Source Operators Stuck in the requestBufferBuilderBlocking

Source Operators Stuck in the requestBufferBuilderBlocking

|
Hi,
I keep seeing the following situation where a task is blocked getting a MemorySegment from the pool but the operator is still reporting. I'm completely stumped as to how to debug or what to look at next so any hints/help/advice would be greatly appreciated! The situation is as follows (Flink 1.12.2): As you can see from 02:00 to 08:00, no records is produced from this purchase source while there still a bunch of records need to be processed from Kafka. And during this period of time. The outPoolUsage is around 0.6 and the downstream operators seems also have the available buffer. We redeployed the job and disabled unaligned checkpoint at around 9 so it becomes normal now. The thread dump we took shows that we are stuck here: "Legacy Source Thread - Source: Kafka Reader - ACCOUNT - kafka-bootstrap-url.com:9443 (1/5)#2" #9250 prio=5 os_prio=0 cpu=5 9490.62ms elapsed=8399.28s tid=0x00007f0e99c23910 nid=0x2df5 waiting on condition [0x00007f0fa85fe000] java.lang.Thread.State: WAITING (parking) at jdk.internal.misc.Unsafe.park(java.base@11.0.8/Native Method) - parking to wait for <0x00000000ab5527c8> (a java.util.concurrent.CompletableFuture$Signaller) at java.util.concurrent.locks.LockSupport.park(java.base@11.0.8/LockSupport.java:194) at java.util.concurrent.CompletableFuture$Signaller.block(java.base@11.0.8/CompletableFuture.java:1796) at java.util.concurrent.ForkJoinPool.managedBlock(java.base@11.0.8/ForkJoinPool.java:3128) at java.util.concurrent.CompletableFuture.waitingGet(java.base@11.0.8/CompletableFuture.java:1823) at java.util.concurrent.CompletableFuture.get(java.base@11.0.8/CompletableFuture.java:1998) at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestMemorySegmentBlocking(LocalBufferPool.java:319) at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestBufferBuilderBlocking(LocalBufferPool.java:291) at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewBufferBuilderFromPool(BufferWritingResultPartition.java:337) at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewUnicastBufferBuilder(BufferWritingResultPartition.java:313) at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.appendUnicastDataForRecordContinuation(BufferWritingResultPartition.java:257) at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.emitRecord(BufferWritingResultPartition.java:149) at org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit(RecordWriter.java:104) at org.apache.flink.runtime.io.network.api.writer.ChannelSelectorRecordWriter.emit(ChannelSelectorRecordWriter.java:54) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:101) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:87) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:43) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28) at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollectWithTimestamp(StreamSourceContexts.java:322) at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collectWithTimestamp(StreamSourceContexts.java:426) - locked <0x00000000aef80e00> (a java.lang.Object) |
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Hi Sihan, thanks for reporting. This looks like a bug to me. I have opened an investigation ticket with the highest priority [1]. Could you please provide some more context, so we have a chance to reproduce? 1. How long did the job run until it got stuck? 2. How often do you checkpoint or how many checkpoints succeeded? 3. What were the typical checkpoint sizes? How much in-flight data was checkpointed? (A screenshot of the checkpoint tab in the Flink UI would suffice) 4. Was the parallelism of the whole job 5? How is the topology roughly looking? (e.g., Source -> Map -> Sink?) 5. Did you see any warns/errors in the logs related to checkpointing and I/O? 6. What was your checkpoint storage (e.g. S3)? Is the application running in the same data-center (e.g. AWS)? On Thu, Mar 25, 2021 at 3:00 AM Sihan You <[hidden email]> wrote:
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Hi Sihan, More importantly, could you create some example job that can reproduce that problem? It can have some fake sources and no business logic, but if you could provide us with something like that, it would allow us to analyse the problem without going back and forth with tens of questions. Best, Piotrek pt., 26 mar 2021 o 11:40 Arvid Heise <[hidden email]> napisał(a):
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
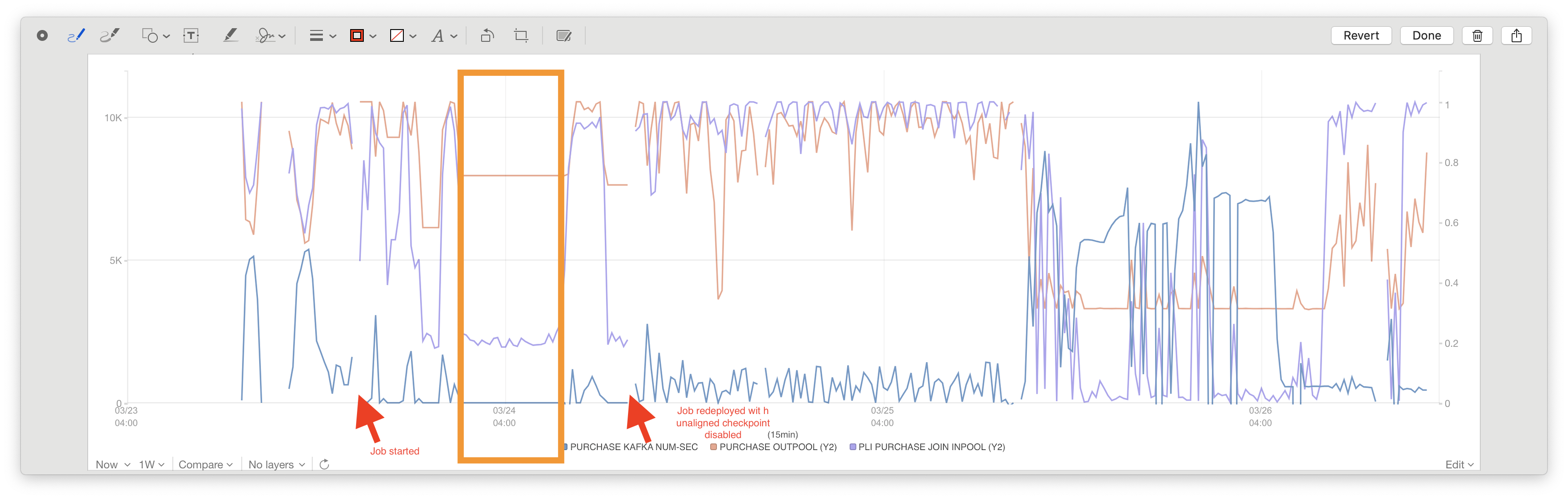
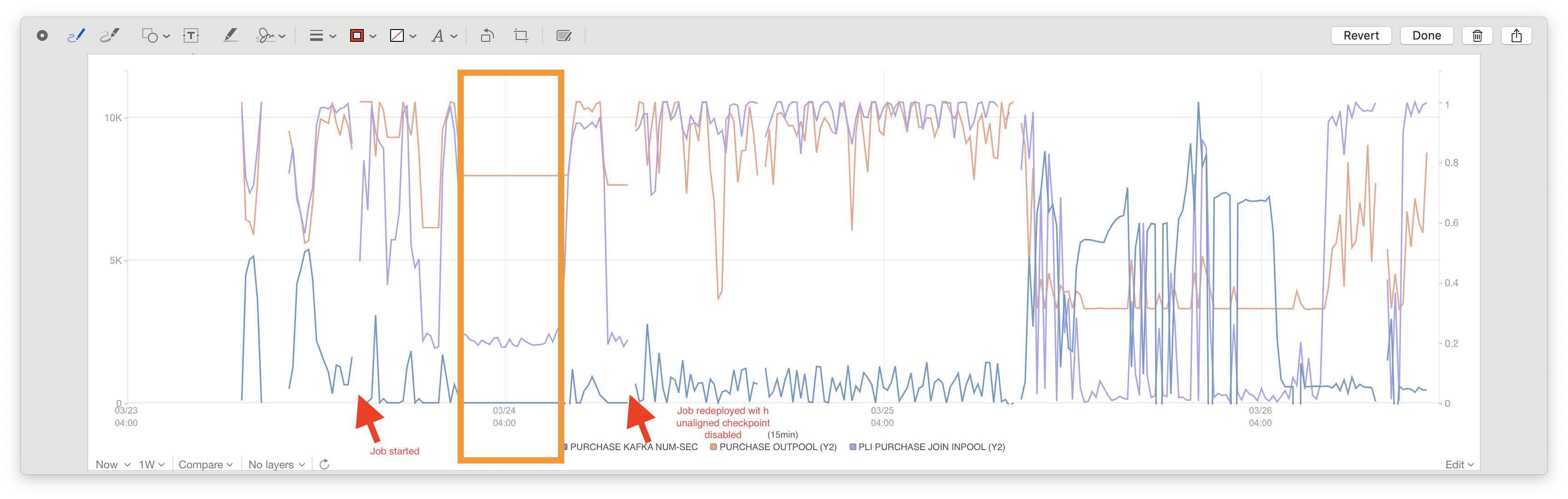
Hi, Thanks for responding. I'm working in a commercial organization so I cannot share the detailed stack with you. I will try to describe the issue as specific as I can. 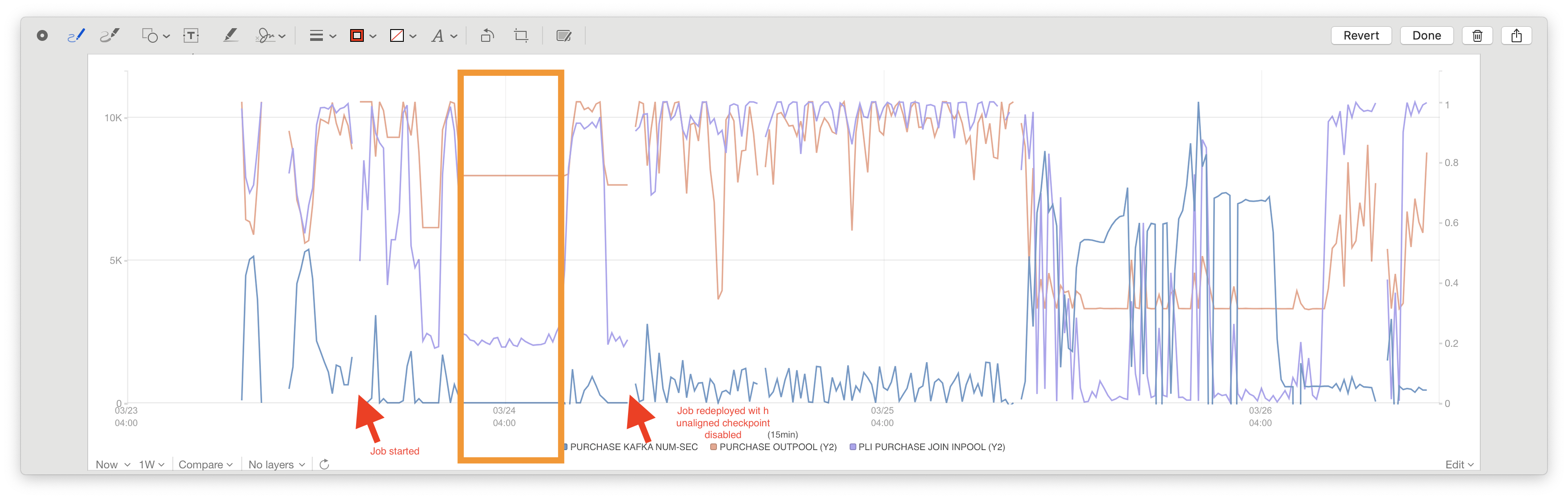 above is a more detailed stats of our job. 1. How long did the job run until it got stuck? about 9 hours. 2. How often do you checkpoint or how many checkpoints succeeded? I don't remember the exact number of the successful checkpoints, but there should be around 2. then the checkpoint started to fail because of the timeout. 3. What were the typical checkpoint sizes? How much in-flight data was checkpointed? (A screenshot of the checkpoint tab in the Flink UI would suffice) the first checkpoint is 5T and the second is 578G. 4. Was the parallelism of the whole job 5? How is the topology roughly looking? (e.g., Source -> Map -> Sink?) the source is a union of two source streams. one has a parallelism of 5 and the other has 80. the job graph is like this. source 1.1 (5 parallelism). -> union -> source 1.2 (80 parallelism) -> connect -> sink source 2.1 (5 parallelism). -> union -> source 2.2 (80 parallelism) -> 5. Did you see any warns/errors in the logs related to checkpointing and I/O? no error is thrown. 6. What was your checkpoint storage (e.g. S3)? Is the application running in the same data-center (e.g. AWS)? we are using HDFS as the state backend and the checkpoint dir. the application is running in our own data center and in Kubernetes as a standalone job. On Fri, Mar 26, 2021 at 7:31 AM Piotr Nowojski <[hidden email]> wrote:
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
this issue not always reproducible. it happened 2~3 times in our development period of 3 months. On Fri, Mar 26, 2021 at 2:57 PM Sihan You <[hidden email]> wrote:
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Hi Sihan, Thanks for the information. Previously I was not able to reproduce this issue, but after adding a union I think I can see it happening. Best, Piotrek pt., 26 mar 2021 o 22:59 Sihan You <[hidden email]> napisał(a):
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Awesome. Let me know if you need any other information. Our application has a heavy usage on event timer and keyed state. The load is vey heavy. If that matters.
On Mar 29, 2021, 05:50 -0700, Piotr Nowojski <[hidden email]>, wrote:
|
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Hi Sihan,
Unfortunately, we are unable to reproduce the issue so far. Could you please describe in more detail the job graph, in particular what are the downstream operators and whether there is any chaining? Do I understand correctly, that Flink returned back to normal at around 8:00; worked fine for ~3 hours; got stuck again; and then it was restarted? I'm also wondering whether requestBufferBuilderBlocking is just a frequent operation popping up in thread dump. Or do you actually see that Legacy source threads are *stuck* there? Could you please explain how the other metrics are calculated? (PURCHASE KAFKA NUM-SEC, PURCHASE OUTPOOL, PLI PURCHASE JOIN INPOOL). Or do you have rate metrics per source? Regards, Roman On Wed, Mar 31, 2021 at 1:44 AM Sihan You <[hidden email]> wrote: > > Awesome. Let me know if you need any other information. Our application has a heavy usage on event timer and keyed state. The load is vey heavy. If that matters. > On Mar 29, 2021, 05:50 -0700, Piotr Nowojski <[hidden email]>, wrote: > > Hi Sihan, > > Thanks for the information. Previously I was not able to reproduce this issue, but after adding a union I think I can see it happening. > > Best, > Piotrek > > pt., 26 mar 2021 o 22:59 Sihan You <[hidden email]> napisał(a): >> >> this issue not always reproducible. it happened 2~3 times in our development period of 3 months. >> >> On Fri, Mar 26, 2021 at 2:57 PM Sihan You <[hidden email]> wrote: >>> >>> Hi, >>> >>> Thanks for responding. I'm working in a commercial organization so I cannot share the detailed stack with you. I will try to describe the issue as specific as I can. >>> <image.png> >>> above is a more detailed stats of our job. >>> 1. How long did the job run until it got stuck? >>> about 9 hours. >>> 2. How often do you checkpoint or how many checkpoints succeeded? >>> I don't remember the exact number of the successful checkpoints, but there should be around 2. then the checkpoint started to fail because of the timeout. >>> 3. What were the typical checkpoint sizes? How much in-flight data was checkpointed? (A screenshot of the checkpoint tab in the Flink UI would suffice) >>> the first checkpoint is 5T and the second is 578G. >>> 4. Was the parallelism of the whole job 5? How is the topology roughly looking? (e.g., Source -> Map -> Sink?) >>> the source is a union of two source streams. one has a parallelism of 5 and the other has 80. >>> the job graph is like this. >>> source 1.1 (5 parallelism). -> >>> union -> >>> source 1.2 (80 parallelism) -> >>> connect -> sink >>> source 2.1 (5 parallelism). -> >>> union -> >>> source 2.2 (80 parallelism) -> >>> 5. Did you see any warns/errors in the logs related to checkpointing and I/O? >>> no error is thrown. >>> 6. What was your checkpoint storage (e.g. S3)? Is the application running in the same data-center (e.g. AWS)? >>> we are using HDFS as the state backend and the checkpoint dir. >>> the application is running in our own data center and in Kubernetes as a standalone job. >>> >>> On Fri, Mar 26, 2021 at 7:31 AM Piotr Nowojski <[hidden email]> wrote: >>>> >>>> Hi Sihan, >>>> >>>> More importantly, could you create some example job that can reproduce that problem? It can have some fake sources and no business logic, but if you could provide us with something like that, it would allow us to analyse the problem without going back and forth with tens of questions. >>>> >>>> Best, Piotrek >>>> >>>> pt., 26 mar 2021 o 11:40 Arvid Heise <[hidden email]> napisał(a): >>>>> >>>>> Hi Sihan, >>>>> >>>>> thanks for reporting. This looks like a bug to me. I have opened an investigation ticket with the highest priority [1]. >>>>> >>>>> Could you please provide some more context, so we have a chance to reproduce? >>>>> 1. How long did the job run until it got stuck? >>>>> 2. How often do you checkpoint or how many checkpoints succeeded? >>>>> 3. What were the typical checkpoint sizes? How much in-flight data was checkpointed? (A screenshot of the checkpoint tab in the Flink UI would suffice) >>>>> 4. Was the parallelism of the whole job 5? How is the topology roughly looking? (e.g., Source -> Map -> Sink?) >>>>> 5. Did you see any warns/errors in the logs related to checkpointing and I/O? >>>>> 6. What was your checkpoint storage (e.g. S3)? Is the application running in the same data-center (e.g. AWS)? >>>>> >>>>> [1] https://issues.apache.org/jira/browse/FLINK-21992 >>>>> >>>>> On Thu, Mar 25, 2021 at 3:00 AM Sihan You <[hidden email]> wrote: >>>>>> >>>>>> Hi, >>>>>> >>>>>> I keep seeing the following situation where a task is blocked getting a MemorySegment from the pool but the operator is still reporting. >>>>>> >>>>>> I'm completely stumped as to how to debug or what to look at next so any hints/help/advice would be greatly appreciated! >>>>>> >>>>>> The situation is as follows (Flink 1.12.2): >>>>>> <Attachment.tiff> >>>>>> As you can see from 02:00 to 08:00, no records is produced from this purchase source while there still a bunch of records need to be processed from Kafka. And during this period of time. The outPoolUsage is around 0.6 and the downstream operators seems also have the available buffer. We redeployed the job and disabled unaligned checkpoint at around 9 so it becomes normal now. >>>>>> >>>>>> The thread dump we took shows that we are stuck here: >>>>>> >>>>>> "Legacy Source Thread - Source: Kafka Reader - ACCOUNT - kafka-bootstrap-url.com:9443 (1/5)#2" #9250 prio=5 os_prio=0 cpu=5 >>>>>> 9490.62ms elapsed=8399.28s tid=0x00007f0e99c23910 nid=0x2df5 waiting on condition [0x00007f0fa85fe000] >>>>>> java.lang.Thread.State: WAITING (parking) >>>>>> at jdk.internal.misc.Unsafe.park(java.base@11.0.8/Native Method) >>>>>> - parking to wait for <0x00000000ab5527c8> (a java.util.concurrent.CompletableFuture$Signaller) >>>>>> at java.util.concurrent.locks.LockSupport.park(java.base@11.0.8/LockSupport.java:194) >>>>>> at java.util.concurrent.CompletableFuture$Signaller.block(java.base@11.0.8/CompletableFuture.java:1796) >>>>>> at java.util.concurrent.ForkJoinPool.managedBlock(java.base@11.0.8/ForkJoinPool.java:3128) >>>>>> at java.util.concurrent.CompletableFuture.waitingGet(java.base@11.0.8/CompletableFuture.java:1823) >>>>>> at java.util.concurrent.CompletableFuture.get(java.base@11.0.8/CompletableFuture.java:1998) >>>>>> at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestMemorySegmentBlocking(LocalBufferPool.java:319) >>>>>> at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestBufferBuilderBlocking(LocalBufferPool.java:291) >>>>>> at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewBufferBuilderFromPool(BufferWritingResultPartition.java:337) >>>>>> at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewUnicastBufferBuilder(BufferWritingResultPartition.java:313) >>>>>> at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.appendUnicastDataForRecordContinuation(BufferWritingResultPartition.java:257) >>>>>> at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.emitRecord(BufferWritingResultPartition.java:149) >>>>>> at org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit(RecordWriter.java:104) >>>>>> at org.apache.flink.runtime.io.network.api.writer.ChannelSelectorRecordWriter.emit(ChannelSelectorRecordWriter.java:54) >>>>>> at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:101) >>>>>> at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:87) >>>>>> at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:43) >>>>>> at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50) >>>>>> at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28) >>>>>> at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollectWithTimestamp(StreamSourceContexts.java:322) >>>>>> at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collectWithTimestamp(StreamSourceContexts.java:426) >>>>>> - locked <0x00000000aef80e00> (a java.lang.Object) |
Re: Source Operators Stuck in the requestBufferBuilderBlocking
|
|
Hi Sihan, we managed to reproduce it, see [1]. It will be fixed in the next 1.12 and the upcoming 1.13 release. On Tue, Apr 6, 2021 at 8:45 PM Roman Khachatryan <[hidden email]> wrote: Hi Sihan, |
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |