Statefun 2.2.2 Checkpoint restore NPE

Statefun 2.2.2 Checkpoint restore NPE

|
Hi, Just checking to see if anyone has experienced this error. Might just be a Flink thing that's irrelevant to statefun, but my job keeps failing over and over with this message: 2021-05-28 03:51:13,001 INFO org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer [] - Starting FlinkKafkaInternalProducer (10/10) to produce into default topic __stateful_functions_random_topic_lNVlkW9SkYrtZ1oK 2021-05-28 03:51:13,001 INFO org.apache.flink.streaming.connectors.kafka.internal.FlinkKafkaInternalProducer [] - Attempting to resume transaction feedback-union -> functions -> Sink: bluesteel-kafka_egress-egress-dd0a6f77c8b5eccd4b7254cdfd577ff9-45 with producerId 31 and epoch 3088 2021-05-28 03:51:13,017 WARN org.apache.flink.runtime.taskmanager.Task [] - Source: lead-leads-ingress -> router (leads) (10/10) (ff51aacdb850c6196c61425b82718862) switched from RUNNING to FAILED. java.lang.NullPointerException: null The null pointer doesn't come with any stack traces or anything. It's really mystifying. Seems to just fail while restoring continuously. Thanks, Tim |
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
Hi Timothy, It would indeed be hard to figure this out without any stack traces. Have you tried changing to debug level logs? Maybe you can also try using the StateFun Harness to restore and run your job in the IDE - in that case you should be able to see which code exactly is throwing this exception. Cheers, Gordon On Fri, May 28, 2021 at 12:39 PM Timothy Bess <[hidden email]> wrote:
|
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
Hi Tim, Any additional logs from before are highly appreciated, this would help us to trace this issue. By the way, do you see something in the JobManager's UI? On Fri, May 28, 2021 at 9:06 AM Tzu-Li (Gordon) Tai <[hidden email]> wrote:
|
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
If logs are not helping, I think the remaining option is to attach a debugger [1]. I'd probably add a breakpoint to LegacySourceFunctionThread#run and see what happens. If the issue is in recovery, you should add a breakpoint to StreamTask#beforeInvoke. On Fri, May 28, 2021 at 1:11 PM Igal Shilman <[hidden email]> wrote:
|
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
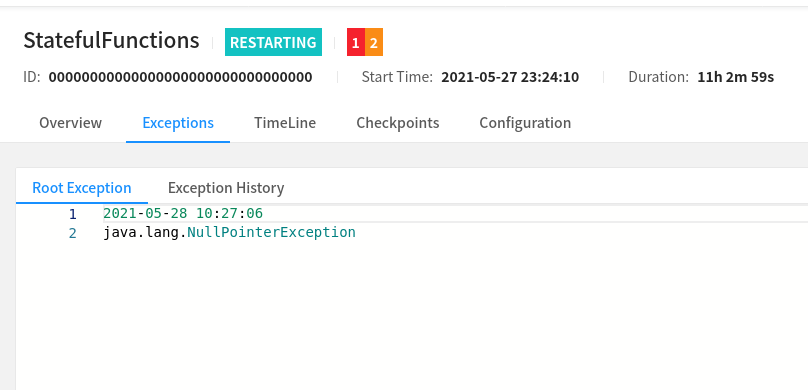
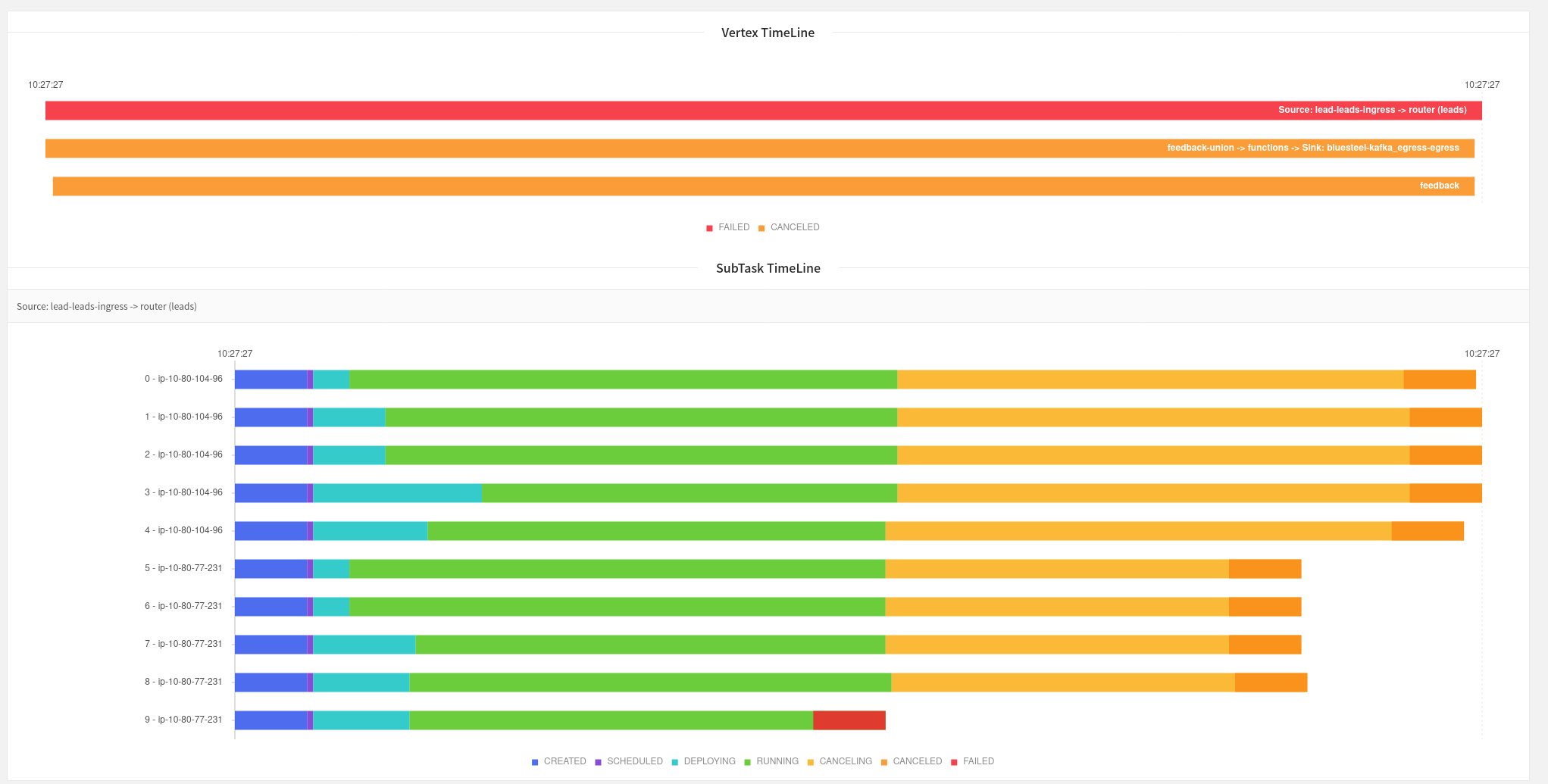
Oh wow that Harness looks cool, I'll have to take a look at that. Unfortunately the JobManager UI seems to just show this: 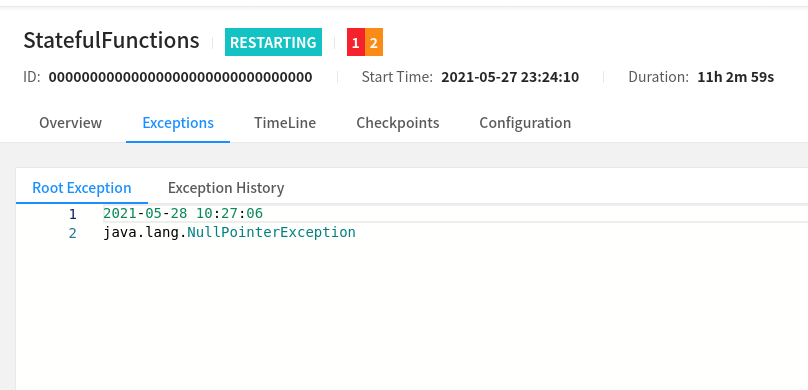 Though it does seem that maybe the source function is where the failure is happening according to this? 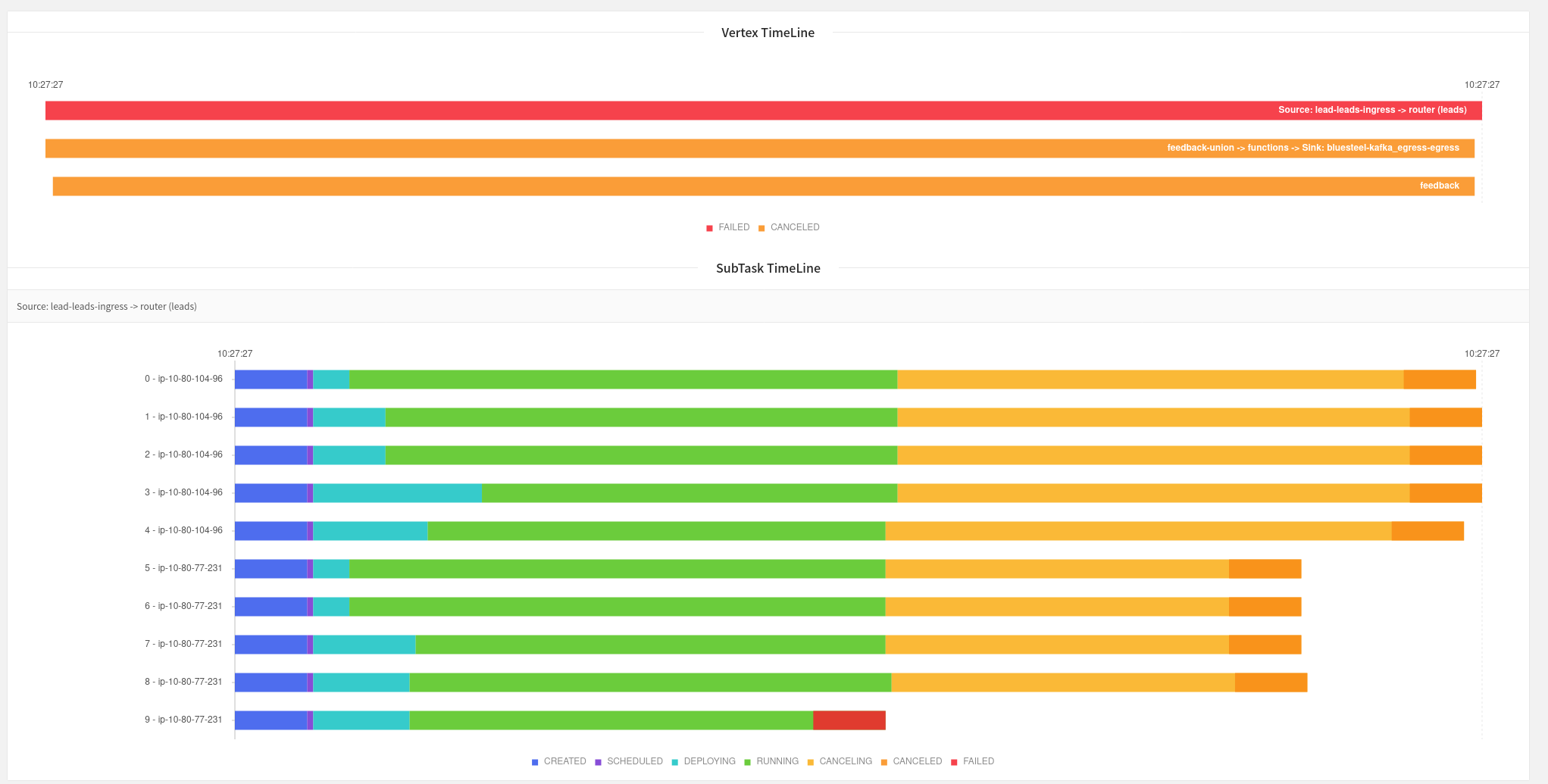 Still investigating, but I do see a lot of these logs: 2021-05-28 14:25:09,199 WARN org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction [] - Transaction KafkaTransactionState [transactionalId=feedback-union -> functions -> Sink: bluesteel-kafka_egress-egress-dd0a6f77c8b5eccd4b7254cdfd577ff9-39, producerId=2062, epoch=2684] has been open for 55399128 ms. This is close to or even exceeding the transaction timeout of 900000 ms. Seems like it's restoring some old kafka transaction? Not sure. I like Arvid's idea of attaching a debugger, I'll definitely give that a try. On Fri, May 28, 2021 at 7:49 AM Arvid Heise <[hidden email]> wrote:
|
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
Ok so after digging into it a bit it seems that the exception was thrown here: https://github.com/apache/flink-statefun/blob/release-2.2/statefun-flink/statefun-flink-io-bundle/src/main/java/org/apache/flink/statefun/flink/io/kafka/RoutableProtobufKafkaIngressDeserializer.java#L48 I think it'd be useful to have a configuration to prevent null keys from halting processing. It looks like we are occasionally publishing with a key string that is sometimes empty, and that is interpreted by Kafka as null. Then when it's read back in, the ingress chokes on the null value. I'm trying to keep from having to edit statefun and use my own jar, any thoughts? Thanks, Tim On Fri, May 28, 2021 at 10:33 AM Timothy Bess <[hidden email]> wrote:
|
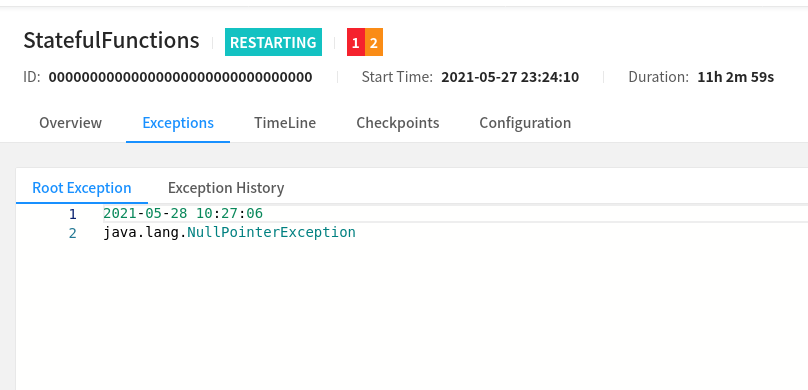
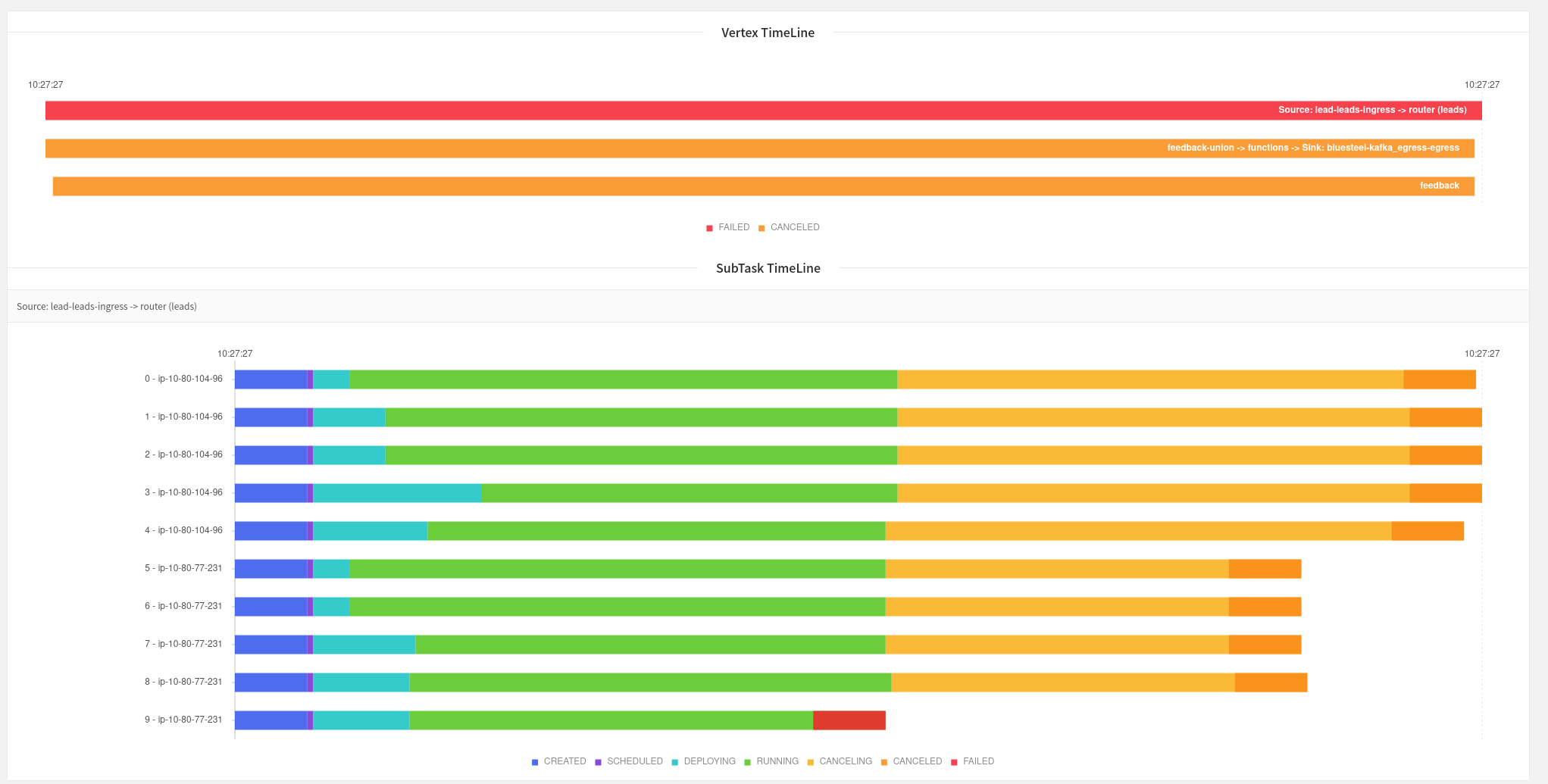
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
Hi Tim, It is unfortunate that the error message was so minimal, we'll definitely improve that (FLINK-22809). Skipping NULL keys is a bit problematic, although technically possible, I'm not sure that this is how we should handle this. Let me follow up on that. The way you can customize the behaviour of that connector without having to fork StateFun, is to define an ingress with a different deserializer. You would have to use the StatefulFunctionModule [1][2] and bind an ingress, you can use the KafkaIngressBuilder [3] and set KafkaIngressBuilde::withDeserializer() You would also have to define a router to route these messages to target functions. I've prepared a minimal example for you here: [4] I hope this helps, Igal. On Fri, May 28, 2021 at 8:19 PM Timothy Bess <[hidden email]> wrote:
|
Re: Statefun 2.2.2 Checkpoint restore NPE
|
|
Hi Igal, Thanks for the help! I'll switch over to that. I ended up defaulting null to empty string in that deserializer and deploying my own jar to get production going again. The thing that makes this case tricky is that my code was publishing empty string, not null, and that is apparently interpretted by Kakfa as null. So then it's read back in and halts processing because of the null. I think it might make sense to have a property/setting that defaults the ID or skips the event. Otherwise it becomes a poison pill. Thanks, Tim On Mon, May 31, 2021, 7:59 AM Igal Shilman <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |