Unaligned Checkpoint not working

Unaligned Checkpoint not working

|
Hi,
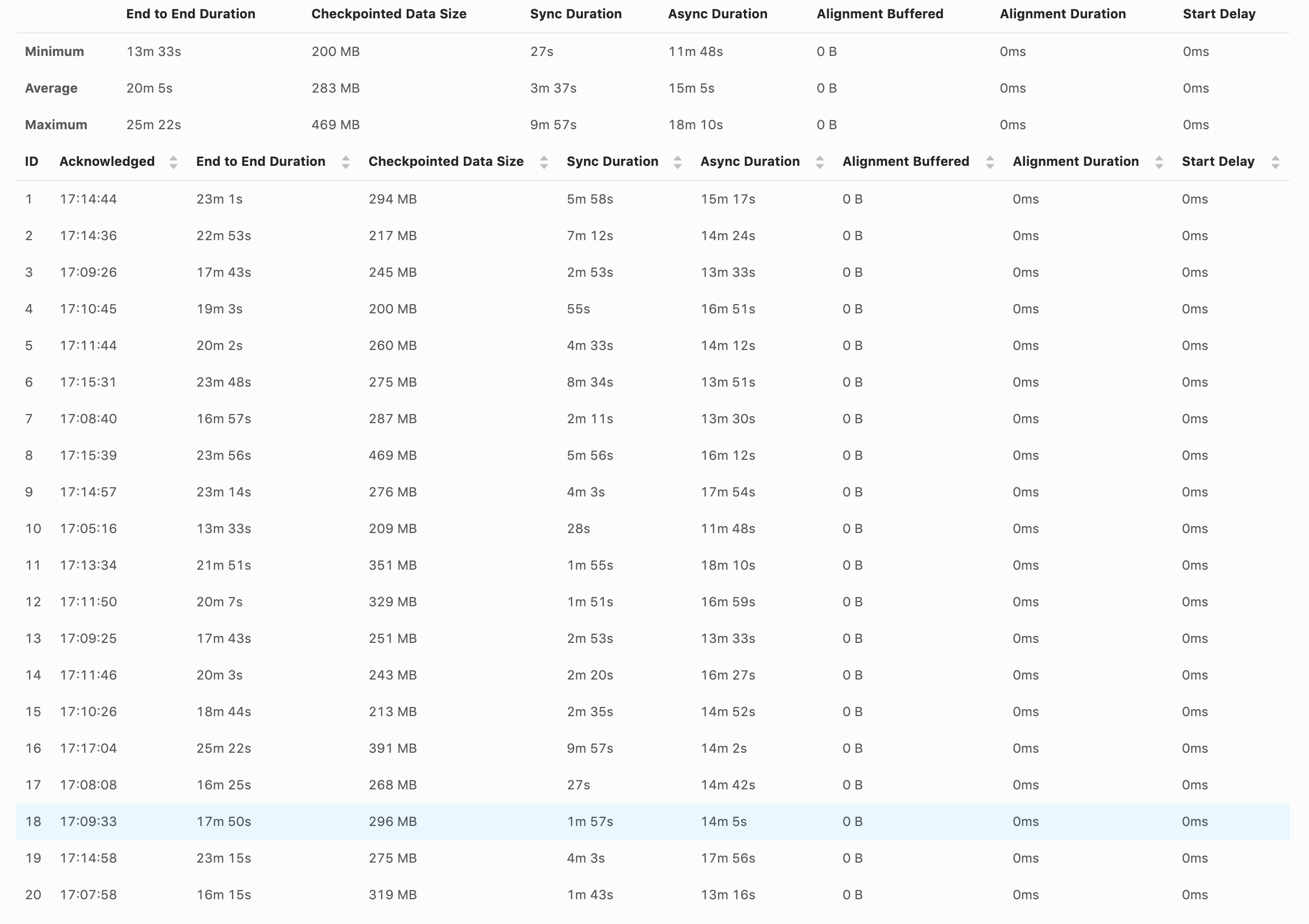
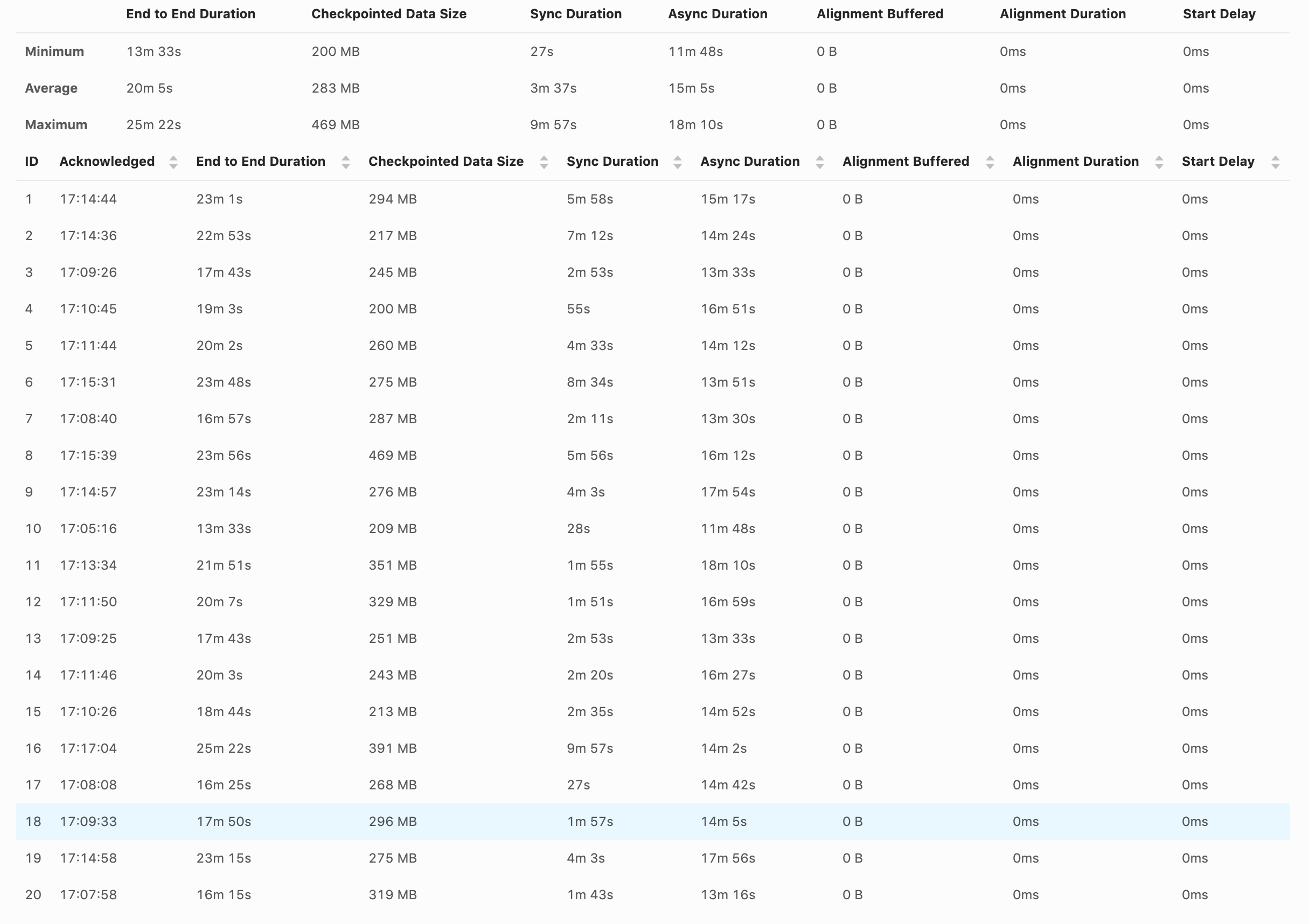
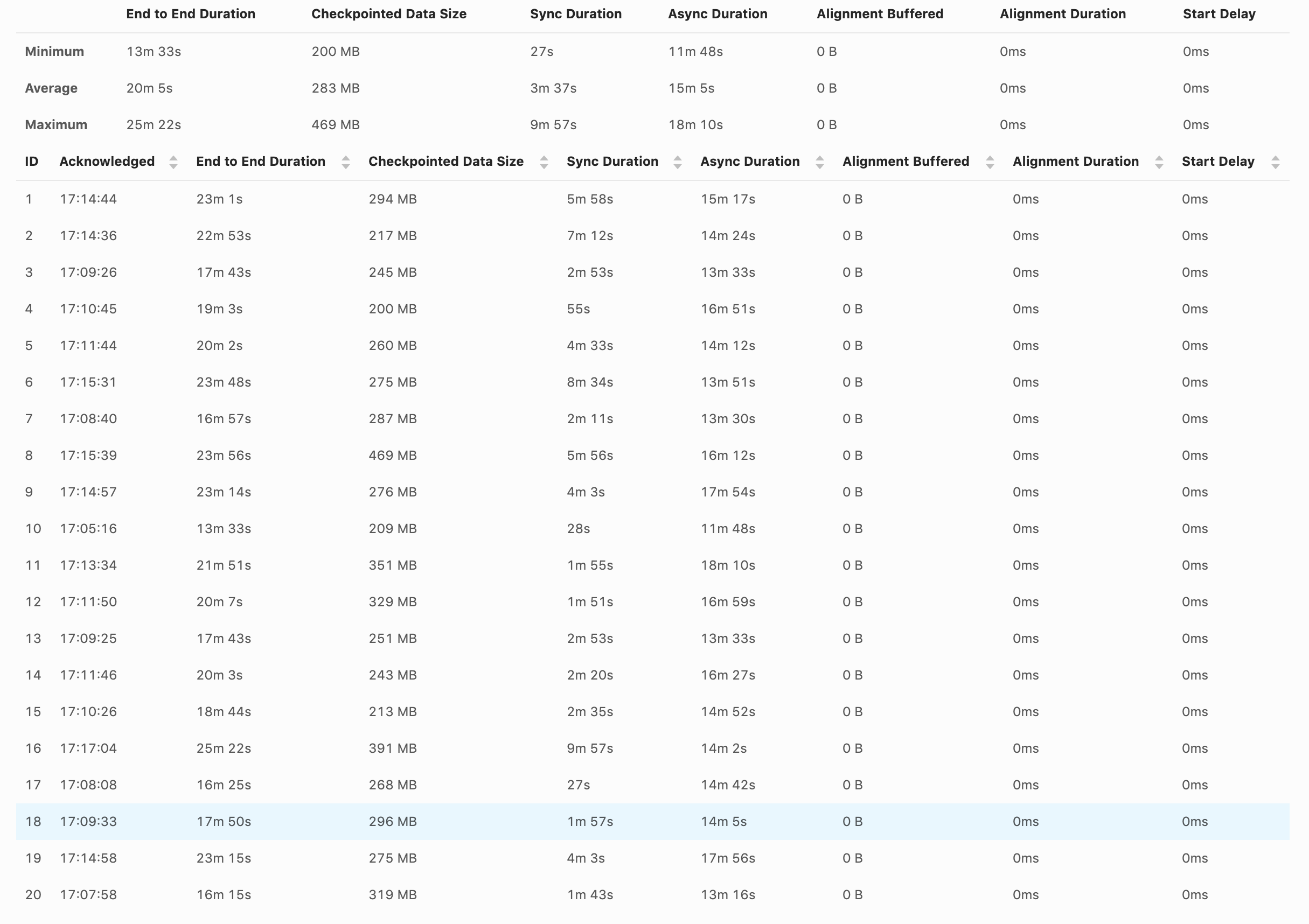
I've enabled unaligned checkpoint, but I'm not sure if it is doing that. When the checkpoint happens, the source and sink stop completely. val cpConfig = env.getCheckpointConfig cpConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) cpConfig.enableUnalignedCheckpoints() cpConfig.setCheckpointTimeout(checkpointTimeout) cpConfig.setMinPauseBetweenCheckpoints(checkpointInterval) cpConfig.setMaxConcurrentCheckpoints(1) cpConfig.setTolerableCheckpointFailureNumber(settings.checkpointsNumberOfFails()) And here are the screenshot from the UI. Shouldn't we have something in UI to indicate if the checkpoints are aligned or not? 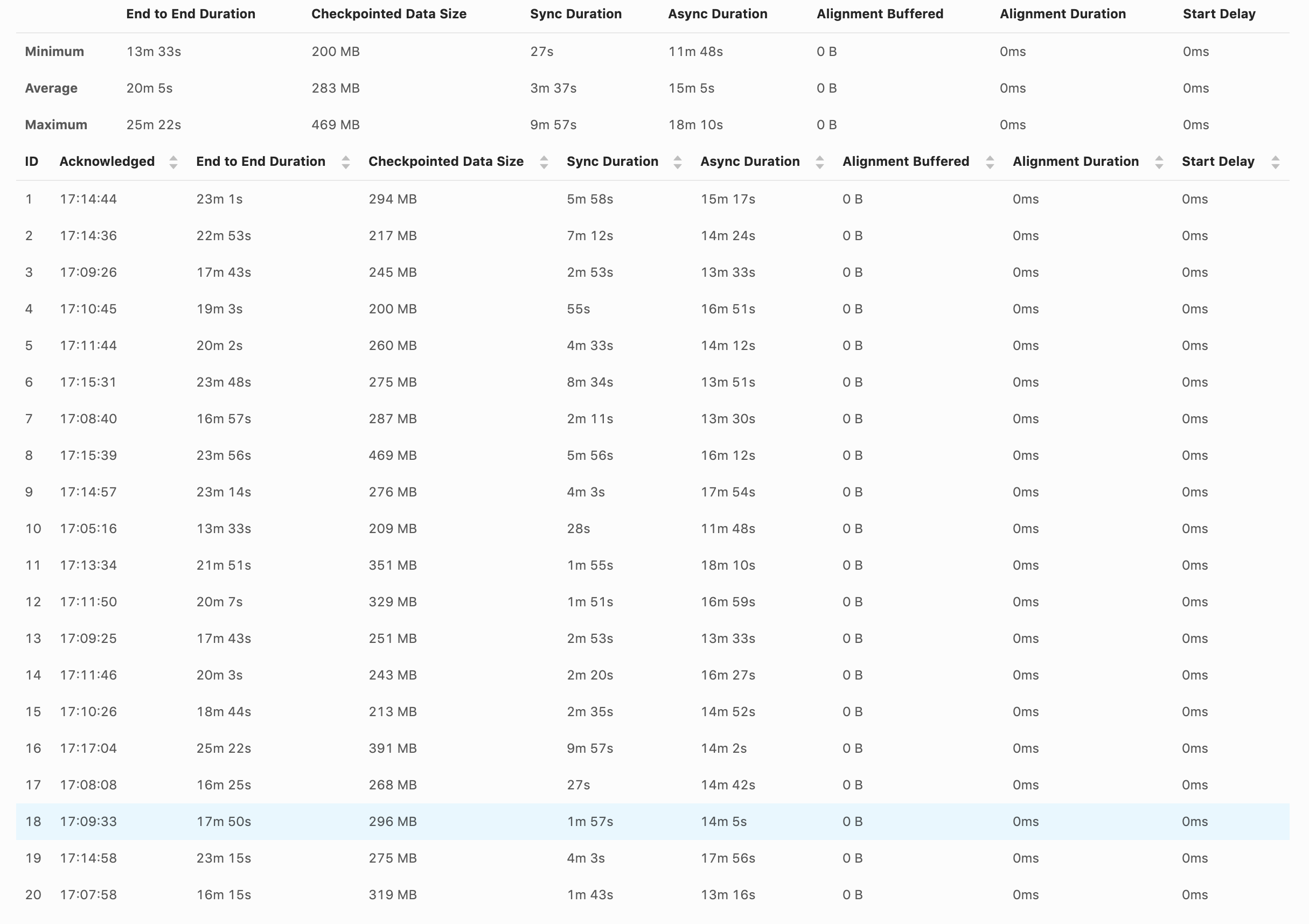 Am I missing something? Thanks, David |
Re: Unaligned Checkpoint not working
|
|
Hi David, could you provide us with the cluster logs? This could help to pinpoint the problem. I am also pulling in Piotr who worked on unaligned checkpoints and might be able to shed some light into the problem. Cheers, Till On Wed, Aug 19, 2020 at 7:02 PM David Magalhães <[hidden email]> wrote:
|
Re: Unaligned Checkpoint not working
|
|
Hi David, I was just writing an answer to you. The logs themselves will probably not be very helpful. Looking at the metrics (long async duration), it looks like you are affected by the problem of increased unaligned checkpoint time due to SourceFunctions blocking execution described by Arvid here [1]. This problem is most prominent in simple job graphs, with very few tasks (for example just a source task followed by a single task with a sink). The more distinct tasks you have in your job, the less noticeable is this problem. Could you post your job graph to confirm this problem? And also can you show checkpoint statistics for all of the tasks in the job? Note that there is one bug [2] in Flink 1.11.0 and 1.11.1 (that will be only fixed in 1.11.2) which causes the start delay metric to be always 0 with enabled unaligned checkpoints. We are also working on providing more metrics to easier understand and detect the above problem [3]. > Shouldn't we have something in UI to indicate if the checkpoints are aligned or not? Yes, we are working on that [4]. Piotrek czw., 20 sie 2020 o 10:19 Till Rohrmann <[hidden email]> napisał(a):
|
Re: Unaligned Checkpoint not working
|
|
Thanks for the replies. The job is quite simple. We read from Kafka (source), keyBy by account_id and aggregate (window) the events by the hour, and then write to S3. env .setStateBackend(backend) .enableCheckpointing(checkpointInterval) .addSource(source) .returns(new GenericRecordAvroTypeInfo(GenericRecordSchema.schema)) .setParallelism(sourceParallelism) .keyBy((record: GenericRecord) => Utils.keyByPartition(record, windowTimeValue)) .timeWindow(windowTime) .trigger(new DelayEventTimeTrigger()) .sideOutputLateData(lateOutputTag) .apply(new GenericRecordAggregatorWindowFunction()) What kind of checkpoints statistics do you want? How much it takes to finish a checkpoint, the checkpoint size? Thanks, David Side question, not sure if I should ask in another topic. I've noticed that the backpressure happing in the source is related to the source/window or window/sink communication and not the writing to S3. Having multiple different KeyBy can impact performance than have fewer? Example: 1500 different KeyBy vs 1 million KeyBy? Or this is just a hash method do balance the events to the available TaskManager? On Thu, Aug 20, 2020 at 10:15 AM Piotr Nowojski <[hidden email]> wrote:
|
Re: Unaligned Checkpoint not working
|
|
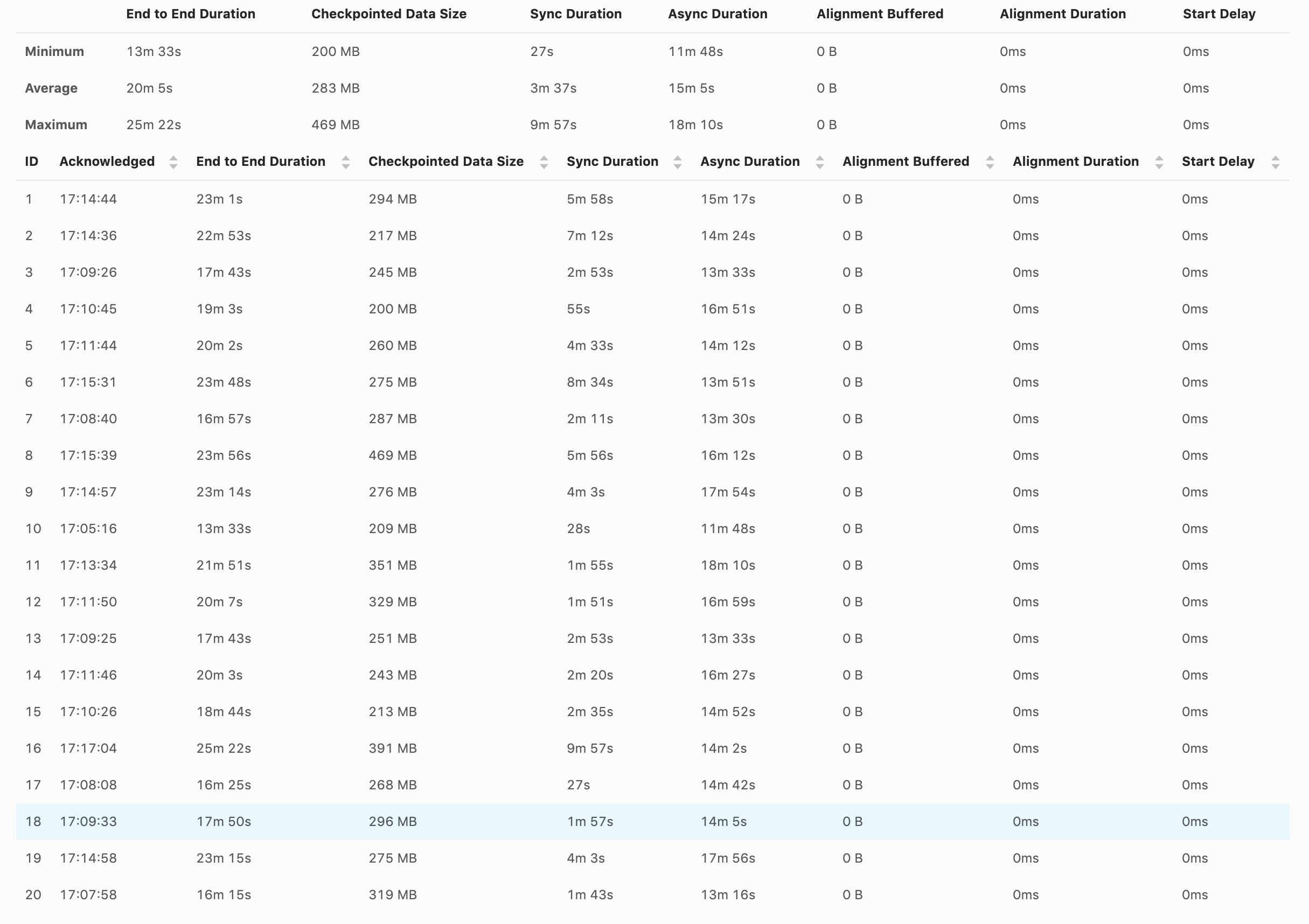
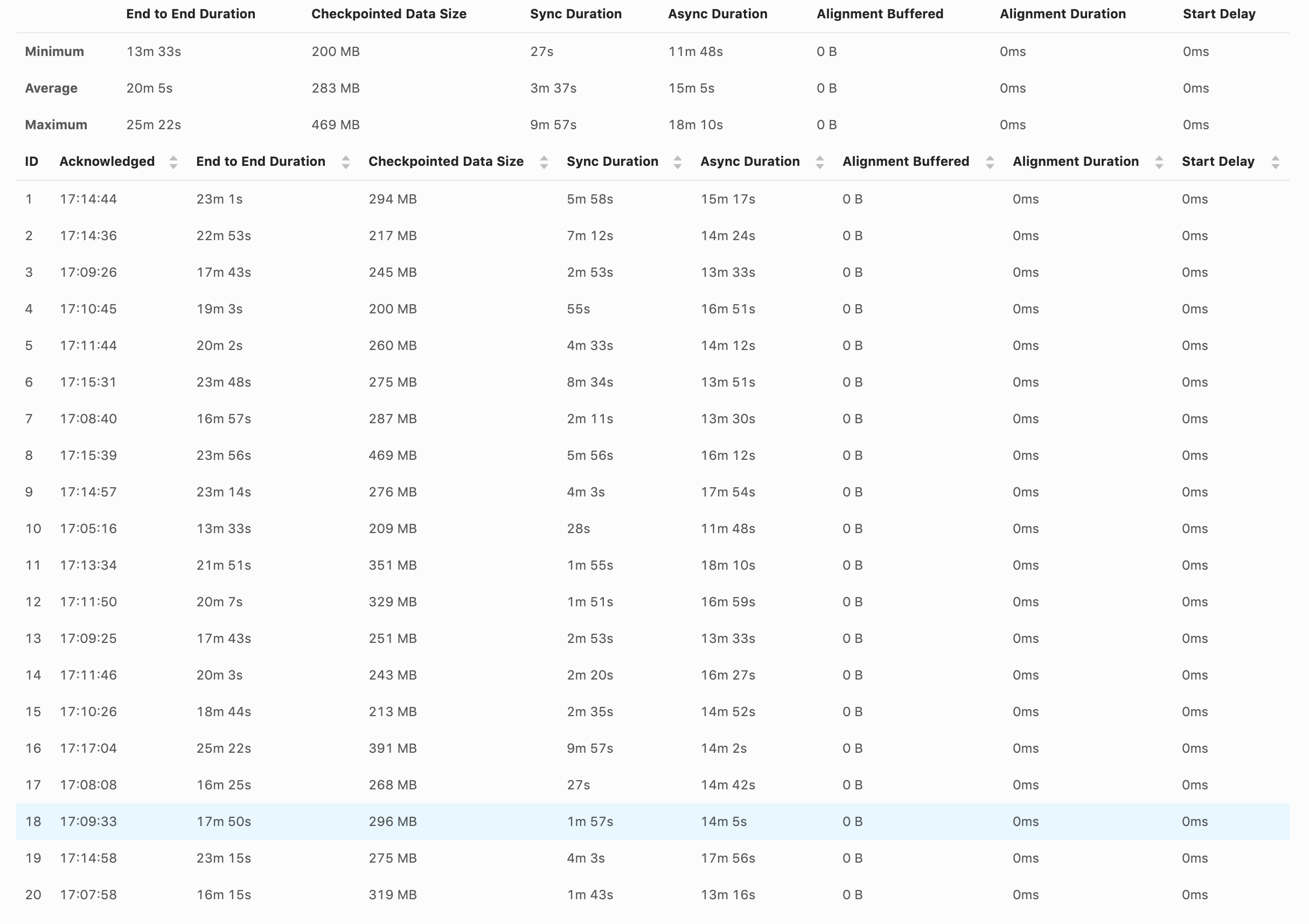
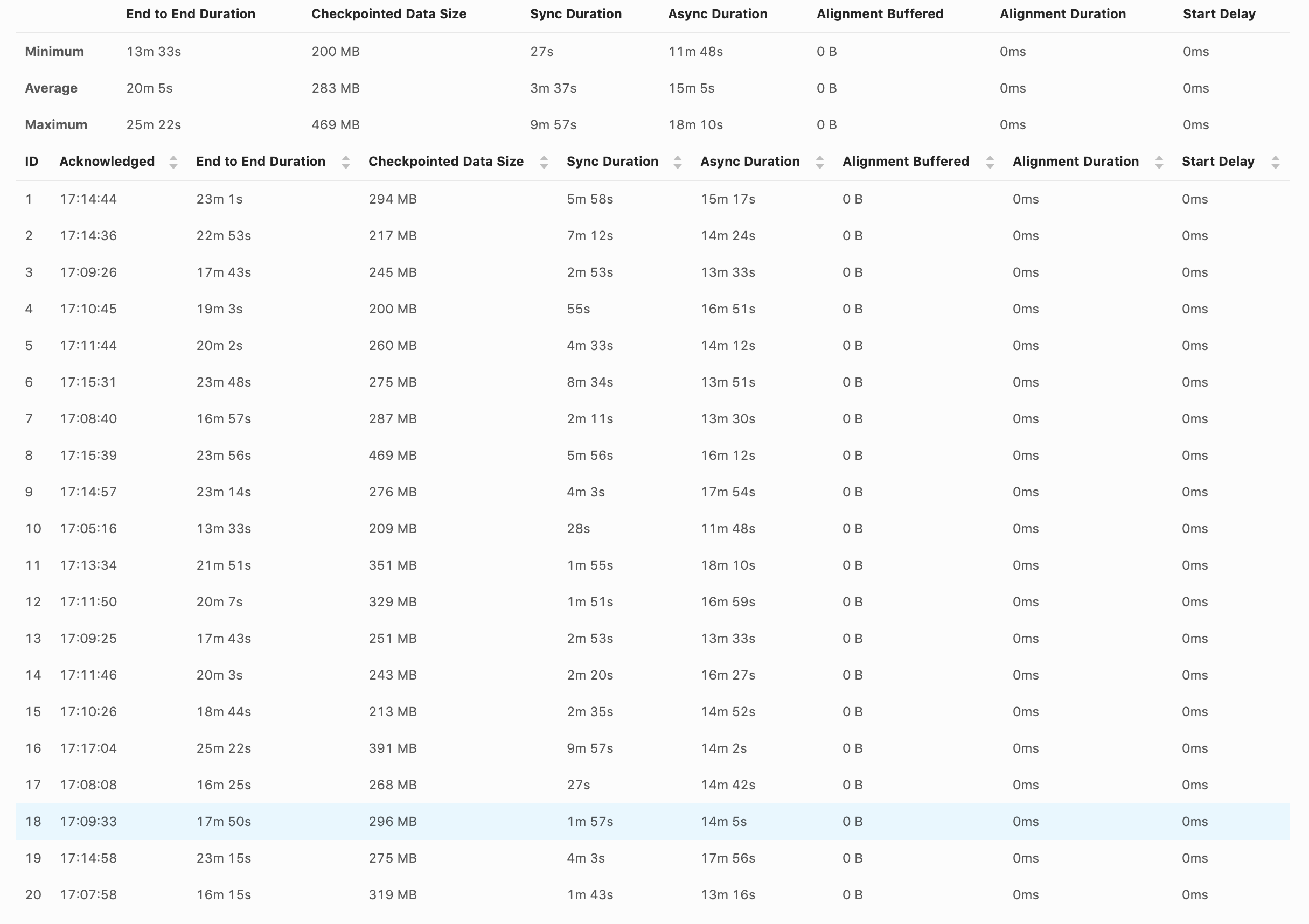
Hi, Can you also elaborate what's the problem that you are observing? > When the checkpoint happens, the source and sink stop completely. Could you explain what it means and how are you testing it? Also how does this behaviour compare to aligned checkpoints? > The job is quite simple. Do you have any sink in your job? It doesn't look like from the code snipped that you posted. But it looks like you have just two tasks in the job - source and aggregation, which is the worst case for the Unaligned Checkpoints for the time being because of the heaviest impact of the blocking behaviour of `SourceFunction` (we are planning to migrate sources to the new non blocking interface in Flink 1.12 to solve this problem). > What kind of checkpoints statistics do you want? How much it takes to finish a checkpoint, the checkpoint size? The similar screen shot from the UI that you posted in the first message, but for both/all of the tasks would be helpful. > I've noticed that the backpressure happing in the source is related to the source/window or window/sink communication and not the writing to S3. What do you mean by "writing to S3"? If you want to analyze backpressure I recommend this blog [1] > Or this is just a hash method do balance the events to the available TaskManager? Yes, the primary purpose of ` keyBy` is to balance records among available parallel instances of downstream operators. Piotrek czw., 20 sie 2020 o 13:12 David Magalhães <[hidden email]> napisał(a):
|
Re: Unaligned Checkpoint not working
|
|
Hi Piotr, Can you also elaborate what's the problem that you are observing? We are getting back pressure in the source and can't consume the volume of events that I need. At first, I thought was the S3 client writing the file as we saw some cases of a long time writing to S3, but remove that code didn't affect the backpressure. Another strange behaviour is the lower watermark don't advance too much. We can have files writes for the lower watermark and other files writes 4 months ahead. This could be due to unbalanced partitions, but I don't think that is the case. Could you explain what it means and how are you testing it? Also how does this behaviour compare to aligned checkpoints? I think the normal behaviour is when a checkpoint is in progress, the reads/writes should stop completely. The idea I thought for the unaligned checkpoint is that each task manager will create their own checkpoint at a different point in time, and the other task manager will continue reading and writing the results. That was the behaviour I was expecting when enabling the unaligned checkpoints. Do you have any sink in your job? It doesn't look like from the code snipped that you posted. But it looks like you have just two tasks in the job - source and aggregation, which is the worst case for the Unaligned Checkpoints for the time being because of the heaviest impact of the blocking behaviour of `SourceFunction` (we are planning to migrate sources to the new non blocking interface in Flink 1.12 to solve this problem). Sorry, we have a sink, it was in another method that creates the full job graph. stream.addSink(sinkFunc).uid(uid) Yes, it is just Source -> Window -> Sink. Thanks for the explanation regarding this use case. The similar screen shot from the UI that you posted in the first message, but for both/all of the tasks would be helpful. The source and the window are the only ones. What do you mean by "writing to S3"? If you want to analyze backpressure I recommend this blog [1] I will check the link. Yes, the primary purpose of ` keyBy` is to balance records among available parallel instances of downstream operators. Thanks, David On Thu, Aug 20, 2020 at 1:02 PM Piotr Nowojski <[hidden email]> wrote:
|
Re: Unaligned Checkpoint not working
|
|
Hi, > I think the normal behaviour is when a checkpoint is in progress, the reads/writes should stop completely. The idea I thought for the unaligned checkpoint is that each task manager will create their own checkpoint at a different point in time, and the other task manager will continue reading and writing the results. That was the behaviour I was expecting when enabling the unaligned checkpoints Unaligned checkpoints doesn't mean that each TM is checkpointing independently. Just that the checkpoint barriers are overtaking the in-flight buffered data, and there is no "alignment phase" - task is not waiting for arrival of all of the checkpoint barriers from all of the input channels before doing the checkpoint. You can check [1] for more details. Also I don't fully understand: > the reads/writes should stop completely. Both in the aligned and unaligned checkpoints reads and writes shouldn't stop during the checkpointing. In both cases tasks should still be processing the data. There might be observed some lower throughput because of higher cluster load while checkpointing (writing checkpoint state), but... > We are getting back pressure in the source and can't consume the volume of events that I need. It doesn't sound like the problem is with unaligned checkpoints or aligned checkpoints, but that your job requires more resources then you can provide and some bottleneck somewhere is causing the backpressure. The purpose of unaligned checkpoints is not to get rid of the back pressure. Back pressure is because your job is not keeping up with the load. Unaligned checkpoints are only a tool to have faster checkpoints (shorter end to end time! it has nothing to do with the job's throughput) when the job is backpressured. If anything, unaligned checkpoints can increase back pressure problems, as they are increasing load on the cluster (larger checkpoint state ===> higher IO load) and lowering the throughput compared to aligned checkpoints. Piotrek czw., 20 sie 2020 o 14:35 David Magalhães <[hidden email]> napisał(a):
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |