Streaming program gets stucks when accesing to AWS Kinesis

Streaming program gets stucks when accesing to AWS Kinesis

|
Hi,
I have written a program that connect to the example stock tickers stream on AWS Kinesis and filters out those related to tech sector. I have tried on my local machine running `sbt run' an everything seems OK. Then I have moved to AWS EMR (emr-5.1.0). I've installed the Flink distribution instead of the AWS one and patched with FLINK-5013 and then run it directly using sbt directly with the run goal. Everything went OK too. After that I have packaged and tried to run it on yarn. The process starts correctly but it seems it doesn't get events on the shard consumer. I'm trying to run my code with the following command: HADOOP_CONF_DIR=/etc/hadoop/conf ./flink run -m yarn-cluster -yn 1 /home/hadoop/poc-flink/flink-iniciativa/target/scala-2.10/flink-test-assembly-0.1-SNAPSHOT.jar Output from this is: Submitting job with JobID: 7b4251b5c99e5b2483b1f6f523828b4b. Waiting for job completion. Connected to JobManager at Actor[akka.tcp://flink@10.88.165.57:42632/user/jobmanager#-915903176] 11/19/2016 02:29:14 Job execution switched to status RUNNING. 11/19/2016 02:29:14 Source: Custom Source -> Map -> Filter -> Sink: Unnamed(1/1) switched to SCHEDULED 11/19/2016 02:29:14 Source: Custom Source -> Map -> Filter -> Sink: Unnamed(1/1) switched to DEPLOYING 11/19/2016 02:29:15 Source: Custom Source -> Map -> Filter -> Sink: Unnamed(1/1) switched to RUNNING ... -> NOTHING HERE Output on local running sbt run is: 16/11/19 03:47:31 INFO client.JobSubmissionClientActor: 11/19/2016 03:47:31 Source: Custom Source -> Map -> Filter -> Sink: Unnamed(2/4) switched to RUNNING 11/19/2016 03:47:31 Source: Custom Source -> Map -> Filter -> Sink: Unnamed(2/4) switched to RUNNING 16/11/19 03:47:33 INFO internals.KinesisDataFetcher: Subtask 3 has no initial shards to read on startup; emitting max value watermark ... 16/11/19 03:47:33 INFO internals.KinesisDataFetcher: Subtask 2 has no initial shards to read on startup; emitting max value watermark ... 16/11/19 03:47:33 INFO internals.KinesisDataFetcher: Subtask 0 has no initial shards to read on startup; emitting max value watermark ... 16/11/19 03:47:33 INFO internals.KinesisDataFetcher: Subtask 1 will be seeded with initial shard KinesisStreamShard{streamName='kinesis-analytics-demo-stream', shard='{ShardId: shardId-000000000000,HashKeyRange: {StartingHashKey: 0,EndingHashKey: 340282366920938463463374607431768211455},SequenceNumberRange: {StartingSequenceNumber: 49567760169827421811394169911314244086923402164266074114,}}'}, starting state set as sequence number LATEST_SEQUENCE_NUM 16/11/19 03:47:33 INFO internals.KinesisDataFetcher: Subtask 1 will start consuming seeded shard KinesisStreamShard{streamName='kinesis-analytics-demo-stream', shard='{ShardId: shardId-000000000000,HashKeyRange: {StartingHashKey: 0,EndingHashKey: 340282366920938463463374607431768211455},SequenceNumberRange: {StartingSequenceNumber: 49567760169827421811394169911314244086923402164266074114,}}'} from sequence number LATEST_SEQUENCE_NUM with ShardConsumer 0 2> StockTicker(CVB,TECHNOLOGY,-0.22,52.6) 2> StockTicker(NFLX,TECHNOLOGY,-0.35,97.22) 2> StockTicker(NFLX,TECHNOLOGY,1.12,98.34) 2> StockTicker(CVB,TECHNOLOGY,-0.19,52.41) 2> StockTicker(BNM,TECHNOLOGY,3.18,179.34) 2> StockTicker(CVB,TECHNOLOGY,0.4,52.81) 2> StockTicker(DFG,TECHNOLOGY,1.92,139.2) Dependencies on my sbt.build file are: val flinkDependencies = Seq( "org.apache.flink" % "flink-scala_2.10" % flinkVersion % "provided", "org.apache.flink" % "flink-streaming-scala_2.10" % flinkVersion % "provided", "org.apache.flink" % "flink-connector-kafka-0.8_2.10" % flinkVersion % "provided", "org.apache.flink" % "flink-connector-kinesis_2.10" % "1.2-SNAPSHOT", "org.apache.flink" % "flink-connector-elasticsearch2_2.10" % "1.2-SNAPSHOT", "org.apache.flink" % "flink-connector-wikiedits_2.10" % "1.2-hadoop1-SNAPSHOT", "com.google.code.gson" % "gson" % "2.7" % "provided", "org.scalactic" %% "scalactic" % "3.0.0" % "test", "org.scalatest" %% "scalatest" % "3.0.0" % "test") Checking the Flink console it confirmed the output, no events are read. I also don't understand second image capture that says that streaming job is not set. 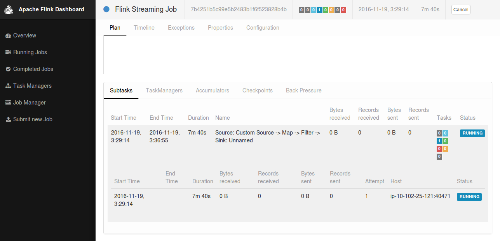 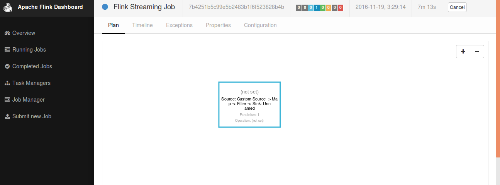 I'm kind of stuck and any help will be appreciated. Regards, Iván. |
Re: Streaming program gets stucks when accesing to AWS Kinesis
|
|
Hi, if you're outputting data using .print() then those will go into the stdout of the task managers. You should see this in the .out log of your Yarn machines. For running on Yarn I suggest to use a proper source that emits to some external system. Cheers, Aljoscha On Sat, 19 Nov 2016 at 10:14 IvanFernandez <[hidden email]> wrote: Hi, |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |