Subtask much slower than the others when creating checkpoints

Subtask much slower than the others when creating checkpoints

|
Hi,
We are using Flink 1.6.1 at the moment and we have a streaming job configured to create a checkpoint every 10 seconds. Looking at the checkpointing times in the UI, we can see that one subtask is much slower creating the endpoint, at least in its "End to End Duration", and seems caused by a longer "Checkpoint Duration (Async)". For instance, in the attach screenshot, while most of the subtasks take half a second, one (and it is always one) takes 2 seconds. But we have worse problems. We have seen cases where the checkpoint times out for one tasks, while most take one second, the outlier takes more than 5 minutes (which is the max time we allow for a checkpoint). This can happen if there is back pressure. We only allow one checkpoint at a time as well. Why could one subtask take more time? This jobs read from kafka partitions and hash by key, and we don't see any major data skew between the partitions. Does one partition do more work? We do have a cluster of 20 machines, in EMR, with TMs that have multiple slots (in legacy mode). Is this something that could have been fixed in a more recent version? Thanks for any insight! Bruno |
Re: Subtask much slower than the others when creating checkpoints
|
|
Hi Bruno, there are multiple reasons why one of the subtasks can take longer for checkpointing. It looks as if there is not much data skew since the state sizes are relatively equal. It also looks as if the individual tasks all start at the same time with the checkpointing which indicates that there mustn't be a lot of back-pressure in the DAG (or all tasks were equally back-pressured). This narrows the problem cause down to the asynchronous write operation. One potential problem could be if the external system to which you write your checkpoint data has some kind of I/O limit/quota. Maybe the sum of write accesses deplete the maximum quota you have. You could try whether running the job with a lower parallelism solves the problems. For further debugging it could be helpful to get access to the logs of the JobManager and the TaskManagers on DEBUG log level. It could also be helpful to learn which state backend you are using. Cheers, Till On Tue, Jan 8, 2019 at 12:52 PM Bruno Aranda <[hidden email]> wrote:
|
RE: Subtask much slower than the others when creating checkpoints
|
|
I have the same problem, even more impactful. Some subtasks stall forever quite consistently.
I am using Flink 1.7.1, but I've tried downgrading to 1.6.3 and it didn't help. The Backend doesn't seem to make any difference, I've tried Memory, FS and RocksDB back ends but nothing changes. I've also tried to change the medium, local spinning disk, SAN or mounted fs but nothing helps. Parallelism is the only thing which mitigates the stalling, when I set 1 everything works but if I increase the number of parallelism then everything degrades, 10 makes it very slow 30 freezes it. It's always one of two subtasks, most of them does the checkpoint in few milliseconds but there is always at least one which stalls for minutes until it times out. The Alignment seems to be a problem. I've been wondering whether some Kafka partitions where empty but there is not much data skew and the keyBy uses the same key strategy as the Kafka partitions, I've tried to use murmur2 for hashing but it didn't help either. The subtask that seems causing problems seems to be a CoProcessFunction. I am going to debug Flink but since I'm relatively new to it, it might take a while so any help will be appreciated. Pasquale From: Till Rohrmann <[hidden email]> Sent: 08 January 2019 17:35 To: Bruno Aranda <[hidden email]> Cc: user <[hidden email]> Subject: Re: Subtask much slower than the others when creating checkpoints Hi Bruno, there are multiple reasons wh= one of the subtasks can take longer for checkpointing. It looks as if the=e is not much data skew since the state sizes are relatively equal. It als= looks as if the individual tasks all start at the same time with the chec=pointing which indicates that there mustn't be a lot of back-pressure =n the DAG (or all tasks were equally back-pressured). This narrows the pro=lem cause down to the asynchronous write operation. One potential problem =ould be if the external system to which you write your checkpoint data has=some kind of I/O limit/quota. Maybe the sum of write accesses deplete the =aximum quota you have. You could try whether running the job with a lower =arallelism solves the problems. For further debug=ing it could be helpful to get access to the logs of the JobManager and th= TaskManagers on DEBUG log level. It could also be helpful to learn which =tate backend you are using. Cheers, Til= On Tue, Jan 8,=2019 at 12:52 PM Bruno Aranda <mailto:[hidden email]> wrote: Hi, We are using Flink =.6.1 at the moment and we have a streaming job configured to create a chec=point every 10 seconds. Looking at the checkpointing times in the UI, we c=n see that one subtask is much slower creating the endpoint, at least in i=s "End to End Duration", and seems caused by a longer "Chec=point Duration (Async)". For instance, in th= attach screenshot, while most of the subtasks take half a second, one (an= it is always one) takes 2 seconds. But we have w=rse problems. We have seen cases where the checkpoint times out for one ta=ks, while most take one second, the outlier takes more than 5 minutes (whi=h is the max time we allow for a checkpoint). This can happen if there is =ack pressure. We only allow one checkpoint at a time as well. Why could one subtask take more time? This jobs read from kafk= partitions and hash by key, and we don't see any major data skew betw=en the partitions. Does one partition do more work? We do have a cluster of 20 machines, in EMR, with TMs that have multiple=slots (in legacy mode). Is this something that co=ld have been fixed in a more recent version? Than=s for any insight! Bruno This e-mail and any attachments are confidential to the addressee(s) and may contain information that is legally privileged and/or confidential. Please refer to http://www.mwam.com/email-disclaimer-uk for important disclosures regarding this email. If we collect and use your personal data we will use it in accordance with our privacy policy, which can be reviewed at https://www.mwam.com/privacy-policy . Marshall Wace LLP is authorised and regulated by the Financial Conduct Authority. Marshall Wace LLP is a limited liability partnership registered in England and Wales with registered number OC302228 and registered office at George House, 131 Sloane Street, London, SW1X 9AT. If you are receiving this e-mail as a client, or an investor in an investment vehicle, managed or advised by Marshall Wace North America L.P., the sender of this e-mail is communicating with you in the sender's capacity as an associated person of and on behalf of Marshall Wace North America L.P., which is registered with the US Securities and Exchange Commission as an investment adviser. |
Re: Subtask much slower than the others when creating checkpoints
|
|
Same here Pasquale, the logs on DEBUG log level could be helpful. My guess would be that the respective tasks are overloaded or there is some resource congestion (network, disk, etc). You should see in the web UI the number of incoming and outgoing events. It would be good to check that the events are similarly sized and can be computed in roughly the same time. Cheers, Till On Mon, Jan 14, 2019 at 4:07 PM Pasquale Vazzana <[hidden email]> wrote: I have the same problem, even more impactful. Some subtasks stall forever quite consistently. |
Re: Subtask much slower than the others when creating checkpoints
|
|
Hi, Just an update from our side. We couldn't find anything specific in the logs and the problem is not easy reproducible. This week, the system is running fine, which makes me suspicious as well of some resourcing issue. But so far, we haven't been able to find the reason though we have discarded a few things. We consume from Kafka, and the load was properly balanced. We couldn't find a relationship between rate and the task manager checkpoint being slower. The problem could happen even at the times of day where we get less messages. After a flink session restart (using AWS EMR), another TM in a different machine could have been the one with the longer checkpoints. We are now trying to reproduce the problem in a different cluster by trying to send the data that was crossing the system while we saw the problems and see if we can identify something specific to it. But our data is pretty uniform, so not sure, and so far we have only seen this problem in our Prod environment and not when running stress tests which much higher load. Will come back if we figure anything out. Thanks, Bruno On Tue, 15 Jan 2019 at 10:33, Till Rohrmann <[hidden email]> wrote:
|
Re: Subtask much slower than the others when creating checkpoints
|
|
Hi,
I have seen a few cases where for certain jobs a small imbalance in the state partition assignment did cascade into a larger imbalance of the job. If your max parallelism mod parallelism is not 0, it means that some tasks have one partition more than others. Again, depending on how much partitions you have assigned to each task, in the extremest case when every task has 1 key group, except for one that has 2, imbalance can be 100%. Maybe you could check for that, especially if you were running at a different parallelism in production and stress testing. This would also explain why the any checkpoint duration is longer for a task, because it would have much more state - assuming that the load is kind of balanced between partitions. Best, Stefan
|
Re: Subtask much slower than the others when creating checkpoints
|
|
Hi Stefan, Thanks for your suggestion. As you may see from the original screenshot, the actual state is small, and even smaller than other some of the other subtasks. We are consuming from a Kafka topic with 600 partitions, with parallelism set to around 20. Our metrics show that all the subtasks are roughly getting an almost equal share of the load. In addition to the balanced consumption, the first operation in that particular is a keyBy, so it hashes and shuffling the data, producing balanced loads that are balanced too according to the metrics. The second operation is the one suffering from the issue, and it just transforms the data and puts it to another kafka topic. Thanks, Bruno On Tue, 15 Jan 2019 at 11:03, Stefan Richter <[hidden email]> wrote:
|
RE: Subtask much slower than the others when creating checkpoints
|
|
In reply to this post by Till Rohrmann
I can send you some debug logs and the execution plan, can I use your personal email? There might be sensitive info in the logs. Incoming and Outgoing records are fairly distributed across subtasks, with similar but alternate loads, when the checkpoint is triggered,
the load drops to nearly zero, all the fetch requests sent to kafka (2.0.1) time out and often the clients disconnect from the brokers. Both source topics are 30 partitions each, they get keyed, connected and co-processed. I am checkpointing with EOS, as I said I’ve tried all the backend with either DELETE_ON_CANCELLATION or RETAIN_ON_CANCELLATION. I assume
that using the MemoryStateBackend and CANCELLATION should remove any possibility of disk/IO congestions, am I wrong?.
Pasquale From: Till Rohrmann <[hidden email]>
Same here Pasquale, the logs on DEBUG log level could be helpful. My guess would be that the respective tasks are overloaded or there is some resource congestion (network, disk, etc). You should see in the web UI the number of incoming and outgoing events. It would be good to check that the events are similarly sized and can be computed in roughly the same time. Cheers, Till On Mon, Jan 14, 2019 at 4:07 PM Pasquale Vazzana <[hidden email]> wrote:
This e-mail and any attachments are confidential to the addressee(s) and may
contain information that is legally privileged and/or confidential. Please refer
to http://www.mwam.com/email-disclaimer-uk
for important disclosures regarding this email. If we collect and use your
personal data we will use it in accordance with our privacy policy, which can be
reviewed at https://www.mwam.com/privacy-policy.
Marshall Wace LLP is authorised and regulated by the Financial Conduct Authority. Marshall Wace LLP is a limited liability partnership registered in England and Wales with registered number OC302228 and registered office at George House, 131 Sloane Street, London, SW1X 9AT. If you are receiving this e-mail as a client, or an investor in an investment vehicle, managed or advised by Marshall Wace North America L.P., the sender of this e-mail is communicating with you in the sender's capacity as an associated person of and on behalf of Marshall Wace North America L.P., which is registered with the US Securities and Exchange Commission as an investment adviser. |
Re: Subtask much slower than the others when creating checkpoints
|
|
Hi Pasquale, if you configured a checkpoint directory, then the MemoryStateBackend will also write the checkpoint data to disk in order to persist it. Cheers, Till On Tue, Jan 15, 2019 at 1:08 PM Pasquale Vazzana <[hidden email]> wrote:
|
RE: Subtask much slower than the others when creating checkpoints
|
|
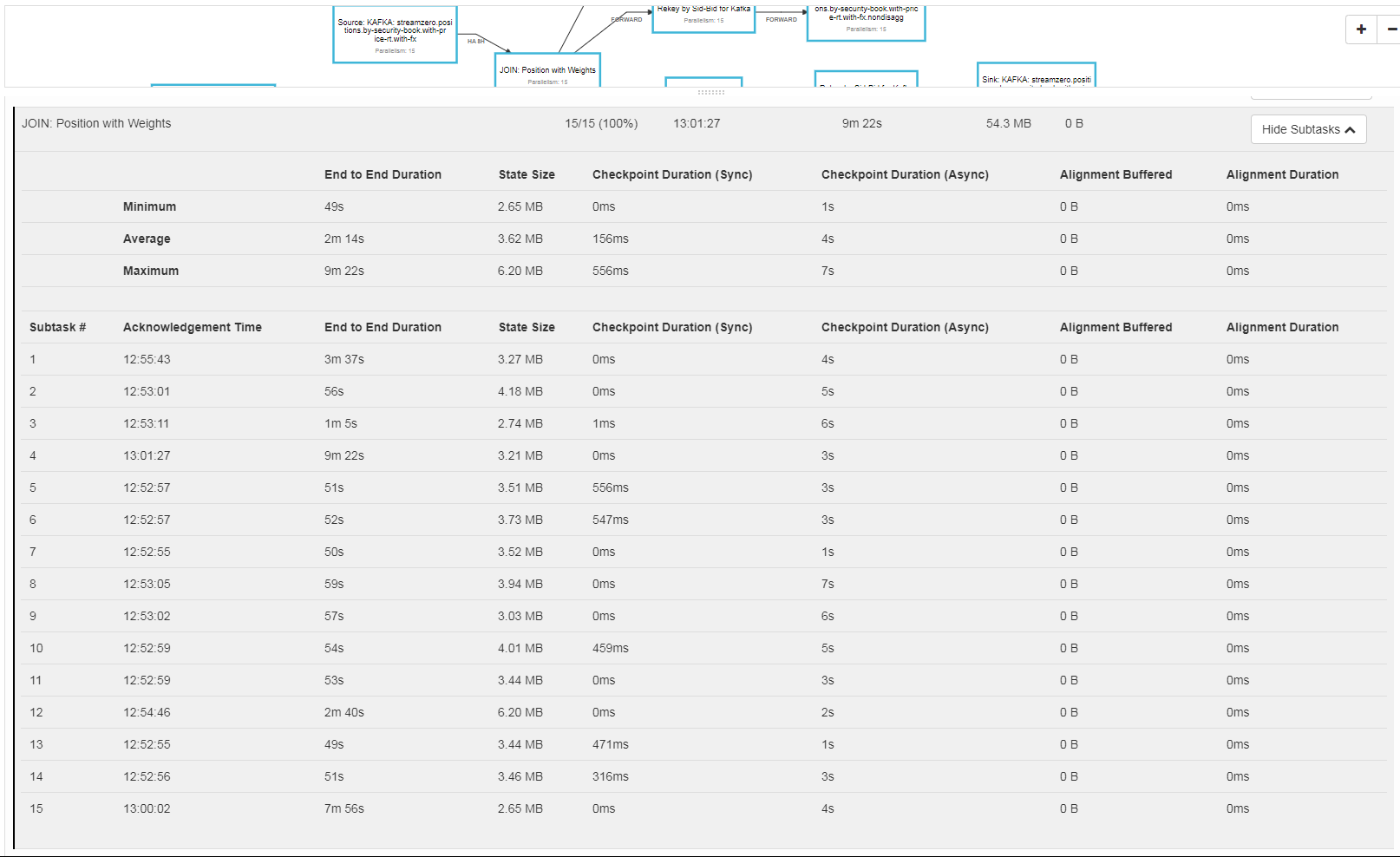
Hi Till, No I don’t, I’ve used the MemoryStateBackend with no checkpointPath. I’m attaching a screenshot with some checkpoint details, if I
lower the parallelism to 15 I can get some checkpoints working but you can still see how some subtasks are significantly slower than other.
From: Till Rohrmann <[hidden email]>
Hi Pasquale, if you configured a checkpoint directory, then the MemoryStateBackend will also write the checkpoint data to disk in order to persist it. Cheers, Till On Tue, Jan 15, 2019 at 1:08 PM Pasquale Vazzana <[hidden email]> wrote:
This e-mail and any attachments are confidential to the addressee(s) and may
contain information that is legally privileged and/or confidential. Please refer
to http://www.mwam.com/email-disclaimer-uk
for important disclosures regarding this email. If we collect and use your
personal data we will use it in accordance with our privacy policy, which can be
reviewed at https://www.mwam.com/privacy-policy.
Marshall Wace LLP is authorised and regulated by the Financial Conduct Authority. Marshall Wace LLP is a limited liability partnership registered in England and Wales with registered number OC302228 and registered office at George House, 131 Sloane Street, London, SW1X 9AT. If you are receiving this e-mail as a client, or an investor in an investment vehicle, managed or advised by Marshall Wace North America L.P., the sender of this e-mail is communicating with you in the sender's capacity as an associated person of and on behalf of Marshall Wace North America L.P., which is registered with the US Securities and Exchange Commission as an investment adviser. |
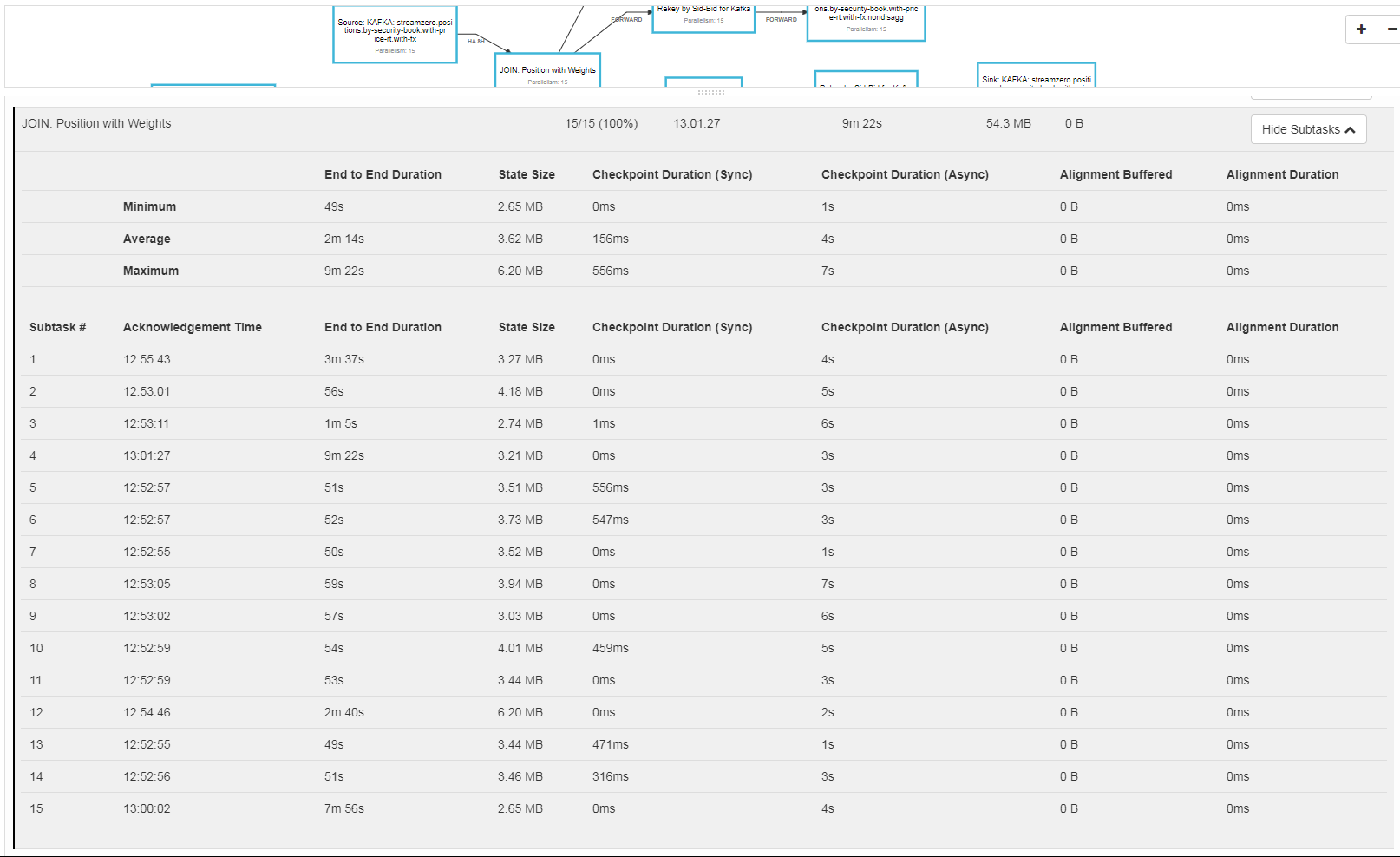
Re: Subtask much slower than the others when creating checkpoints
|
|
I'm very interested in this thread. I've also recently seen very similar issues with some of our Flink jobs. The thing that is perplexing here is that there is essentially no alignment time, and both sync and async checkpoint times are trivial -- but nonetheless the end to end time for some subtasks is several minutes. I've seen this exact behavior with some of our production jobs and haven't gotten to the bottom of it yet. Pasquale, have you opened a JIRA for this? -Jamie On Tue, Jan 15, 2019 at 8:06 AM Pasquale Vazzana <[hidden email]> wrote:
|
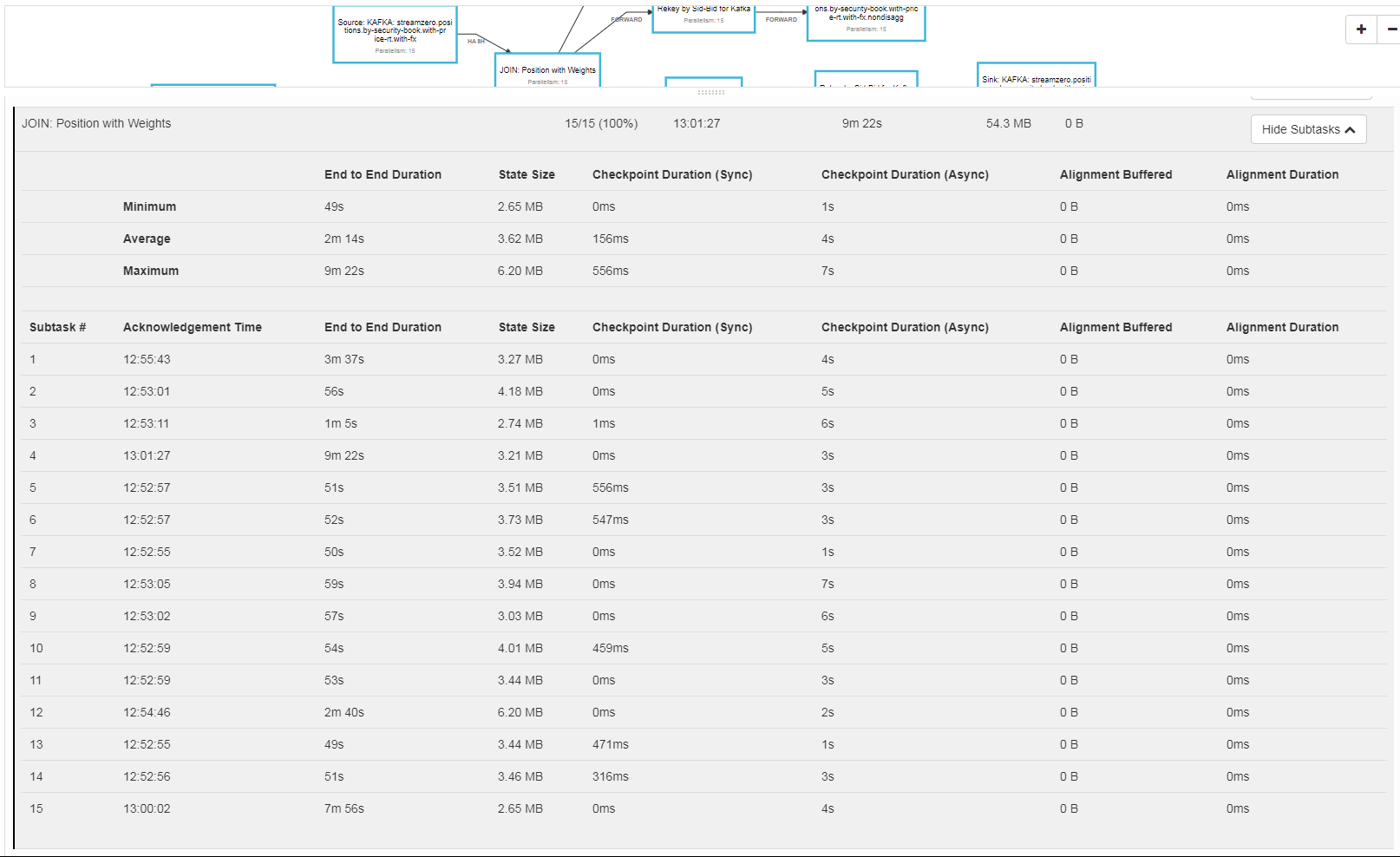
RE: Subtask much slower than the others when creating checkpoints
|
|
Hi Jamie, No I didn’t, yet. I started switching some of our pipelines to Flink only a month ago so I’m still in that stage where you need to
understand when is a bug or whether you’re doing things wrong. This issue seems to be a bug, an impactful one, so at the end of my investigation I’ll open a ticket with all the elements I collected and if I get familiar enough with the codebase I’ll submit
a PR. Pasquale From: Jamie Grier <[hidden email]>
I'm very interested in this thread. I've also recently seen very similar issues with some of our Flink jobs. The thing that is perplexing here is that there is essentially no alignment time, and both sync and async checkpoint times are
trivial -- but nonetheless the end to end time for some subtasks is several minutes. I've seen this exact behavior with some of our production jobs and haven't gotten to the bottom of it yet. Pasquale, have you opened a JIRA for this? -Jamie On Tue, Jan 15, 2019 at 8:06 AM Pasquale Vazzana <[hidden email]> wrote:
This e-mail and any attachments are confidential to the addressee(s) and may
contain information that is legally privileged and/or confidential. Please refer
to http://www.mwam.com/email-disclaimer-uk
for important disclosures regarding this email. If we collect and use your
personal data we will use it in accordance with our privacy policy, which can be
reviewed at https://www.mwam.com/privacy-policy.
Marshall Wace LLP is authorised and regulated by the Financial Conduct Authority. Marshall Wace LLP is a limited liability partnership registered in England and Wales with registered number OC302228 and registered office at George House, 131 Sloane Street, London, SW1X 9AT. If you are receiving this e-mail as a client, or an investor in an investment vehicle, managed or advised by Marshall Wace North America L.P., the sender of this e-mail is communicating with you in the sender's capacity as an associated person of and on behalf of Marshall Wace North America L.P., which is registered with the US Securities and Exchange Commission as an investment adviser. |
|
|
I can share a data skew problem that we observed in our production jobs that can cause such symptoms. It's not the key group count or byte rate imbalance At high level, this job update keyed state to join two streams. Sometimes, we observed checkpoint keep timing out (30m). The reason is some keys have tens of thousands events. when accumulating and updating RocksDB with tens of thousands events for the same key, it cause super high read and write amplifications. EBS volume IOPS/throughput become bottleneck. After we capped the number of events (e.g. to 200), our job stabilized. Thanks, Steven On Wed, Jan 16, 2019 at 12:57 AM Pasquale Vazzana <[hidden email]> wrote:
|
RE: Subtask much slower than the others when creating checkpoints
|
|
Hi Steven, thank you for sharing your experience. I think it’s definitely related to the subtask load, the output volume seems to be especially impactful.
In my case the number of keys is equally distributed and the input records are pretty much the same across subtasks but some subtasks
produce much more data in output, because of the join logic, the strange thing is that the subtasks which are more busy are not necessary the ones that fail to checkpoint, I’ll investigate more by adding more metrics and report the results to this mailing
list. From: Steven Wu <[hidden email]>
I can share a data skew problem that we observed in our production jobs that can cause such symptoms. It's not the key group count or byte rate imbalance At high level, this job update keyed state to join two streams. Sometimes, we observed checkpoint keep timing out (30m). The reason is some keys have tens of thousands events. when accumulating and updating RocksDB with tens of thousands
events for the same key, it cause super high read and write amplifications. EBS volume IOPS/throughput become bottleneck. After we
capped the number of events (e.g. to 200), our job stabilized. Thanks, Steven On Wed, Jan 16, 2019 at 12:57 AM Pasquale Vazzana <[hidden email]> wrote:
This e-mail and any attachments are confidential to the addressee(s) and may
contain information that is legally privileged and/or confidential. Please refer
to http://www.mwam.com/email-disclaimer-uk
for important disclosures regarding this email. If we collect and use your
personal data we will use it in accordance with our privacy policy, which can be
reviewed at https://www.mwam.com/privacy-policy.
Marshall Wace LLP is authorised and regulated by the Financial Conduct Authority. Marshall Wace LLP is a limited liability partnership registered in England and Wales with registered number OC302228 and registered office at George House, 131 Sloane Street, London, SW1X 9AT. If you are receiving this e-mail as a client, or an investor in an investment vehicle, managed or advised by Marshall Wace North America L.P., the sender of this e-mail is communicating with you in the sender's capacity as an associated person of and on behalf of Marshall Wace North America L.P., which is registered with the US Securities and Exchange Commission as an investment adviser. |
| Free forum by Nabble | Edit this page |