TeraSort on Flink and Spark


|
Hello,
I'd like to share my code for TeraSort on Flink and Spark which uses the same range partitioner as Hadoop TeraSort: https://github.com/eastcirclek/terasort I also write a short report on it: http://eastcirclek.blogspot.kr/2015/06/terasort-for-spark-and-flink-with-range.html In the blog post, I make a simple performance comparison between Flink, Spark, Tez, and MapReduce. I hope it will be helpful to you guys! Thanks. Dongwon Kim Postdoctoral Researcher @ Postech |
|
|
Hello Dongwon Kim! Thanks you for sharing these numbers with us. I have gone through your implementation and there are two things you could try: 1) I see that you sort Hadoop's Text data type with Flink. I think this may be less efficient than if you sort String, or a Flink specific data type. For efficient byte operations on managed memory, Flink needs to understand the binary representation of the data type. Flink understands that for "String" and many other types, but not for "Text". There are two things you can do: - First, try what happens if you map the Hadoop Text type to a Java String (only for the tera key). - Second, you can try what happens if you wrap the Hadoop Text type in a Flink type that supports optimized binary sorting. I have pasted code for that at the bottom of this email. 2) You can see if it helps performance if you enable object re-use in Flink. You can do this on the ExecutionEnvironment via "env.getConfig().enableObjectReuse()". Then Flink tries to use the same objects repeatedly, in case they are mutable. Can you try these options out and see how they affect Flink's runtime? Greetings, Stephan --------------------------------------------------------- Code for optimized sortable (Java): public final class OptimizedText implements NormalizableKey<OptimizedText > { private final Text text; public OptimizedText () { this.text = new Text(); } public OptimizedText (Text from) { this.text = from; } public Text getText() { return text; } @Override public int getMaxNormalizedKeyLen() { return 10; } @Override public void copyNormalizedKey(MemorySegment memory, int offset, int len) { memory.put(offset, text.getBytes(), 0, Math.min(text.getLength(), Math.min(10, len))); } @Override public void write(DataOutputView out) throws IOException { text.write(out); } @Override public void read(DataInputView in) throws IOException { text.readFields(in); } @Override public int compareTo(OptimizedText o) { return this.text.compareTo(o.text); } } --------------------------------------------------------- Converting Text to OptimizedText (Java code) map(new MapFunction<Tuple2<Text, Text>, Tuple2<OptimizedText, Text>>() { @Override public Tuple2<OptimizedText, Text> map(Tuple2<Text, Text> value) { return new Tuple2<OptimizedText, Text>(new OptimizedText(value.f0), value.f1); } }) On Thu, Jul 2, 2015 at 6:47 PM, Dongwon Kim <[hidden email]> wrote: Hello, |
Re: TeraSort on Flink and Spark
|
|
Hi Stephan, On 2 Jul 2015 20:29, "Stephan Ewen" <[hidden email]> wrote:
|
|
|
Flavio, In general, String works well in Flink, because it behaves for sorting much like this OptimizedText. If you want to access the String contents, then using String is good. Text may have slight advantages if you never access the actual contents, but just partition and sort it (as in TeraSort). The key length is limited to 10, because in TeraSort, the keys are defined to be 10 characters long ;-) Greetings, Stephan On Thu, Jul 2, 2015 at 9:14 PM, Flavio Pompermaier <[hidden email]> wrote:
|
|
|
In reply to this post by Dongwon Kim
Hi Stephan,
I just pushed changes to my github: https://github.com/eastcirclek/terasort. I've modified the TeraSort program so that (A) it can reuse objects and (B) it can exploit OptimizedText as you suggested. I've also conducted few experiments and the results are as follows: ORIGINAL : 1714 ORIGINAL+A : 1671 ORIGINAL+B : 1467 ORIGINAL+A+B : 1427 Your advice works as shown above :-) Datasets are now defined as below: - val inputFile = env.readHadoopFile(teraInputFormat, classOf[Text], classOf[Text], inputPath) - val optimizedText = inputFile.map(tp => (new OptimizedText(tp._1), tp._2)) - val sortedPartitioned = optimizedText.partitionCustom(partitioner, 0).sortPartition(0, Order.ASCENDING) - sortedPartitioned.map(tp => (tp._1.getText, tp._2)).output(hadoopOF) You can see the two map transformations before and after the function composition partitionCustom.sortPartition. Here is a question regarding the performance improvement. Please see the attached Ganglia image files. - ORIGINAL-[cpu, disks, network].png are for ORIGINAL. - BEST-[cpu, disks, network].png are for ORIGINAL+A+B. Compared to ORIGINAL, BEST shows better utilization of disks and network and shows lower CPU utilization. Is this because OptimizedText objects are serialized into Flink memory layout? What happens when keys are represented in just Text, not OptimziedText? Are there another memory area to hold such objects? or are they serialized anyway but in an inefficient way? If latter, is the CPU utilization in ORIGINAL high because CPUs work hard to serialize Text objects using Java serialization mechanism with DataInput and DataOutput? If true, I can explain the high throughput of network and disks in ORIGINAL+A+B. I, however, observed the similar performance when I do mapping not only on 10-byte keys but also on 90-byte values, which cannot be explained by the above conjecture. Could you make things clear? If so, I would be very appreciated ;-) I'm also wondering whether the two map transformations, (Text, Text) to (OptimizedText, Text) and (OptimizedText, Text) to (Text, Text), can prevent Flink from performing a lot better. I don't have time to modify TeraInputFormat and TeraOutputFormat to read (String, String) pairs from HDFS and write (String, String) pairs to HDFS. Do you see that one can get a better TeraSort result using an new implementation of FileInputFormat<String,String>? Regards, Dongwon Kim 2015-07-03 3:29 GMT+09:00 Stephan Ewen <[hidden email]>: > Hello Dongwon Kim! > > Thanks you for sharing these numbers with us. > > I have gone through your implementation and there are two things you could > try: > > 1) > > I see that you sort Hadoop's Text data type with Flink. I think this may be > less efficient than if you sort String, or a Flink specific data type. > > For efficient byte operations on managed memory, Flink needs to understand > the binary representation of the data type. Flink understands that for > "String" and many other types, but not for "Text". > > There are two things you can do: > - First, try what happens if you map the Hadoop Text type to a Java String > (only for the tera key). > - Second, you can try what happens if you wrap the Hadoop Text type in a > Flink type that supports optimized binary sorting. I have pasted code for > that at the bottom of this email. > > 2) > > You can see if it helps performance if you enable object re-use in Flink. > You can do this on the ExecutionEnvironment via > "env.getConfig().enableObjectReuse()". Then Flink tries to use the same > objects repeatedly, in case they are mutable. > > > Can you try these options out and see how they affect Flink's runtime? > > > Greetings, > Stephan > > --------------------------------------------------------- > Code for optimized sortable (Java): > > public final class OptimizedText implements NormalizableKey<OptimizedText > > { > private final Text text; > public OptimizedText () { > this.text = new Text(); > } > public OptimizedText (Text from) { > this.text = from; > } > > public Text getText() { > return text; > } > > @Override > public int getMaxNormalizedKeyLen() { > return 10; > } > > @Override > public void copyNormalizedKey(MemorySegment memory, int offset, int len) { > memory.put(offset, text.getBytes(), 0, Math.min(text.getLength(), > Math.min(10, len))); > } > > @Override > public void write(DataOutputView out) throws IOException { > text.write(out); > } > > @Override > public void read(DataInputView in) throws IOException { > text.readFields(in); > } > > @Override > public int compareTo(OptimizedText o) { > return this.text.compareTo(o.text); > } > } > > --------------------------------------------------------- > Converting Text to OptimizedText (Java code) > > map(new MapFunction<Tuple2<Text, Text>, Tuple2<OptimizedText, Text>>() { > @Override > public Tuple2<OptimizedText, Text> map(Tuple2<Text, Text> value) { > return new Tuple2<OptimizedText, Text>(new OptimizedText(value.f0), > value.f1); > } > }) > > > > > On Thu, Jul 2, 2015 at 6:47 PM, Dongwon Kim <[hidden email]> > wrote: >> >> Hello, >> >> I'd like to share my code for TeraSort on Flink and Spark which uses >> the same range partitioner as Hadoop TeraSort: >> https://github.com/eastcirclek/terasort >> >> I also write a short report on it: >> >> http://eastcirclek.blogspot.kr/2015/06/terasort-for-spark-and-flink-with-range.html >> In the blog post, I make a simple performance comparison between >> Flink, Spark, Tez, and MapReduce. >> >> I hope it will be helpful to you guys! >> Thanks. >> >> Dongwon Kim >> Postdoctoral Researcher @ Postech > > |
Re: TeraSort on Flink and Spark
|
|
Hi Dongwon Kim, this blog post describes Flink's memory management, serialization, and sort algorithm and also includes performance numbers of some microbenchmarks.--> http://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-Bytes.html The lower CPU utilization can be explained by less deserialization + garbage collection. Since the CPU is less utilized, the network and disk utilization increases. 2015-07-10 9:35 GMT+02:00 Dongwon Kim <[hidden email]>: Hi Stephan, |
|
|
In reply to this post by Dongwon Kim
Hi Dongwon Kim! Thank you for trying out these changes. The OptimizedText can be sorted more efficiently, because it generates a binary key prefix. That way, the sorting needs to serialize/deserialize less and saves on CPU. In parts of the program, the CPU is then less of a bottleneck and the disks and the network can unfold their bandwidth better. Greetings, Stephan On Fri, Jul 10, 2015 at 9:35 AM, Dongwon Kim <[hidden email]> wrote: Hi Stephan, |
|
|
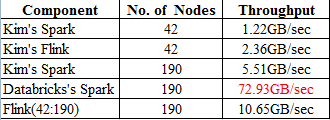
Hi Kim and Stephan Kim's report is sorting 3360GB per 1427 seconds by Flink 0.9.0. 3360 = 80*42 ((80GB/per node and 42 nodes) Based on Kim's report. The TPS is 2.35GB/sec for Flink 0.9.0 Kim was using 42 nodes for testing purposes. I found that the best Spark performance result was using 190 nodes from Databricks The scalability factor is 42:190. if we are going to use 190 nodes for this testing. The Flink TPS should be 10.65GB /sec Here is the summary table for your reference. Please let me know if you have any questions about this table. Thanks. 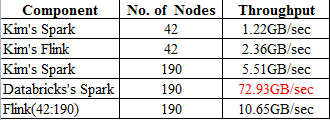 72.93GB/sec = (1000TB*1024) / (234min*60) The performance test report from Databricks. Best regards Hawin On Fri, Jul 10, 2015 at 1:33 AM, Stephan Ewen <[hidden email]> wrote:
|
|
|
Hi Jiang,
Please refer to http://sortbenchmark.org/. When you take a look at the specification of each node Spark team uses, you can easily realize that # of nodes is not the only thing to take into consideration. You miss important things to consider for a fair comparison. (1) # of disks in each node and disk type - Spark team has 8 SDD's in each node while we have 6 HDDs in each node. - If a SSD which Spark team uses can read data 500MB/sec, 8 SSD's can read 4000MB/sec. - If a HDD which I use can read data 100MB/sec, 6 HDD's can read 600MB/sec. - Here Spark team has 6.6x throughput. - Additionally, SSD's can read/write much better than HDDs with random disk access pattern. (2) the size of memory in each node - They have 244GB in each node while we have 24GB in each node. - The Spark team processes 494.7GB per node (100TB/207nodes) which is around 2x than 244GB (memory in each node). - As you know, I did sorting on 80GB per node which is around 3.5x than 24GB (memory in each node). (Actually I only use 12GB of memory in each node, so I process 7x data than used memory in each node.) - As you can see the following link, Spark gets slower when it processes more data than its memory: 35 page in http://www.slideshare.net/KostasTzoumas/apache-flink-api-runtime-and-project-roadmap. (3) # of CPU cores : they have 32 cores in each node while we have 16 cores in each node. The throughput you mentioned cannot be explained in that simple way. Regards, Dongwon Kim Postdoctoral Researcher @ Postech 2015-07-13 8:00 GMT+09:00 Hawin Jiang <[hidden email]>:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |