User ClassLoader leak on job restart

User ClassLoader leak on job restart

|
Environment/Context:
Flink 1.5.2
Beam 2.7.0
AWS EMR 5.17.0
Orchestrator: YARN
Nature of job:
We execute our job by creating a fresh YARN session each time using
`flink run`
We have noticed that when our job restarts due to an exception, the number of classes loaded increases which in turn, pushes the MetaSpace memory usage. Eventually after a number of restarts YARN will kill the container for pushing the memory beyond its
physical limits.
My colleagues and I have documented this in the following issues (we recognise this might seem disorganised!)
We’ve tried setting the setting -XX:MetaSpaceSize=180M, which prevents YARN from killing the container, however the TaskManager throws the exception
java.lang.OutOfMemoryError: Metaspace
We’ve tried putting the job jar in the flink/lib directory but this seems to present more problems (log4j seems to stop working? We were also seeing issues around network connectivity to Amazon S3 which we cannot explain but can reproduce when using this
approach)
I took a heap dump of one of the task managers after it had restarted 6 times and followed this guide http://java.jiderhamn.se/2011/12/11/classloader-leaks-i-how-to-find-classloader-leaks-with-eclipse-memory-analyser-mat/
using Eclipse MAT
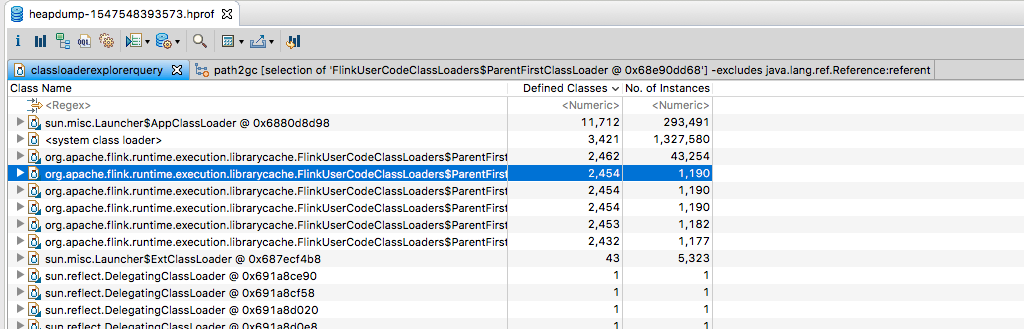
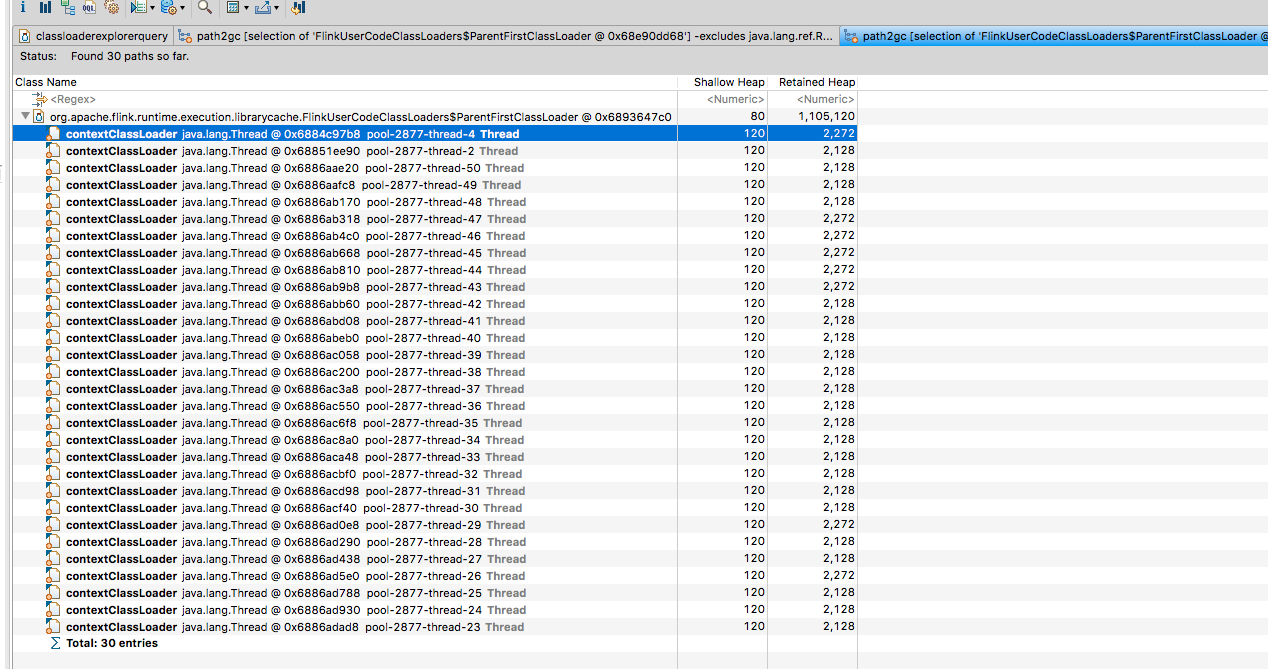
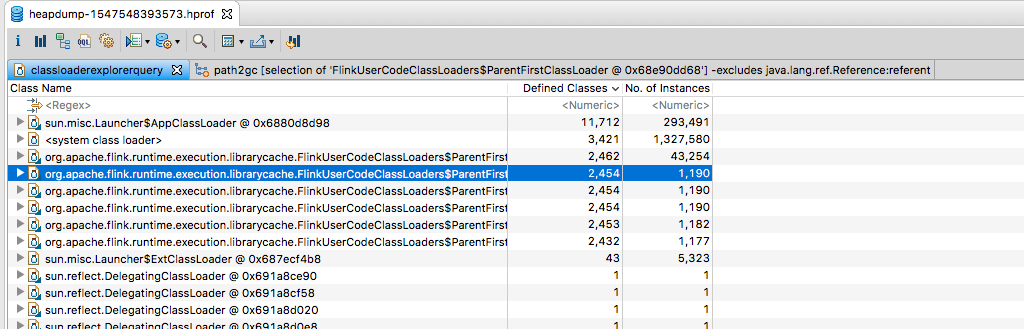
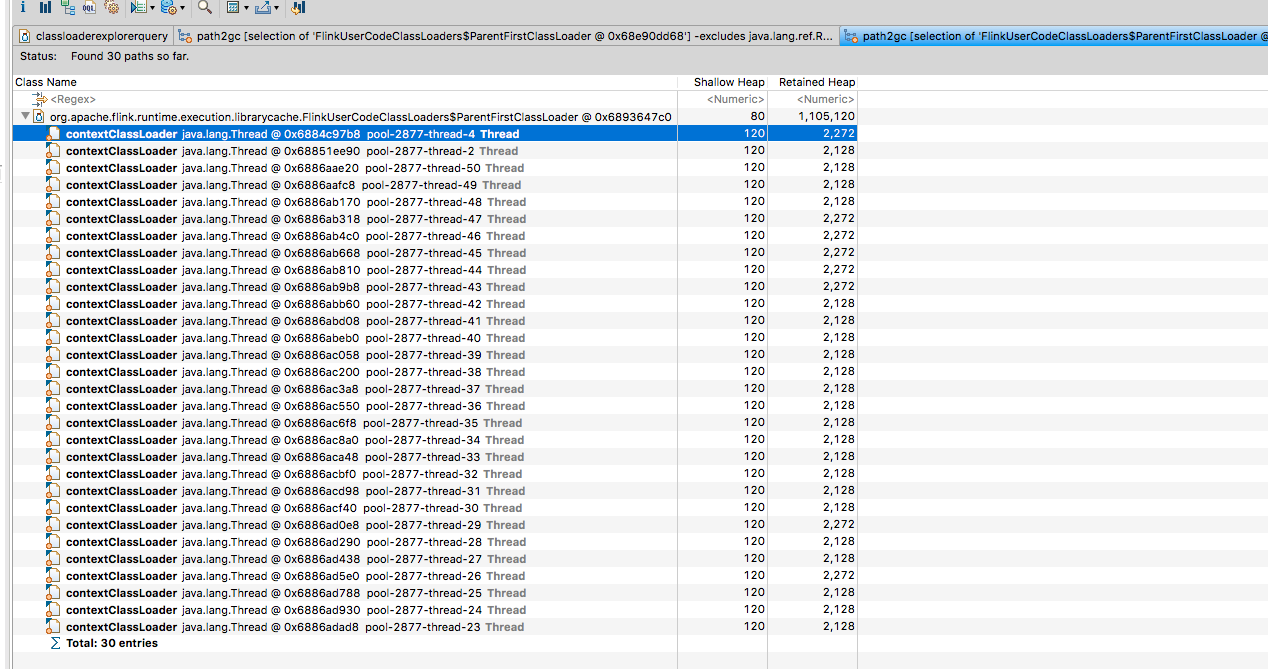
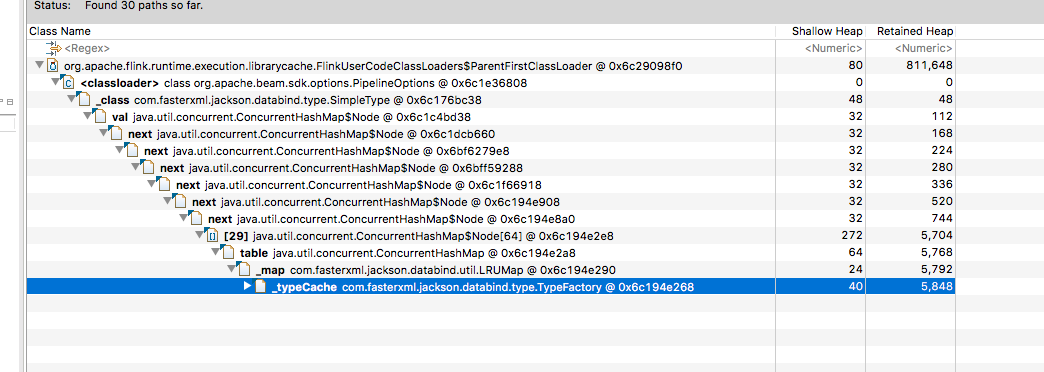
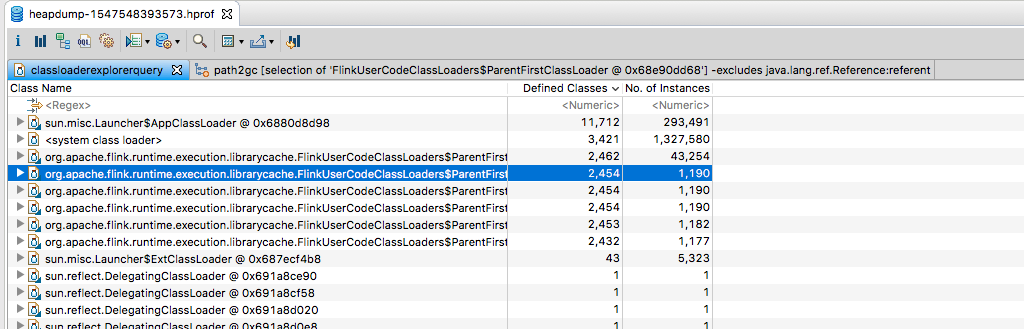
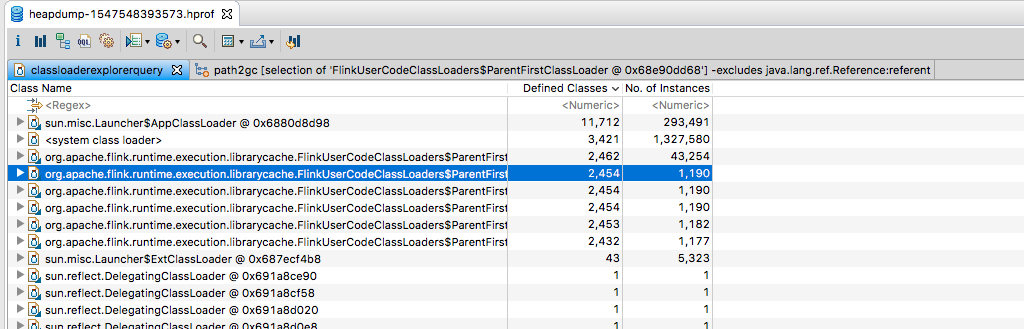
As you can see, there are 6 FlinkUserCodeClassLoader present in the heap dump
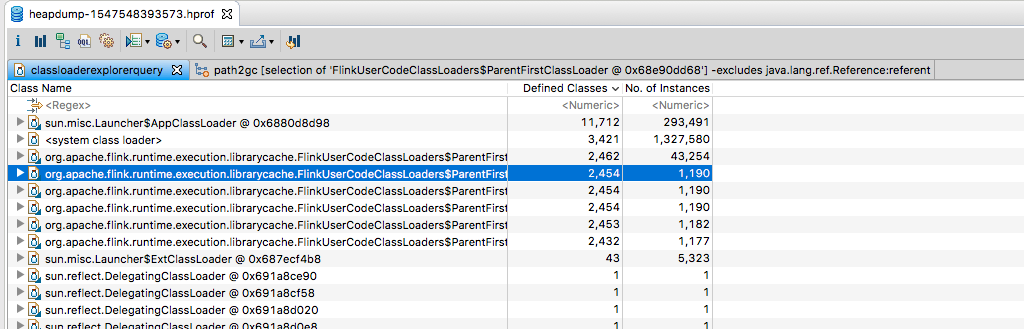 When selecting one of these and clicking Path to GC Roots -> With All References, all it seems to show is
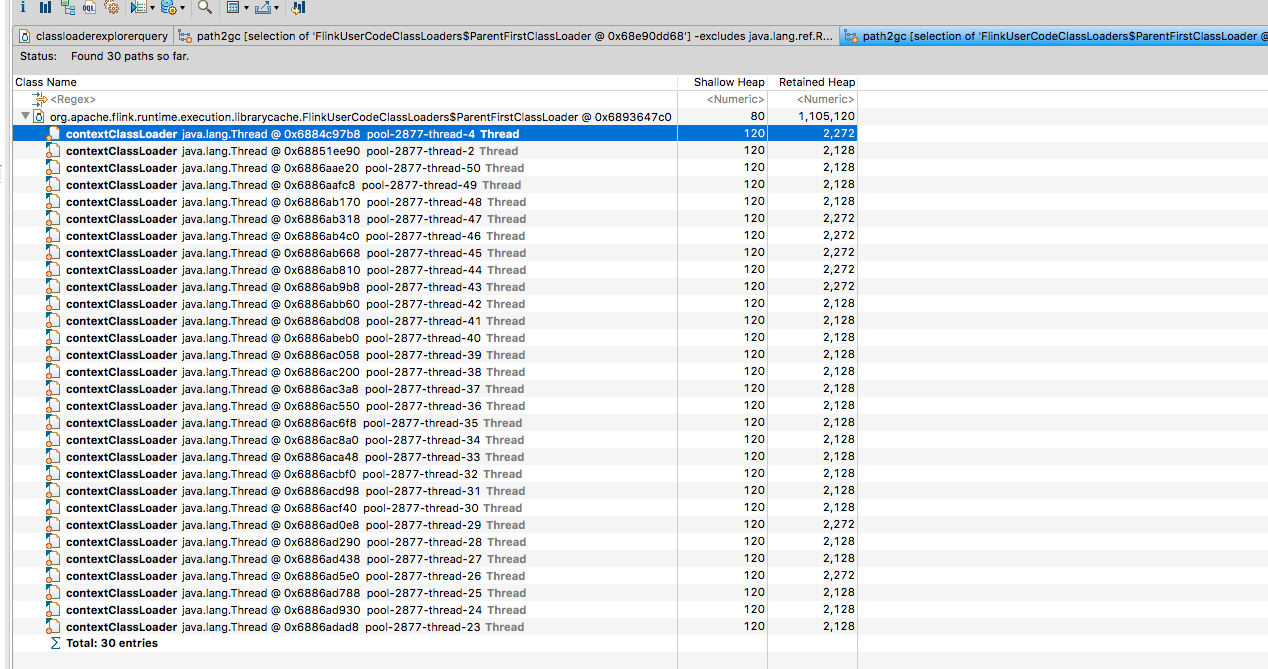 This is as far as I’m able to grasp in terms of understanding so I’m not sure what to look at next. One point of discussion on that blog post is around ThreadLocals keeping state around but I’m not sure.
Does anyone have any guidance/where to look next? Any help would be very much appreciated!
---------------------------- --------------------- |
Re: User ClassLoader leak on job restart
|
|
Hi Daniel, could you share the code of minimum viable example of the job failing this way to analyse the thread dump of it? Best, Andrey On Tue, Jan 15, 2019 at 3:59 PM Daniel Harper <[hidden email]> wrote:
|
Re: User ClassLoader leak on job restart
|
|
Hi Daniel, would it be possible to run directly on Flink in order to take Beam out of the equation? Moreover, I would be interested if the same problem still occurs with the latest Flink version or at least Flink 1.5.6. It is hard to tell whether Flink or the Beam Flink runner causes the class loader leak. Cheers, Till On Tue, Jan 15, 2019 at 7:17 PM Andrey Zagrebin <[hidden email]> wrote:
|
Re: User ClassLoader leak on job restart
|
|
Hi Andrew, Til,
Redoing the job in Flink will take a while, and upgrading to a different version of Flink is tricky (we use EMR)
However, I was just working on putting together a minimal job, when I noticed something that might be interesting/might be a red herring.
I enabled the following settings on the job
-XX:MaxMetaspaceSize=150M
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/dump/
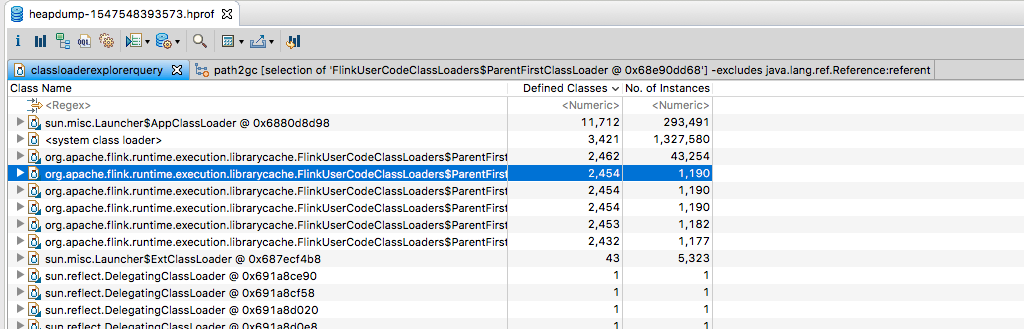
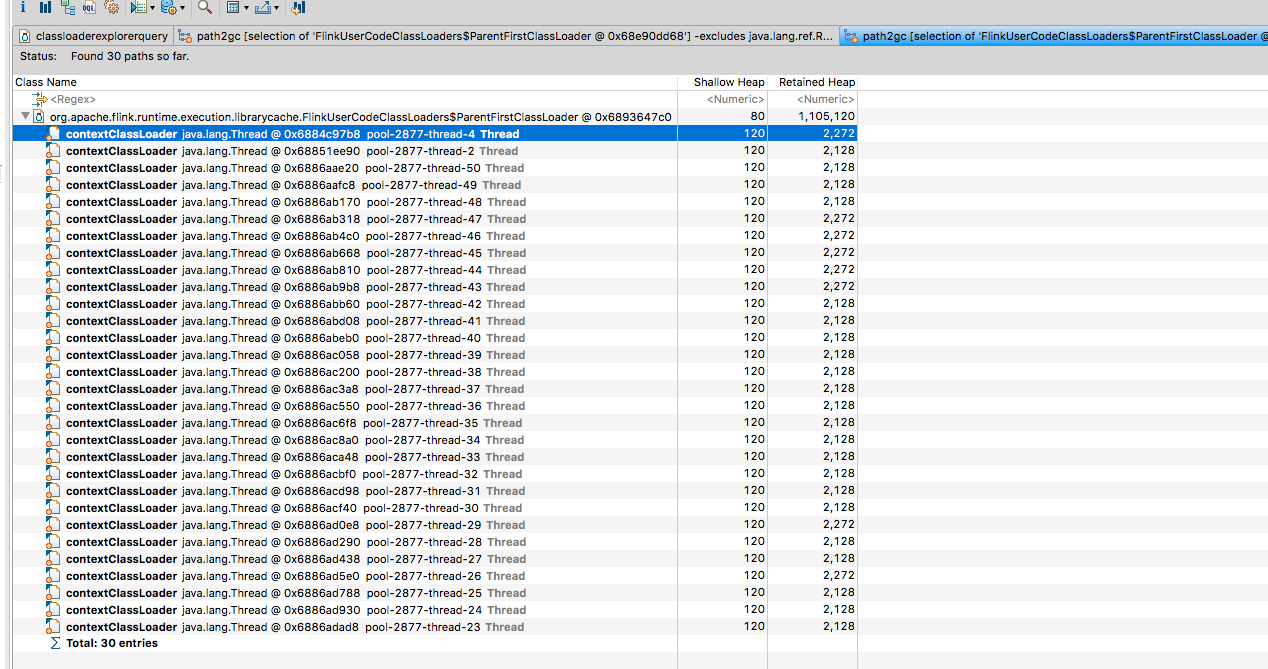
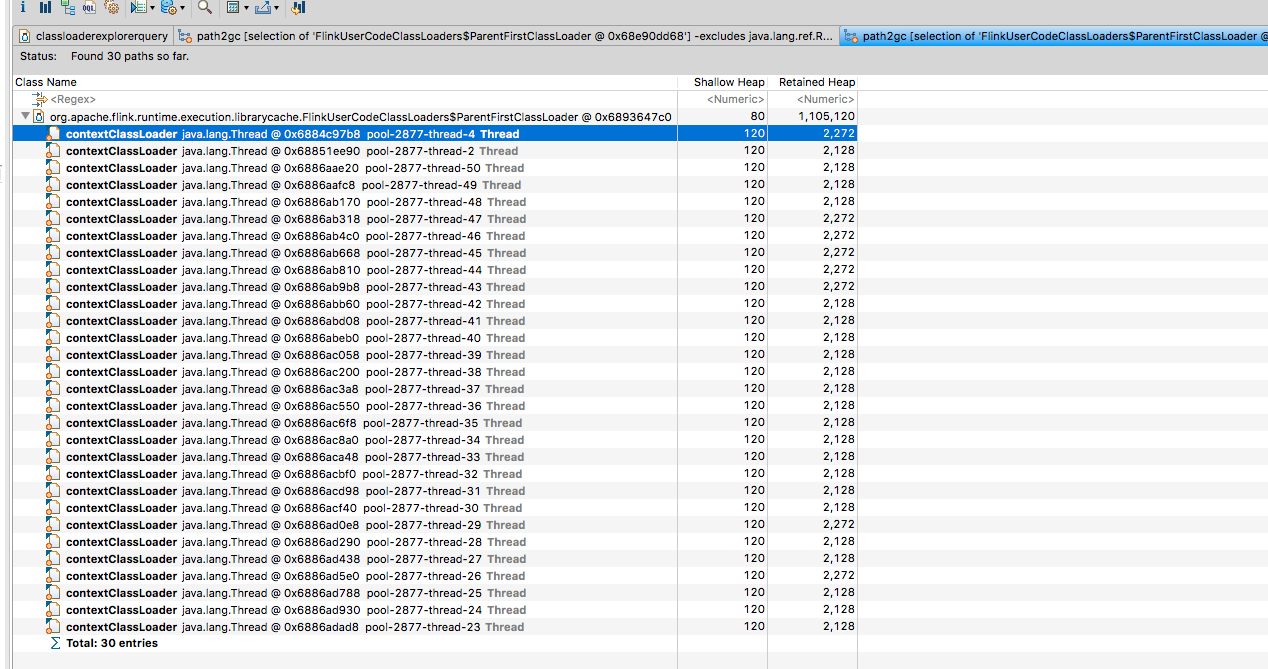
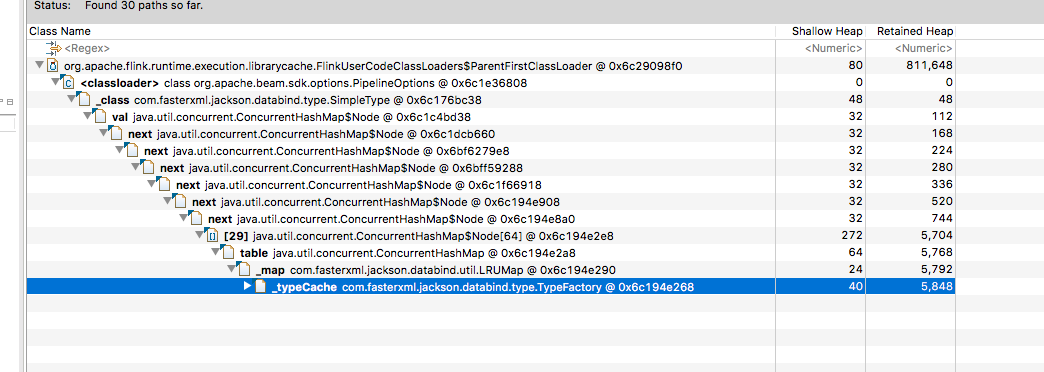
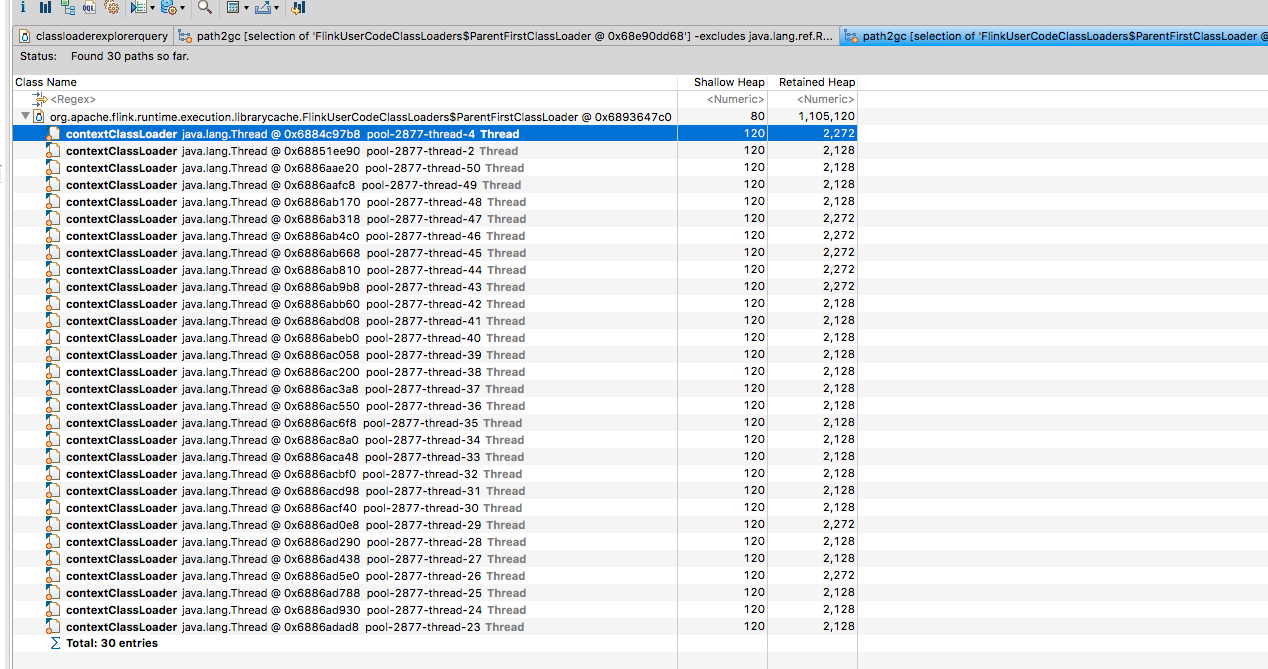
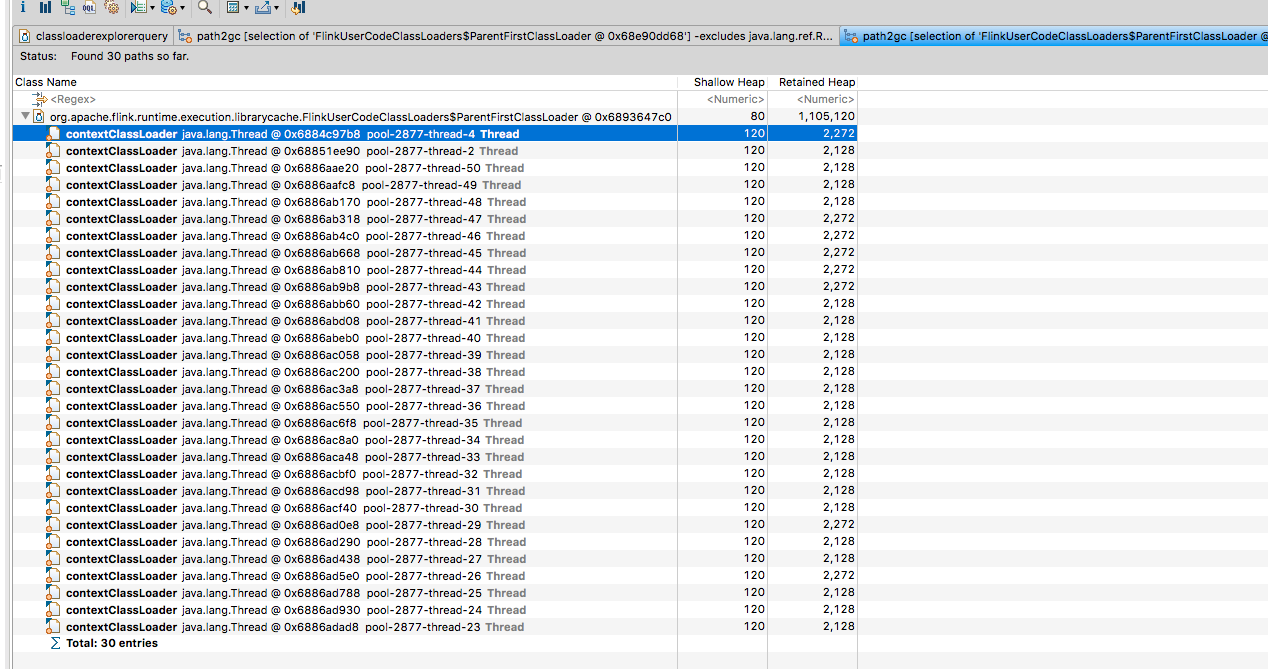
This caused the job to dump the heap dumps in the above location (previously I’d taken a heap dump before the OOM). Redoing the same process of downloading one of the heap dumps, looking at
the ‘lingering’ class loaders and then clicking a FlinkUserClassLoader -> GC Roots -> All references I could see the following
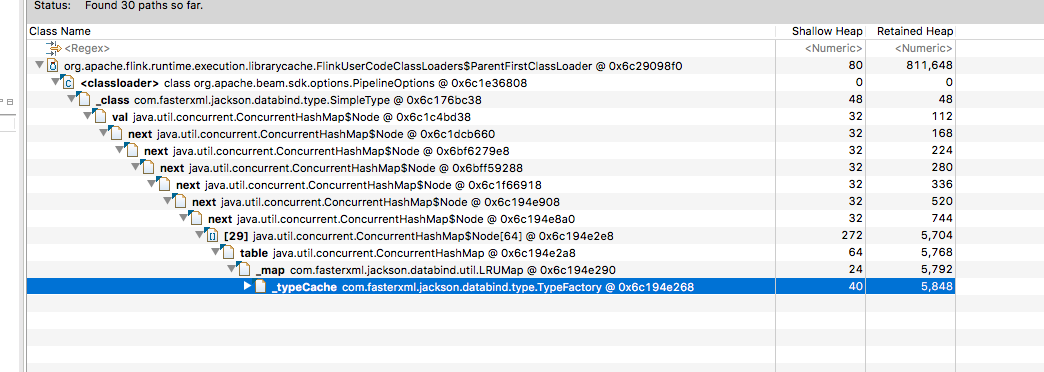
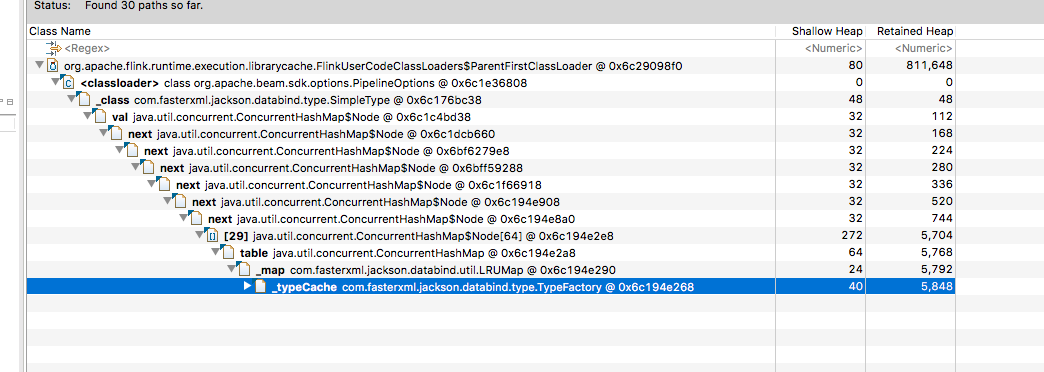 This looks to me like https://github.com/FasterXML/jackson-databind/issues/1363 and looks like it stems from the beam
PipelineOptions class (at least that’s the way I’m interpreting it)
I’m going to try and reproduce this with a simple job and raise it on the BEAM mailing list…
Will tell you how I get on
From: Till Rohrmann <[hidden email]>
Date: Wednesday, 16 January 2019 at 09:56 To: Andrey Zagrebin <[hidden email]> Cc: Daniel Harper <[hidden email]>, "[hidden email]" <[hidden email]> Subject: Re: User ClassLoader leak on job restart Hi Daniel,
would it be possible to run directly on Flink in order to take Beam out of the equation? Moreover, I would be interested if the same problem still occurs with the latest Flink version or at least Flink 1.5.6. It is hard to tell whether Flink or the Beam
Flink runner causes the class loader leak.
Cheers,
Till
On Tue, Jan 15, 2019 at 7:17 PM Andrey Zagrebin <[hidden email]> wrote:
---------------------------- --------------------- |
Re: User ClassLoader leak on job restart
|
|
Thanks for the update Daniel. This looks indeed like a problem originating from Beam. Keep us posted what the Beam community says. Cheers, Till On Wed, Jan 16, 2019 at 5:18 PM Daniel Harper <[hidden email]> wrote:
|
Re: User ClassLoader leak on job restart
|
|
Yep, looks like we’ve found it!
Raised on the mailing list
Ticket raised: https://jira.apache.org/jira/browse/BEAM-6460
From: Till Rohrmann <[hidden email]>
Date: Thursday, 17 January 2019 at 12:30 To: Daniel Harper <[hidden email]> Cc: Andrey Zagrebin <[hidden email]>, "[hidden email]" <[hidden email]> Subject: Re: User ClassLoader leak on job restart Thanks for the update Daniel. This looks indeed like a problem originating from Beam. Keep us posted what the Beam community says.
Cheers,
Till
On Wed, Jan 16, 2019 at 5:18 PM Daniel Harper <[hidden email]> wrote:
---------------------------- --------------------- |
Re: User ClassLoader leak on job restart
|
|
Great to hear and thanks a lot for debugging the problem! Cheers, Till On Fri, Jan 18, 2019 at 9:45 AM Daniel Harper <[hidden email]> wrote:
|
| Free forum by Nabble | Edit this page |