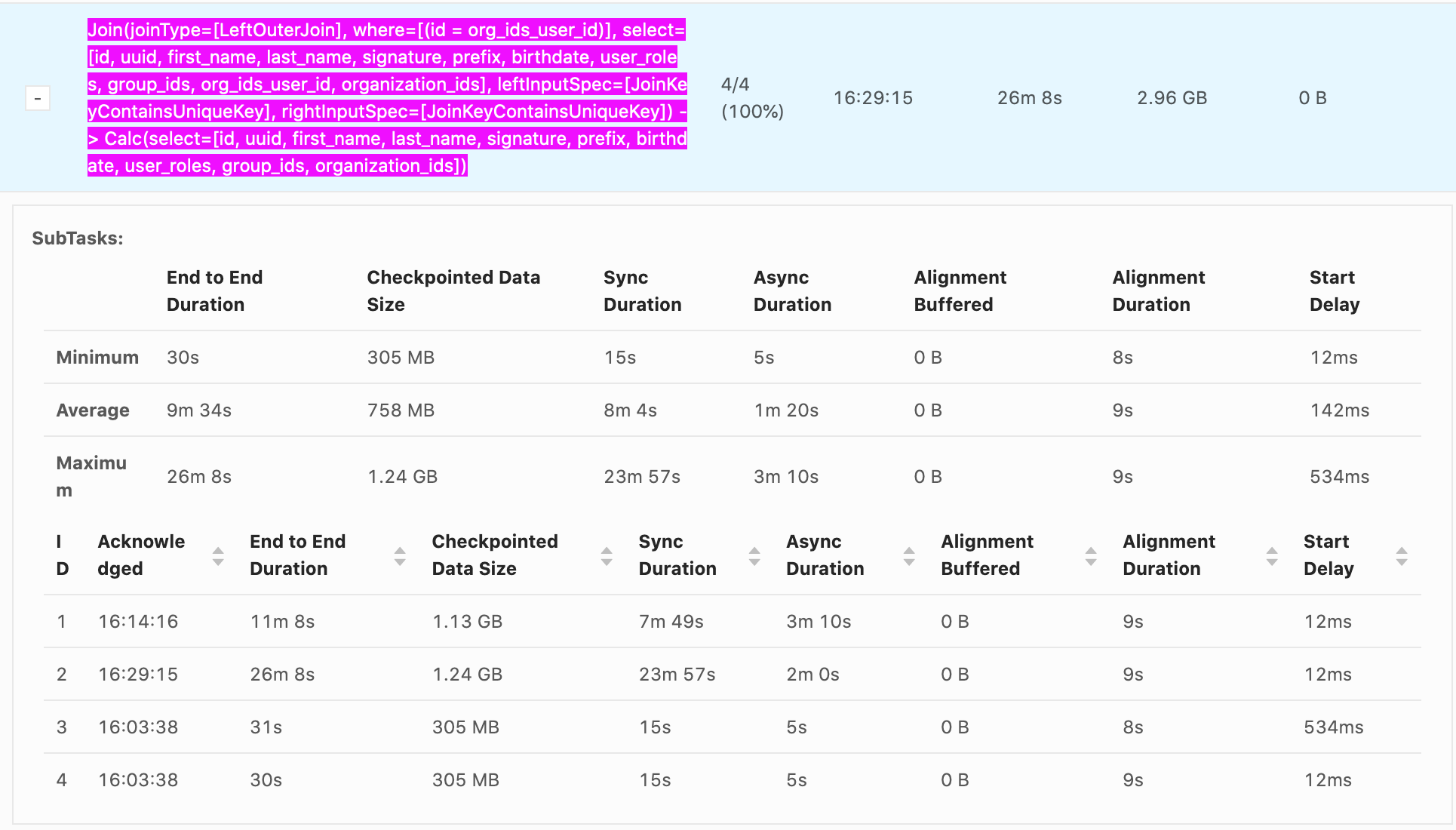
Sent: Wednesday, January 13, 2021 9:55 To: Yun Tang <[hidden email]> Cc: Brad Davis <[hidden email]>; user <[hidden email]> Subject: Re: Very long checkpointing sync times. Hi,
This is all great information, thank you. If we were to move to unaligned checkpointing or to "at least once", that would speed up checkpointing time, but would it speed up the how fast records are processed? As far as I understand, alignment time is a
function of how fast records are making it through the system, simply getting rid of alignment time won't actually speed up whatever the bottleneck is, will it?
We're hoping to get our end-to-end latency down to under a minute, making checkpoints faster is part of that, but really we need data flowing end-to-end that quickly and I think checkpointing time is a symptom of that larger issue.
Is my thinking here correct?
On Mon, Jan 11, 2021 at 6:39 PM Yun Tang <[hidden email]> wrote:
-- Rex Fenley
|
Software Engineer - Mobile and Backend
Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
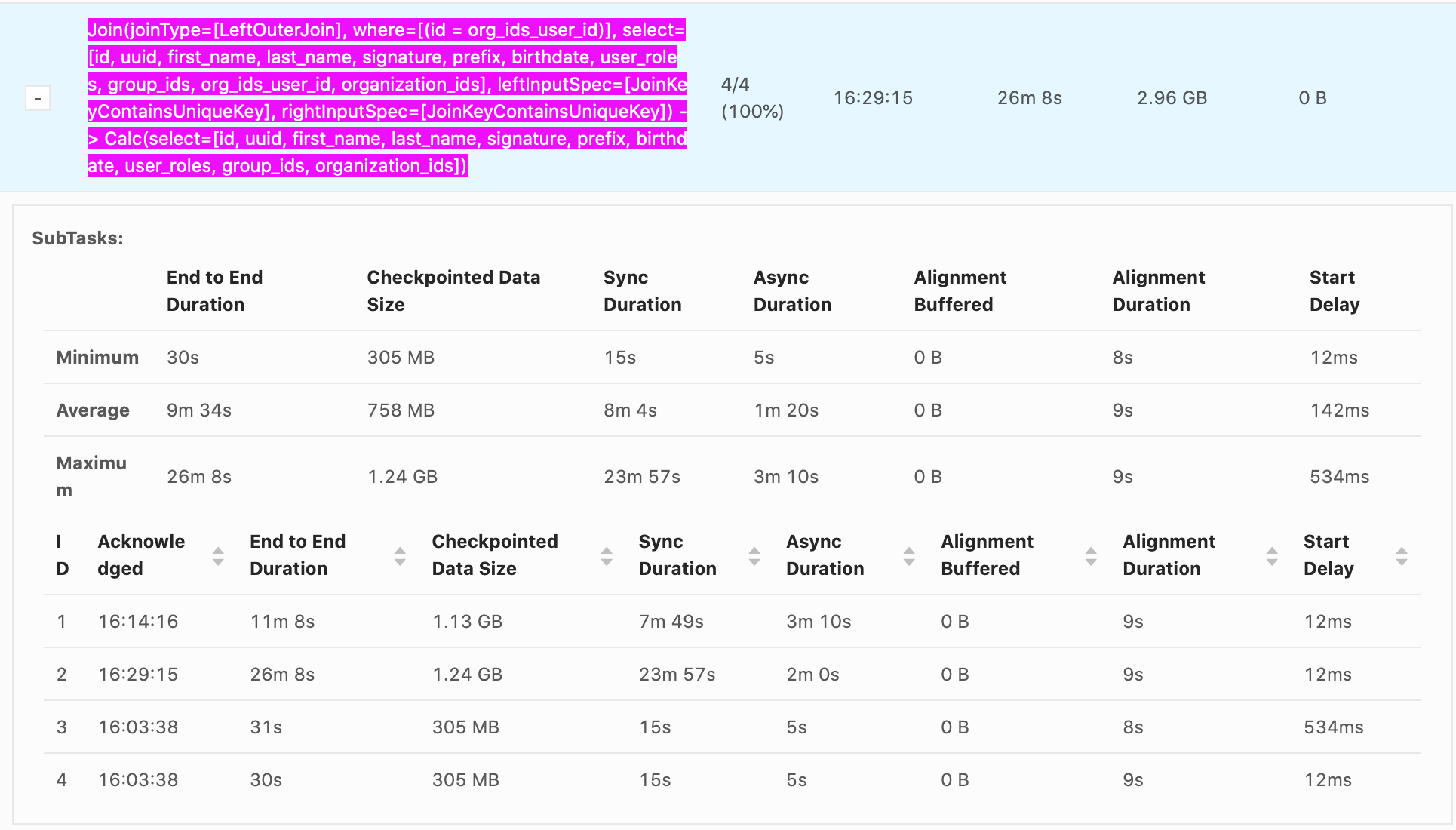
Hi Rex, if you want to decrease latency, checkpointing time is negligible if you are not using a sink that performs some two-phase commit protocol (I thought ES sink is not using it but I could be wrong). The typical culprit if you have a join is data skew. Did you check that? That would also show up as uneven resource utilization and backpressure. In general, any kind of backpressure usually destroys your latency goals [1]. Is your sink keeping up? You can also check if the record is staying too long in the network stack by enabling latency tracking [2]. If it turns out to be an issue you can trade throughput with latency: - decrease the network buffers by reducing network memory size [2] (set a max of 1gb and just half it as long as the job starts, you can also calculate that, but determining empirically usually works good enough) - additionally you might want to decrease taskmanager.memory.segment-size from 32kb. The network buffer is divided into segments and if you half the segment size, you can also half the network memory. - you can decrease execution.buffer-timeout from 100ms. All of these options together reduce the time a record is caught in the network stack without being actively processed. But usually you use these options only if your latency is already in the range of a few seconds and you want to push it down into milliseconds. On Wed, Jan 13, 2021 at 3:45 AM Yun Tang <[hidden email]> wrote:
-- Arvid Heise | Senior Java Developer Follow us @VervericaData -- Join Flink Forward - The Apache Flink Conference Stream Processing | Event Driven | Real Time -- Ververica GmbH | Invalidenstrasse 115, 10115 Berlin, Germany -- Ververica GmbHRegistered at Amtsgericht Charlottenburg: HRB 158244 B Managing Directors: Timothy Alexander Steinert, Yip Park Tung Jason, Ji (Toni) Cheng |
Re: Very long checkpointing sync times.
|
|
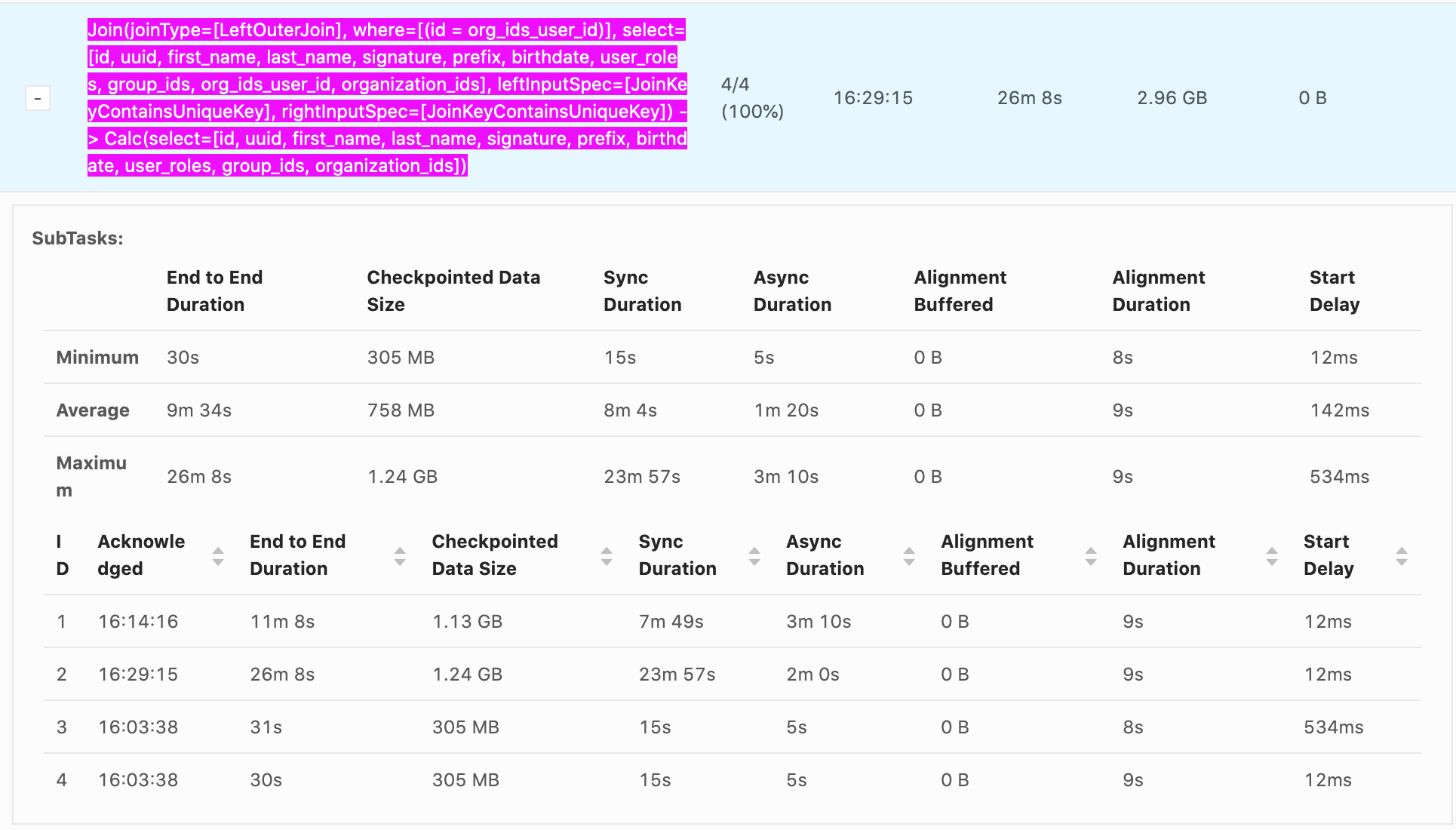
Thank you, this information is very informative. From what Yun said, decreasing alignment time may require increasing total throughput. I'll try latency tracking and possibly increasing buffer sizes. Thanks! On Fri, Jan 15, 2021 at 2:50 AM Arvid Heise <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
In reply to this post by Yun Tang
Hi, We're still getting periodic sync duration from 1 to 10+ min long, generally corresponding with a larger checkpoint size. I ran a profiler and even though I saw `createCheckpoint` in there it was using almost 0 cpu and ~80ms. Most cpu time is spent in RocksDB get and seek0, but since the profiler was profiling java I can't look into what the C code is doing. Is `createCheckpoint` really all that's supposed to happen during sync duration? Is there some general way we can speed it up? Thanks! On Mon, Jan 11, 2021 at 4:10 AM Yun Tang <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
It looks like bloom filter on RockDB may not be set up by default for Flink? Is this correct? Would this help speed up the gets? Thanks! On Fri, Jan 22, 2021 at 7:15 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
This section [1] is a bit difficult to interpret, but >To set the total memory usage of RocksDB instance(s), Flink leverages a shared cache
and write buffer manager among all instances in a single slot.
The shared cache will place an upper limit on the three components that use the majority of memory
in RocksDB: block cache, index and bloom filters, and MemTables. makes it sound like bloom filters are enabled by default and >Moreover, the L0 level filter and index are pinned into the cache by default to mitigate performance problems makes it sound like they are pinned to the block cache for L0. Are the bloom filters using prefix extraction by default? I can't seem to find where in the code all these caches are set up. Thanks On Fri, Jan 22, 2021 at 8:56 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
We're still seeing very long sync times. To recap previous emails: We have periodic sync duration from 1
to 10+ min long, generally corresponding with a larger checkpoint size.
I ran a profiler and even though I saw `createCheckpoint` in there it
was using almost 0 cpu and ~80ms. Most cpu time is spent in RocksDB get
and seek0, but since the profiler was profiling java I can't look into
what the C code is doing. * Should I try turning on bloom filters to speed up gets or does managed memory already turn them on? Do they include prefix extraction by default? * Is `createCheckpoint` really all that's supposed to happen during sync duration? Is there some general way we can speed it up? * Any other suggestions? Thanks! On Sat, Jan 23, 2021 at 3:23 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
Hi, We're still having a tough time with this. Does anyone have any suggestions? Thanks On Sat, Jan 30, 2021 at 2:03 PM Rex Fenley <[hidden email]> wrote:
-- Rex Fenley | Software Engineer - Mobile and Backend Remind.com | BLOG | FOLLOW US | LIKE US |
Re: Very long checkpointing sync times.
|
|
Hi, - Can you please update the screenshot or the stats? In particular, what are the sizes/sync/async durations of these problematic checkpoints compared to others? - You managed to reduce the duration mainly by increasing the number of flushing threads to 4, right? Did you try to increase it further [1]? - Does it change anything if you increase checkpointing frequency? (by decreasing execution.checkpointing.interval or execution.checkpointing.min-pause [2]) - Do you have concurrent checkpoints enabled [3]? - Did you try non-incremental snapshots [4] and what numbers did you get? Sync phase should be shorter, if state updates are not incremental (e.g. appends) there should be no difference in async phase. Regards,
Roman On Fri, Feb 5, 2021 at 5:49 PM Rex Fenley <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |