Tumbling Windows with Processing Time


|
Hi Flink users, I have a question about Tumbling Windows using Processing Time at Flink ver 0.10.1 :In fact, I want to measure the throughput of my application, the idea is at the last operator, by using a Tumbling processing Time windows with a size of 1 second, I count the message received. val env = StreamExecutionEnvironment.getExecutionEnvironmentval parallelism = 4
|
Re: Tumbling Windows with Processing Time
|
|
The definition looks correct. Because the windows are by-key, you should get one window result per key per second. Can you turn off object-reuse? That is a pretty experimental thing and works with the batch operations quite well, but not so much with the streaming windows, yet. I would only enable object reuse after the program works well and correctly without. Greetings, Stephan On Tue, Feb 2, 2016 at 7:31 PM, yutao sun <[hidden email]> wrote:
|
|
|
Thanks for your help, I retest by disable the object reuse and got the same result (please see the picture attached). 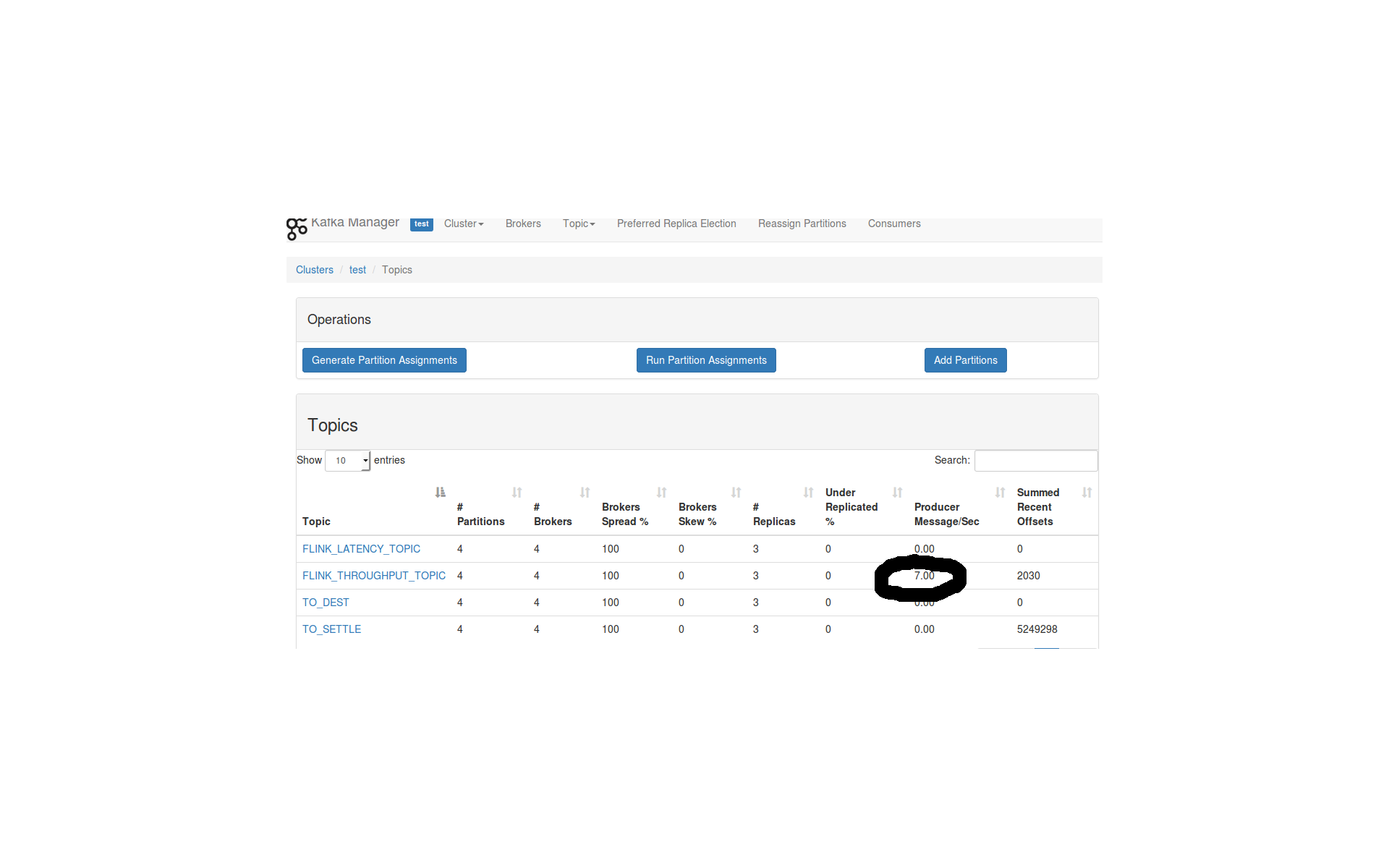 2016-02-03 10:51 GMT+01:00 Stephan Ewen <[hidden email]>:
|
Re: Tumbling Windows with Processing Time
|
|
Do you have 7 distinct keys? You get as many result tuples as you have keys, because the window is per key. On Wed, Feb 3, 2016 at 12:12 PM, yutao sun <[hidden email]> wrote:
|

Re: Tumbling Windows with Processing Time
|
|
In reply to this post by yutao sun
There should be 4 windows because there are only 4 distinct keys, if I understand this line correctly:
.keyBy(mappedPayload => mappedPayload._1.id.hashcode % parallelism) > On 02 Feb 2016, at 19:31, yutao sun <[hidden email]> wrote: > > .keyBy(mappedPayload => mappedPayload._1.id.hashcode % parallelism) |
Re: Tumbling Windows with Processing Time
|
|
How long did you run the job? Could it be an artifact of the timing and it hasn’t yet averaged out.
> On 03 Feb 2016, at 14:32, Aljoscha Krettek <[hidden email]> wrote: > > There should be 4 windows because there are only 4 distinct keys, if I understand this line correctly: > > .keyBy(mappedPayload => mappedPayload._1.id.hashcode % parallelism) > >> On 02 Feb 2016, at 19:31, yutao sun <[hidden email]> wrote: >> >> .keyBy(mappedPayload => mappedPayload._1.id.hashcode % parallelism) > |
|
|
Exactly, I have more than 4 keys because the "nenative modulo", after thange this line from .keyBy(mappedPayload => mappedPayload._1.id.hashcode % parallelism)to.keyBy(mappedPayload => Math.abs(mappedPayload._1.id.hashcode % parallelism))or just profit Flink's dataStream.partitionByHash(Field)Thanks for your help! Cheers :)2016-02-03 14:35 GMT+01:00 Aljoscha Krettek <[hidden email]>: How long did you run the job? Could it be an artifact of the timing and it hasn’t yet averaged out. |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |