Upsert Kafka SQL Connector used as a sink does not generate an upsert stream

Upsert Kafka SQL Connector used as a sink does not generate an upsert stream

|
Hi! I have a question related to the Upsert Kafka SQL Connector, when used as a sink. For what I have tested, it does not generate an upsert stream in Kafka, but the Flink 1.12 documentation states that it does: “As a sink, the upsert-kafka connector can consume a changelog stream.
It will write INSERT/UPDATE_AFTER data as normal Kafka messages value, and write DELETE data as Kafka messages with null values (indicate tombstone for the key). Flink will guarantee the message ordering on the primary key by partition data on the values
of the primary key columns, so the update/deletion messages on the same key will fall into the same partition.” I have implemented a simple proof of concept of this connector, and in my Kafka output topic the UPSERT events are encoded with 2 Kafka events:
My expected behavior is that it only writes 1 single message (a normal event with the new value associated with that key) and, therefore, it does not write a tombstone message, which is not necessary. I just wanted to know if I am doing something wrong, or if the documentation is mistaken, and this connector always generates a tombstone message + a normal event, for each UPSERT event. Below is all the info related to the proof of concept I did with the connector: Source code
// Define env final
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); EnvironmentSettings envSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); final
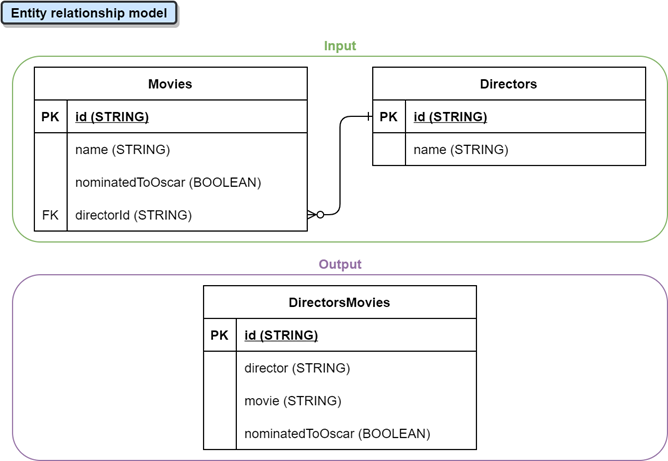
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, envSettings); // * Input tables // 1. Movies Table tableEnv.executeSql(Utils.getResourcesFileContent("ddl/create-table-input-movies.sql")); // 2. Directors Table tableEnv.executeSql(Utils.getResourcesFileContent("ddl/create-table-input-directors.sql")); // * Output tables // 1. DirectorsMovies Table tableEnv.executeSql(Utils.getResourcesFileContent("ddl/create-table-output-directors-movies.sql")); // Run SQL Query Table queryTable = tableEnv.sqlQuery(Utils.getResourcesFileContent("dml/join-query.sql")); queryTable.executeInsert("DirectorsMovies"); // Execute Flink job env.execute("Flink SQL Job"); Entity relationship model
Table definitions
CREATE
TABLE Movies
(
id STRING, name STRING, nominatedToOscar
BOOLEAN, directorId STRING,
PRIMARY
KEY
(id)
NOT ENFORCED )
WITH
(
'connector'
=
'upsert-kafka',
'topic'
=
'movies',
'properties.bootstrap.servers'
=
'localhost:9092',
'properties.group.id'
=
'flink-sql-poc',
'key.format'
=
'raw',
'value.format'
=
'json' ) CREATE
TABLE Directors
(
id STRING, name STRING,
PRIMARY
KEY
(id)
NOT ENFORCED )
WITH
(
'connector'
=
'upsert-kafka',
'topic'
=
'directors',
'properties.bootstrap.servers'
=
'localhost:9092',
'properties.group.id'
=
'flink-sql-poc',
'key.format'
=
'raw',
'value.format'
=
'json' ) CREATE
TABLE DirectorsMovies
(
id STRING, director STRING, movie STRING, nominatedToOscar
BOOLEAN,
PRIMARY
KEY
(id)
NOT ENFORCED )
WITH
(
'connector'
=
'upsert-kafka',
'topic'
=
'directors-movies',
'properties.bootstrap.servers'
=
'localhost:9092',
'properties.group.id'
=
'flink-sql-poc',
'key.format'
=
'raw',
'value.format'
=
'json' ) SQL query
SELECT
-- The id has the following format: "directorId:movieId"
CONCAT(Directors.id,
':',
Movies.id)
as
id,
-- Other fields Directors.name
AS director, Movies.name
AS movie, Movies.nominatedToOscar
AS nominatedToOscar FROM Movies
INNER
JOIN Directors
ON Movies.directorId
= Directors.id WHERE Movies.nominatedToOscar
=
TRUE Input events
Events are inserted in the same order as exposed here. TOPIC:
movies KEY:
movieId1 VALUE:
{ "id": "movieId1", "name": "Inception", "nominatedToOscar": true, "directorId": "directorId1" } TOPIC:
directors KEY:
directorId1 VALUE:
{ "id": "directorId1", "name":
"Christopher Nolan" } TOPIC:
directors KEY:
directorId1 VALUE:
{ "id": "directorId1", "name":
"Steven Spielberg" } Output events
Events appear in the output Kafka topic in the same order as exposed here. TOPIC:
directors-movies KEY:
directorId1:movieId1 VALUE:
{ "id": "directorId1:movieId1", "director":
"Christopher Nolan", "movie": "Inception", "nominatedToOscar": true } TOPIC:
directors-movies KEY:
directorId1:movieId1 VALUE:
INFO:
This is a DELETE event (tombstone), because the value is null TOPIC:
directors-movies KEY:
directorId1:movieId1 VALUE:
{ "id": "directorId1:movieId1", "director":
"Steven Spielberg", "movie": "Inception", "nominatedToOscar": true } As you can see, the job generates 3 output events, whereas my expectation is that the tombstone event is not generated. Expected output events
TOPIC:
directors-movies KEY:
directorId1:movieId1 VALUE:
{ "id": "directorId1:movieId1", "director":
"Christopher Nolan", "movie": "Inception", "nominatedToOscar": true } TOPIC:
directors-movies KEY:
directorId1:movieId1 VALUE:
{ "id": "directorId1:movieId1", "director":
"Steven Spielberg", "movie": "Inception", "nominatedToOscar": true } Thanks in advance, and best regards. Carlos Sanabria This message is for the designated recipient only and may contain privileged, proprietary, or otherwise confidential information. If you have received it in error, please notify the sender immediately and delete the original. Any other use of the e-mail by you is prohibited. Where allowed by local law, electronic communications with Accenture and its affiliates, including e-mail and instant messaging (including content), may be scanned by our systems for the purposes of information security and assessment of internal compliance with Accenture policy. Your privacy is important to us. Accenture uses your personal data only in compliance with data protection laws. For further information on how Accenture processes your personal data, please see our privacy statement at https://www.accenture.com/us-en/privacy-policy. ______________________________________________________________________________________ www.accenture.com |
| Free forum by Nabble | Edit this page |