Spread Kafka sink tasks over different nodes

Spread Kafka sink tasks over different nodes

|
Hi, We have total 224 cores (as each TM has 32 slots) and we want to use all slots for a single streaming job. The single job roughly consists of the following three types of tasks: - Kafka source tasks (Parallelism : 7 as the number of partitions in the input topic is 7) - Session window tasks (Parallelism : 224) - Kafka sink tasks (Parallelism : 7 as the number of partitions in the output topic is 7) We want 7 sources and 7 sinks to be evenly scheduled over different nodes. Source tasks are scheduled as wanted (see "1 source.png"). 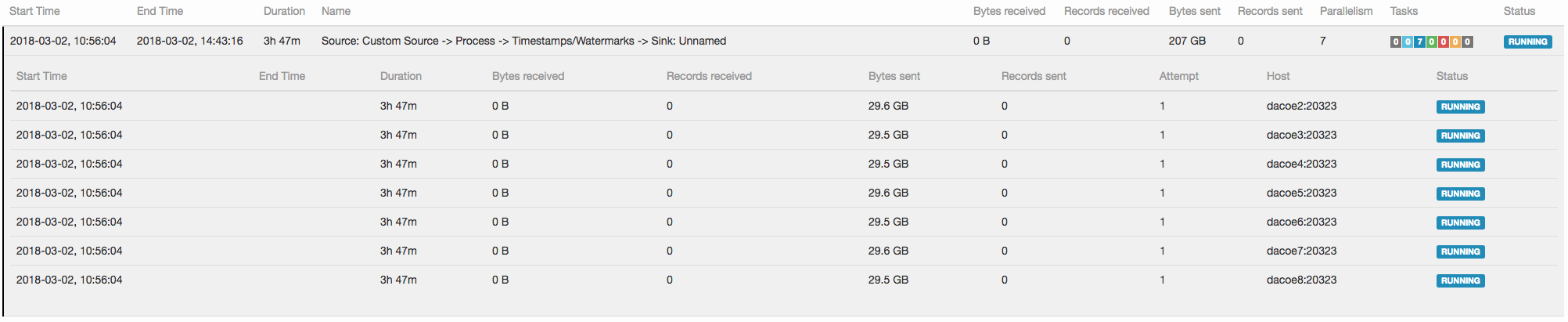 However, sink tasks are scheduled on a single node (see "2 sink.png"). 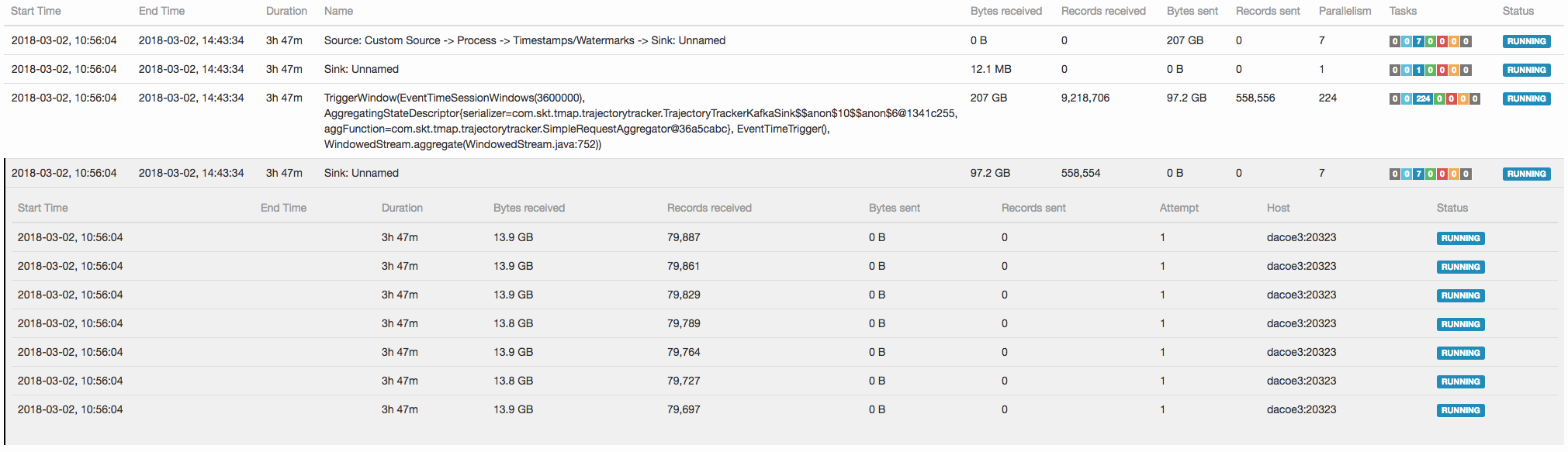 As we use the whole standalone only for a single job, this scheduling behavior causes the output of all the 224 session window tasks to be sent to a single physical machine. Is it because locality is only considered in Kafka source? I also check that different partitions are taken care by different brokers for both of the input topic and the output topic in Kafka. Do I miss something in order to spread Kafka sink tasks over different nodes? Best, - Dongwon |
Re: Spread Kafka sink tasks over different nodes
|
|
Hi Dongwon,
I think there is currently no way of ensuring that tasks are spread out across different machines because the scheduling logic does not take into account what machine a slot is on. I currently see two workarounds: - Let all operations have the same parallelism and only have 8 slots in your cluster in total - Let your sinks have parallelism 224 (same as the windows). I think multiple sinks writing to the same Kafka partition should not be a problem. Unless that's a problem in your setup, of course. What do you think? Best, Aljoscha > On 2. Mar 2018, at 06:55, Dongwon Kim <[hidden email]> wrote: > > Hi, > > We have a standalone cluster where 1 JM and 7 TMs are running on 8 servers. > We have total 224 cores (as each TM has 32 slots) and we want to use all slots for a single streaming job. > > The single job roughly consists of the following three types of tasks: > - Kafka source tasks (Parallelism : 7 as the number of partitions in the input topic is 7) > - Session window tasks (Parallelism : 224) > - Kafka sink tasks (Parallelism : 7 as the number of partitions in the output topic is 7) > > We want 7 sources and 7 sinks to be evenly scheduled over different nodes. > Source tasks are scheduled as wanted (see "1 source.png"). > <1 source.png> > > However, sink tasks are scheduled on a single node (see "2 sink.png"). > <2 sink.png> > > As we use the whole standalone only for a single job, this scheduling behavior causes the output of all the 224 session window tasks to be sent to a single physical machine. > > Is it because locality is only considered in Kafka source? > I also check that different partitions are taken care by different brokers for both of the input topic and the output topic in Kafka. > > Do I miss something in order to spread Kafka sink tasks over different nodes? > > Best, > > - Dongwon |
Re: Spread Kafka sink tasks over different nodes
|
|
Hi Aljoscha and Robert,
You guys are right. I resubmit the application with # session window tasks equal to # Kafka sink tasks. I never thought that multiple different Kafka tasks can write to the same partition. Initially, I do not set the default parallelism and I explicitly set # partitions of each stage. This decision naturally led me to set # Kafka sink stage to # of Kafka partitions. Sorry for the confusion :-) Best, Dongwon > 2018. 3. 6. 오후 10:28, Aljoscha Krettek <[hidden email]> 작성: > > Hi Dongwon, > > I think there is currently no way of ensuring that tasks are spread out across different machines because the scheduling logic does not take into account what machine a slot is on. I currently see two workarounds: > > - Let all operations have the same parallelism and only have 8 slots in your cluster in total > - Let your sinks have parallelism 224 (same as the windows). I think multiple sinks writing to the same Kafka partition should not be a problem. Unless that's a problem in your setup, of course. > > What do you think? > > Best, > Aljoscha > >> On 2. Mar 2018, at 06:55, Dongwon Kim <[hidden email]> wrote: >> >> Hi, >> >> We have a standalone cluster where 1 JM and 7 TMs are running on 8 servers. >> We have total 224 cores (as each TM has 32 slots) and we want to use all slots for a single streaming job. >> >> The single job roughly consists of the following three types of tasks: >> - Kafka source tasks (Parallelism : 7 as the number of partitions in the input topic is 7) >> - Session window tasks (Parallelism : 224) >> - Kafka sink tasks (Parallelism : 7 as the number of partitions in the output topic is 7) >> >> We want 7 sources and 7 sinks to be evenly scheduled over different nodes. >> Source tasks are scheduled as wanted (see "1 source.png"). >> <1 source.png> >> >> However, sink tasks are scheduled on a single node (see "2 sink.png"). >> <2 sink.png> >> >> As we use the whole standalone only for a single job, this scheduling behavior causes the output of all the 224 session window tasks to be sent to a single physical machine. >> >> Is it because locality is only considered in Kafka source? >> I also check that different partitions are taken care by different brokers for both of the input topic and the output topic in Kafka. >> >> Do I miss something in order to spread Kafka sink tasks over different nodes? >> >> Best, >> >> - Dongwon > |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |