TimerService/Watermarks and Checkpoints

TimerService/Watermarks and Checkpoints

|
Hi,
Is it possible the watermark in TimerService not getting reset when a job is restarted from a previous checkpoint? I would expect the watermark in a TimerService also to go back in time. I have the following ProcessFunction implementation. override def processElement( e: TraceEvent, ctx: ProcessFunction[ TraceEvent, Trace ]#Context, out: Collector[Trace] ): Unit = { if (e.getAnnotationTime() < ctx.timerService(). registry.counter("tracing. } else { .... } I am noticing the outOfOrderEvents are reported until new events are read in to the stream since the last restart. Regards, Nara |
|
|
Hi Nara, yes, the watermark in TimerService is not covered by the checkpoint, everytime the job is restarted from a previous checkpoint, it is reset to Long.MIN_VALUE. I can see it a bit tricky to cover it into the checkpoint, especially when we need to support rescaling(it seems not like a purely keyed or a operate state), maybe @Stefan or @Aljoscha could give you more useful information about why it wasn't covered by the checkpoint. Best, Sihua
On 05/30/2018 05:44,[hidden email] wrote:
|
Re: TimerService/Watermarks and Checkpoints
|
|
Thanks Sihua. If it's reset to Long.MIN_VALUE I can't explain why outOfOrderEvents are reported. Because the event time on the data will always be greater than Long.MIN_VALUE. Following are the steps to reproduce this scenario. - A source to produce events with timestamps that is increasing for every event produced - Use TimeCharacteristic.EventTime - Use BoundedOutOfOrdernessTimestampExtractor with maxOutOfOrderness set to 60s. - Enable checkpoints - ProcessFunction impl to report a counter to some metrics backend when the timestamp of the event is less than currentWatermark- No out of order events will be reported initially. After few checkpoints are created, cancel and restart the job from a previous checkpoint. Note: The event stream really doesn't have out of order data. Job restart from a checkpoint causes this artificial out of order events because of the watermark value. Regards, Nara On Tue, May 29, 2018 at 7:54 PM, sihua zhou <[hidden email]> wrote:
|
Re: TimerService/Watermarks and Checkpoints
|
|
Hi Nara and Sihua, That's indeed an unexpected behavior and it would be good to identify the reason for the late data.As Sihua said, watermarks are currently not checkpointed and reset to Long.MIN_VALUE upon restart. 2018-05-30 19:00 GMT+02:00 Narayanan Arunachalam <[hidden email]>:
|
Re: TimerService/Watermarks and Checkpoints
|
|
Thanks for the explanation. I looked at this metric closely and noticed there are some events arriving in out of order. The hypothesis I have is, when the job is restarted, all of the small out of order chunks add up and show a significant number. The graph below shows the number of out of order events every min. The job was started with new state at 11:53 am and then restarted with the previous checkpoint at 1:24 pm. That said, after restart the out of order events number is very high though :thinking_face: 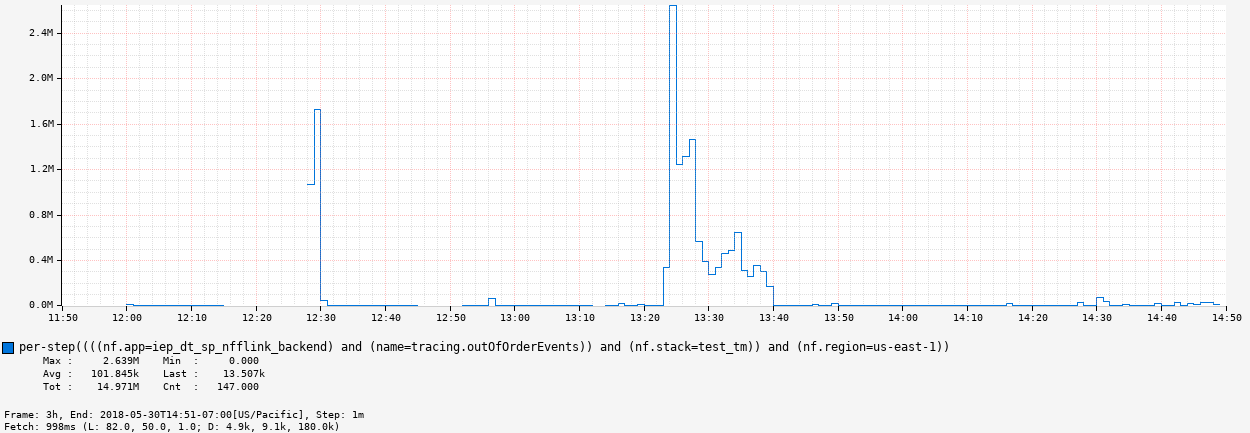 On Wed, May 30, 2018 at 1:55 PM, Fabian Hueske <[hidden email]> wrote:
|
Re: TimerService/Watermarks and Checkpoints
|
|
One explanation would be that during catch up, data is consumer with higher throughput because its just read from Kafka. Hence, you'd see also more late data per minute while the job catches up until it reads data at the rate at which it is produced into Kafka.2018-05-30 23:56 GMT+02:00 Narayanan Arunachalam <[hidden email]>:
|
Re: TimerService/Watermarks and Checkpoints
|
|
Yeah that's my observation too. Basically small chunks of late data can get added up quickly when data is read at a faster rate. On a related note, I would expect if there is no late data produced in Kafka, then immaterial of what rate the data is read, this problem should not occur. To take care of processing the late data, I am now leveraging the watermark time as the baseline to setup the timers in the process function as opposed to using the time on the event itself. That way, the timer will fire with respect to the progress of the watermark. Otherwise, when time on the event is used as baseline, the timer will fire right away for late data. Because the watermark will be moved ahead already. Here is an example code from a ProcessFunction impl: private def registerTimers( ctx: ProcessFunction[TraceEvent, Trace]#Context ) = { val timer = ctx.timerService() timer.registerEventTimeTimer( timer.currentWatermark() + timeoutMs // using this ^^ instead of traceEvent.getTimestamp() + timeoutMs ) } This approach of using watermark as baseline for the Timer also keeps the state size small. Otherwise, the state is not cleared until the watermark crosses traceEvent.getTimestamp() + timeoutMs. Regards, Nara On Fri, Jun 1, 2018 at 12:22 AM, Fabian Hueske <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |