***UNCHECKED*** Error while confirming Checkpoint

***UNCHECKED*** Error while confirming Checkpoint

|
This post was updated on .
Hello,
I have a running Flink job that reads data form one Kafka topic, applies some transformations and writes data back into another Kafka topic. The job sometimes restarts due to the following error: /java.lang.RuntimeException: Error while confirming checkpoint at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.IllegalStateException: checkpoint completed, but no transaction pending at org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) at org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) at org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) ... 5 more 2018-09-18 22:00:10,716 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not restart the job ac (3c60b8670c81a629716bb2e42334edea) because the restart strategy prevented it. java.lang.RuntimeException: Error while confirming checkpoint at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.IllegalStateException: checkpoint completed, but no transaction pending at org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) at org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) at org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) ... 5 more/ My state is very small for this particular job, just a few KBs. <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/Screen_Shot_2018-09-19_at_09.png> Flink Version: 1.4.2 State Backend: hadoop 2.8 Regards, Pedro Chaves ----- Best Regards, Pedro Chaves -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/
Best Regards,
Pedro Chaves |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi,
I think the failing precondition is too strict because sometimes a checkpoint can overtake another checkpoint and in that case the commit is already subsumed. I will open a Jira and PR with a fix. Best, Stefan > Am 19.09.2018 um 10:04 schrieb PedroMrChaves <[hidden email]>: > > Hello, > > I have a running Flink job that reads data form one Kafka topic, applies > some transformations and writes data back into another Kafka topic. The job > sometimes restarts due to the following error: > > /java.lang.RuntimeException: Error while confirming checkpoint > at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) > at > java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) > Caused by: java.lang.IllegalStateException: checkpoint completed, but no > transaction pending > at > org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) > at > org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) > at > org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) > at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) > ... 5 more > 2018-09-18 22:00:10,716 INFO > org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not > restart the job Alert_Correlation (3c60b8670c81a629716bb2e42334edea) because > the restart strategy prevented it. > java.lang.RuntimeException: Error while confirming checkpoint > at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) > at > java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at > java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) > at > java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) > at java.lang.Thread.run(Thread.java:748) > Caused by: java.lang.IllegalStateException: checkpoint completed, but no > transaction pending > at > org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) > at > org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) > at > org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) > at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) > ... 5 more/ > > My state is very small for this particular job, just a few KBs. > > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/Screen_Shot_2018-09-19_at_09.png> > > > Flink Version: 1.4.2 > State Backend: hadoop 2.8 > > Regards, > Pedro Chaves > > > > ----- > Best Regards, > Pedro Chaves > -- > Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
FYI, here a link to my PR: https://github.com/apache/flink/pull/6723
> Am 20.09.2018 um 14:52 schrieb Stefan Richter <[hidden email]>: > > Hi, > > I think the failing precondition is too strict because sometimes a checkpoint can overtake another checkpoint and in that case the commit is already subsumed. I will open a Jira and PR with a fix. > > Best, > Stefan > >> Am 19.09.2018 um 10:04 schrieb PedroMrChaves <[hidden email]>: >> >> Hello, >> >> I have a running Flink job that reads data form one Kafka topic, applies >> some transformations and writes data back into another Kafka topic. The job >> sometimes restarts due to the following error: >> >> /java.lang.RuntimeException: Error while confirming checkpoint >> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) >> at >> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) >> at java.util.concurrent.FutureTask.run(FutureTask.java:266) >> at >> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) >> at >> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) >> at java.lang.Thread.run(Thread.java:748) >> Caused by: java.lang.IllegalStateException: checkpoint completed, but no >> transaction pending >> at >> org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) >> at >> org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) >> at >> org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) >> at >> org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) >> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) >> ... 5 more >> 2018-09-18 22:00:10,716 INFO >> org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not >> restart the job Alert_Correlation (3c60b8670c81a629716bb2e42334edea) because >> the restart strategy prevented it. >> java.lang.RuntimeException: Error while confirming checkpoint >> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) >> at >> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) >> at java.util.concurrent.FutureTask.run(FutureTask.java:266) >> at >> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) >> at >> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) >> at java.lang.Thread.run(Thread.java:748) >> Caused by: java.lang.IllegalStateException: checkpoint completed, but no >> transaction pending >> at >> org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) >> at >> org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) >> at >> org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) >> at >> org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) >> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) >> ... 5 more/ >> >> My state is very small for this particular job, just a few KBs. >> >> <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/Screen_Shot_2018-09-19_at_09.png> >> >> >> Flink Version: 1.4.2 >> State Backend: hadoop 2.8 >> >> Regards, >> Pedro Chaves >> >> >> >> ----- >> Best Regards, >> Pedro Chaves >> -- >> Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ > |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi,
could you provide some logs for this problematic job because I would like to double check the reason why this violated precondition did actually happen? Thanks, Stefan > Am 20.09.2018 um 17:24 schrieb Stefan Richter <[hidden email]>: > > FYI, here a link to my PR: https://github.com/apache/flink/pull/6723 > >> Am 20.09.2018 um 14:52 schrieb Stefan Richter <[hidden email]>: >> >> Hi, >> >> I think the failing precondition is too strict because sometimes a checkpoint can overtake another checkpoint and in that case the commit is already subsumed. I will open a Jira and PR with a fix. >> >> Best, >> Stefan >> >>> Am 19.09.2018 um 10:04 schrieb PedroMrChaves <[hidden email]>: >>> >>> Hello, >>> >>> I have a running Flink job that reads data form one Kafka topic, applies >>> some transformations and writes data back into another Kafka topic. The job >>> sometimes restarts due to the following error: >>> >>> /java.lang.RuntimeException: Error while confirming checkpoint >>> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) >>> at >>> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) >>> at java.util.concurrent.FutureTask.run(FutureTask.java:266) >>> at >>> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) >>> at >>> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) >>> at java.lang.Thread.run(Thread.java:748) >>> Caused by: java.lang.IllegalStateException: checkpoint completed, but no >>> transaction pending >>> at >>> org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) >>> at >>> org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) >>> at >>> org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) >>> at >>> org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) >>> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) >>> ... 5 more >>> 2018-09-18 22:00:10,716 INFO >>> org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not >>> restart the job Alert_Correlation (3c60b8670c81a629716bb2e42334edea) because >>> the restart strategy prevented it. >>> java.lang.RuntimeException: Error while confirming checkpoint >>> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1260) >>> at >>> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) >>> at java.util.concurrent.FutureTask.run(FutureTask.java:266) >>> at >>> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) >>> at >>> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) >>> at java.lang.Thread.run(Thread.java:748) >>> Caused by: java.lang.IllegalStateException: checkpoint completed, but no >>> transaction pending >>> at >>> org.apache.flink.util.Preconditions.checkState(Preconditions.java:195) >>> at >>> org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.notifyCheckpointComplete(TwoPhaseCommitSinkFunction.java:258) >>> at >>> org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyOfCompletedCheckpoint(AbstractUdfStreamOperator.java:130) >>> at >>> org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:650) >>> at org.apache.flink.runtime.taskmanager.Task$3.run(Task.java:1255) >>> ... 5 more/ >>> >>> My state is very small for this particular job, just a few KBs. >>> >>> <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/Screen_Shot_2018-09-19_at_09.png> >>> >>> >>> Flink Version: 1.4.2 >>> State Backend: hadoop 2.8 >>> >>> Regards, >>> Pedro Chaves >>> >>> >>> >>> ----- >>> Best Regards, >>> Pedro Chaves >>> -- >>> Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ >> > |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hello Stefan,
Thank you for the help. I've actually lost those logs to due several cluster restarts that we did, which cause log rotation up (limit = 5 versions). Those log lines that i've posted were the only ones that showed signs of some problem. *The configuration of the job is as follows:* / private static final int DEFAULT_MAX_PARALLELISM = 16; private static final int CHECKPOINTING_INTERVAL = 1000; private static final int MIN_PAUSE_BETWEEN_CHECKPOINTS = 1000; private static final int CHECKPOINT_TIMEOUT = 60000; private static final int INTERVAL_BETWEEN_RESTARTS = 120; (...) environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); environment.setMaxParallelism(DEFAULT_MAX_PARALLELISM); environment.enableCheckpointing(CHECKPOINTING_INTERVAL, CheckpointingMode.EXACTLY_ONCE); environment.getCheckpointConfig().setMinPauseBetweenCheckpoints(MIN_PAUSE_BETWEEN_CHECKPOINTS); environment.getCheckpointConfig().setCheckpointTimeout(CHECKPOINT_TIMEOUT); environment.setRestartStrategy(RestartStrategies.noRestart()); environment.setParallelism(parameters.getInt(JOB_PARALLELISM));/ * the kafka consumer/producer configuration is:* / properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.put("max.request.size","1579193"); properties.put("processing.guarantee","exactly_once"); properties.put("isolation.level","read_committed");/ ----- Best Regards, Pedro Chaves -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/
Best Regards,
Pedro Chaves |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi,
I cannot spot anything bad or „wrong“ about your job configuration. Maybe you can try to save and send the logs if it happens again? Did you observe this only once, often, or is it something that is even reproduceable? Best, Stefan > Am 24.09.2018 um 10:15 schrieb PedroMrChaves <[hidden email]>: > > Hello Stefan, > > Thank you for the help. > > I've actually lost those logs to due several cluster restarts that we did, > which cause log rotation up (limit = 5 versions). > Those log lines that i've posted were the only ones that showed signs of > some problem. > > *The configuration of the job is as follows:* > > / private static final int DEFAULT_MAX_PARALLELISM = 16; > private static final int CHECKPOINTING_INTERVAL = 1000; > private static final int MIN_PAUSE_BETWEEN_CHECKPOINTS = 1000; > private static final int CHECKPOINT_TIMEOUT = 60000; > private static final int INTERVAL_BETWEEN_RESTARTS = 120; > (...) > > environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); > environment.setMaxParallelism(DEFAULT_MAX_PARALLELISM); > environment.enableCheckpointing(CHECKPOINTING_INTERVAL, > CheckpointingMode.EXACTLY_ONCE); > > environment.getCheckpointConfig().setMinPauseBetweenCheckpoints(MIN_PAUSE_BETWEEN_CHECKPOINTS); > > environment.getCheckpointConfig().setCheckpointTimeout(CHECKPOINT_TIMEOUT); > environment.setRestartStrategy(RestartStrategies.noRestart()); > environment.setParallelism(parameters.getInt(JOB_PARALLELISM));/ > * > the kafka consumer/producer configuration is:* > / > properties.put("value.deserializer", > "org.apache.kafka.common.serialization.StringDeserializer"); > properties.put("max.request.size","1579193"); > properties.put("processing.guarantee","exactly_once"); > properties.put("isolation.level","read_committed");/ > > > > ----- > Best Regards, > Pedro Chaves > -- > Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hello,
Find attached the jobmanager.log. I've omitted the log lines from other runs, only left the job manager info and the run with the error. jobmanager.log <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/jobmanager.log> Thanks again for your help. Regards, Pedro. ----- Best Regards, Pedro Chaves -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/
Best Regards,
Pedro Chaves |
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi Pedro,
unfortunately the interesting parts are all removed from the log, we already know about the exception itself. In particular, what I would like to see is what checkpoints have been triggered and completed before the exception happens. Best, Stefan > Am 08.10.2018 um 10:23 schrieb PedroMrChaves <[hidden email]>: > > Hello, > > Find attached the jobmanager.log. I've omitted the log lines from other > runs, only left the job manager info and the run with the error. > > jobmanager.log > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/t612/jobmanager.log> > > > > Thanks again for your help. > > Regards, > Pedro. > > > > ----- > Best Regards, > Pedro Chaves > -- > Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
|
|
Hi, I want to raise this question again, since I have had this exception on my production job. The exception is as follows 2019-11-27 14:47:29 java.lang.RuntimeException: Error while confirming checkpoint And these are the checkpoint / savepoint before the job failed. 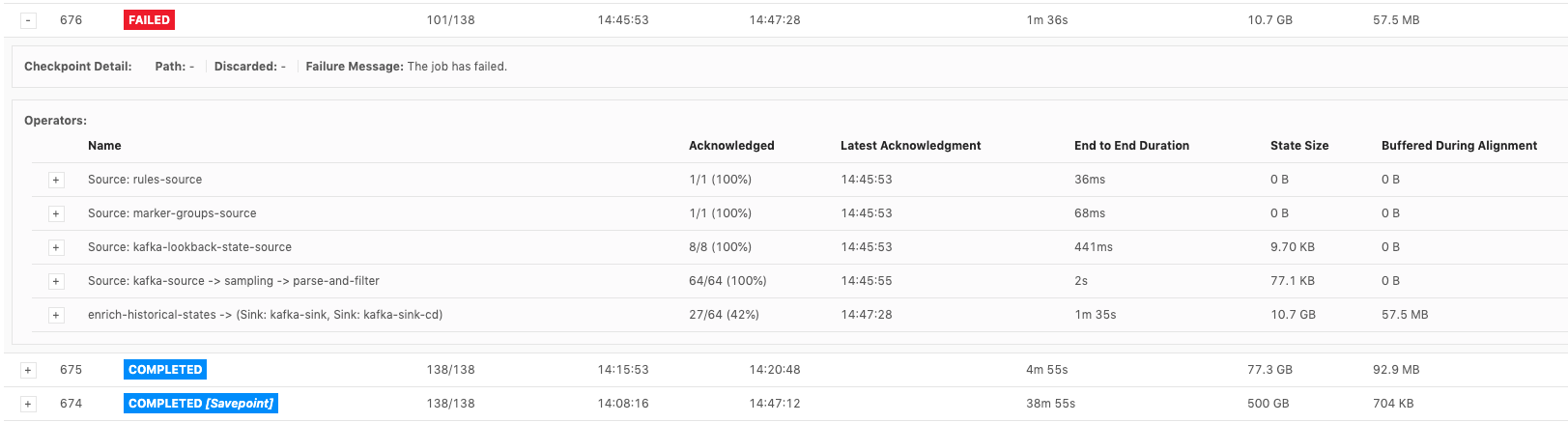 It seems that checkpoint # 675's notification handled the savepoint # 674's pending transaction holder, but savepoint #674's notification didn't be subsumed or be ignored by JM. Therefore, during the checkpoint #676, some tasks got notification before getting the checkpoint barrier and led to this exception happened, because there was no pending transaction in queue. Does anyone know the details about subsumed notifications mechanism and how checkpoint coordinator handle this situation? Please correct me if I'm wrong. Thanks. Best, Tony Wei Stefan Richter <[hidden email]> 於 2018年10月8日 週一 下午5:03寫道: Hi Pedro, |
|
|
Hi, As the follow up, it seem that savepoint can't be subsumed, so that its notification could still be send to each TMs. Is this a bug that need to be fixed in TwoPhaseCommitSinkFunction? Best, Tony Wei Tony Wei <[hidden email]> 於 2019年11月27日 週三 下午3:43寫道:
|
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
This looks to me like the
TwoPhaseCommitSinkFunction is a bit too strict. The notification
for complete checkpoints is not reliable; it may be late, not come
at all, possibly even in different order than expected.
As such, if you a simple case of
snapshot -> snapshot -> notify -> notify the sink will
always fail with an exception.
What it should do imo is either a)
don't check that there is a pending transaction or b) track the
highest checkpoint id received and optionally don't fail if the
notification is for an older CP.
@piotr WDYT?
On 27/11/2019 08:59, Tony Wei wrote:
|
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi,
Maybe Chesney you are right, but I’m not sure. TwoPhaseCommitSink was based on Pravega’s sink for Flink, which was implemented by Stephan, and it has the same logic [1]. If I remember the discussions with Stephan/Till, the way how Flink is using Akka probably guarantees that messages will be always delivered, except of some failure, so `notifyCheckpointComplete` could be missed probably only if a failure happens between snapshot and arrival of the notification. Receiving the same notification twice should be impossible (based on the knowledge passed to me from Till/Stephan). However, for one thing, if that’s possible, then the code should adjusted accordingly. On the other hand, maybe there is no harm in relaxing the contract? Even if we miss this notification (because of some re-ordering?), next one will subsume the missed one and commit everything. Piotrek [1] https://github.com/pravega/flink-connectors/blob/master/src/main/java/io/pravega/connectors/flink/FlinkPravegaWriter.java#L567
|
|
|
Hi Piotrek, The case here was that the first snapshot is a savepoint. I know that if the following checkpoint succeeded before the previous one, the previous one will be subsumed by JobManager. However, if that previous one is a savepoint, it won't be subsumed. That leads to the case that Chesney said. The following checkpoint succeeded before the previous savepoint, handling both of their pending transaction, but savepoint still succeeded and sent the notification to each TaskManager. That led to this exception. Could you double check if this is the case? Thank you. Best, Tony Wei Piotr Nowojski <[hidden email]> 於 2019年11月27日 週三 下午8:50 寫道:
|
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Hi Tony,
Thanks for the explanation. Assuming that’s what’s happening, then I agree, this checkStyle should be removed. I created a ticket for this issue Piotrek
|
|
|
Hi Piotrek, There was already an issue [1] and PR for this thread. Should we mark it as duplicated or related issue? Best, Tony Wei Piotr Nowojski <[hidden email]> 於 2019年11月28日 週四 上午12:17寫道:
|
Re: ***UNCHECKED*** Error while confirming Checkpoint
|
|
Thank you all for investigation/reporting/discussion. I have merged an older PR [1] that was fixing this issue which was previously rejected as we didn’t realise this is a production issue.
I have merged it and issue should be fixed in Flink 1.10, 1.9.2 and 1.8.3 releases. Piotrek [1] https://github.com/apache/flink/pull/6723
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |