Task slot sharing: force reallocation

Task slot sharing: force reallocation

|
Hello! I'm trying to find out if there a way to force task slot sharing within a job. The example on the website looks like the following (as in the screenshot) 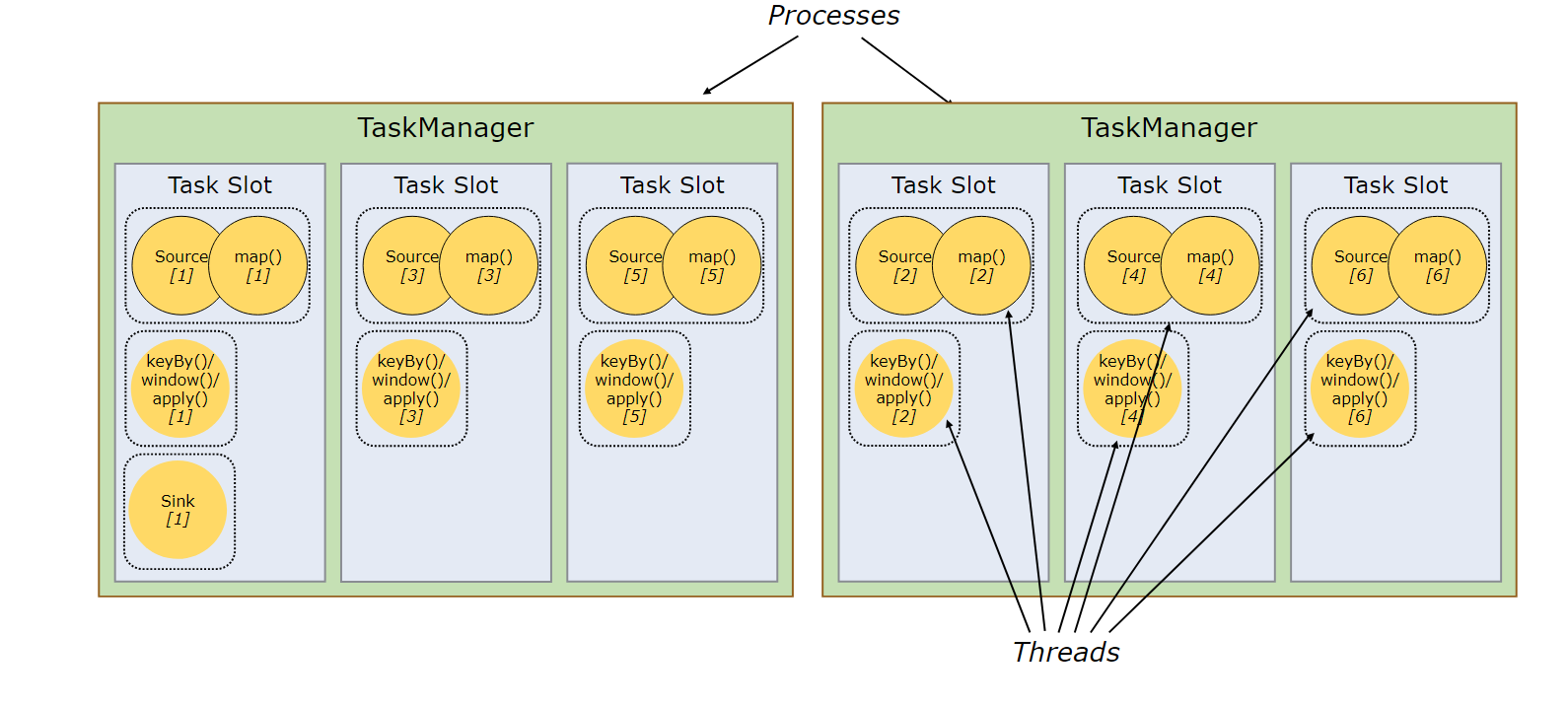 In this example, the single sink is slot-sharing with source/map (1) and window operator (1). If I deploy multiple identical jobs shown above, all sink operators would be placed on the first machine (which creates an unbalanced scenario). Is there a way to avoid this situation (i.e., to have sink operators of different jobs spread evenly across the task slots for the entire cluster). Specifically, I was wondering if either of the following options are possible: 1. To force Sink[1] to be slot sharing with mapper from a different partition on other slots such as (source[2] and window[2]). 2. If option 1 is not possible, is there a "hacky" way for Flink to deploy jobs starting from a different machine: e.g. For job 2, it can allocate source/map[1], window[1], sink[1] to machine 2 instead of again on machine 1. In this way the slot-sharing groups are still the same, but we end up having sinks from the two jobs on different machines. Thanks! |
Re: Task slot sharing: force reallocation
|
|
Hi,
Are you asking the question if that’s the behaviour or you have actually observed this issue? I’m not entirely sure, but I would guess that the Sink tasks would be distributed randomly across the cluster, but maybe I’m mixing this issue with resource allocations for Task Managers. Maybe Till will know something more about this? One thing that might have solve/workaround the issue is to run those jobs in the job mode (one cluster per job), not in cluster mode, since containers for Task Managers are created/requested randomly. Piotrek
|
Re: Task slot sharing: force reallocation
|
|
Thanks Piotr. I didn't realize that the email attachment isn't working so the example I was referring to was this figure from Flink website: https://ci.apache.org/projects/flink/flink-docs-stable/fig/slot_sharing.svg So I try to run multiple jobs concurrently in a cluster -- the jobs are identical and the DAG looks very similar to the one in the figure. Each machine holds one map task from each job. I end up with X number of sinks on machine 1 (X being the number of jobs). I assume this is caused by the operator chaining (so that all sinks are chained to mapper 1 all end up on machine 1). But I also tried disabling chaining but I still get the same result. Some how even when the sink and the map belongs to different threads they are still placed in the same slot. My goal was to see whether it is possible to have sinks evenly distributed across the cluster (instead of all on machine 1). One way to do this is to see if it is ok to chained the sink to one of the other mapper -- the other way is to see if we can change the placement of the mapper altogether (like placing map 1 of job 2 on machine 2, map 1 of job 3 on machine 3 so we end up with sinks sit evenly throughout the cluster). Thanks. Le On Mon, Mar 4, 2019 at 6:49 AM Piotr Nowojski <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
Hi Le, As I wrote, you can try running Flink in job mode, which spawns separate clusters per each job. > Known issues: > 1. (…) > 2. if task slots are registered before slot request, the code have a tendency to group requests together on the same machine because we are using a LinkedHashMap ? Piotrek
|
Re: Task slot sharing: force reallocation
|
|
Hard to tell whether this is related to FLINK-11815. To me the setup is not fully clear. Let me try to sum it up: According to Le Xu's description there are n jobs running on a session cluster. I assume that every TaskManager has n slots. The observed behaviour is that every job allocates the slot for the first mapper and chained sink from the first TM, right? Since Flink does not give strict guarantees for the slot allocation this is possible, however it should be highly unlikely or at least change when re-executing the same setup. At the moment there is no functionality in place to control the task-slot assignment. Chaining only affects which task will be grouped together and executed by the same Task (being executed by the same thread). Separate tasks can still be executed in the same slot if they have the same slot sharing group. This means that there can be multiple threads running in each slot. For me it would be helpful to get more information about the actual job deployments. Cheers, Till On Tue, Mar 5, 2019 at 12:00 PM Piotr Nowojski <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
Hi Till: Thanks for the reply. The setup of the jobs is roughly as follows: For a cluster with N machines, we deploy X simple map/reduce style jobs (the job DAG and settings are exactly the same, except they consumes different data). Each job has N mappers (they are evenly distributed, one mapper on each machine).There are X mappers on each machine (as there are X jobs in total). Each job has only one reducer where all mappers point to. What I'm observing is that all reducers are allocated to machine 1 (where all mapper 1 from every job is allocated to). It does make sense since reducer and mapper 1 are in the same slot group. The original purpose of the questions is to find out whether it is possible to explicitly specify that reducer can be co-located with another mapper (such as mapper 2 so the reducer of job 2 can be placed on machine 2). Just trying to figure out if it is all possible without using more expensive approach (through YARN for example). But if it is not possible I will see if I can move to job mode as Piotr suggests. Thanks, Le On Tue, Mar 5, 2019 at 9:24 AM Till Rohrmann <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
Which version of Flink are you using? On Tue, Mar 5, 2019 at 10:58 PM Le Xu <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
1.3.2 -- should I update to the latest version? Thanks, Le On Wed, Mar 6, 2019 at 4:24 AM Till Rohrmann <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
The community no longer actively supports Flink < 1.6. Therefore I would try out whether you can upgrade to one of the latest versions. However, be aware that we reworked Flink's distributed architecture which slightly affected the scheduling behavior. In your case, it should actually be beneficial because it will do what you are looking for. Cheers, Till On Wed, Mar 6, 2019 at 8:13 PM Le Xu <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
Thanks Till. I switched to Flink 1.7.1 and it seems to solve part of my problem (the downstream operator does not seem to sit on the same machine anymore). But the new problem is that does Flink implicitly set all sub tasks of data sources generated by RichParallelFunction to be inside the same slot-sharing group? The older version I had seemed to evenly distributed all subtasks all over the cluster so that each machine takes the load evenly, but the new version seems to prefer to allocate all tasks into the same machine (e.g. when I'm running one job with source with parallelism of 4, it takes up 4 slots on machine 1 and leave machine 2 empty instead of distributing these tasks evenly). I am aware of the slot sharing splitting strategy described in this link. But I believe this only applies to separate streams from different source. Does Flink also support slot splitting among subtasks inside one stream as well? Thanks, Le On Thu, Mar 7, 2019 at 3:37 AM Till Rohrmann <[hidden email]> wrote:
|
Re: Task slot sharing: force reallocation
|
|
Hi Le, at the moment Flink does not allow the user to specify how the individual task a being deployed (spread out across all TMs vs. filling up a TM before using another). At the moment, the current implementation uses the second strategy. That's why you see all sources being deployed to the same machine. The corresponding JIRA issue tracking this problem is here [1]. Cheers, Till On Wed, Mar 13, 2019 at 4:21 AM Le Xu <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |