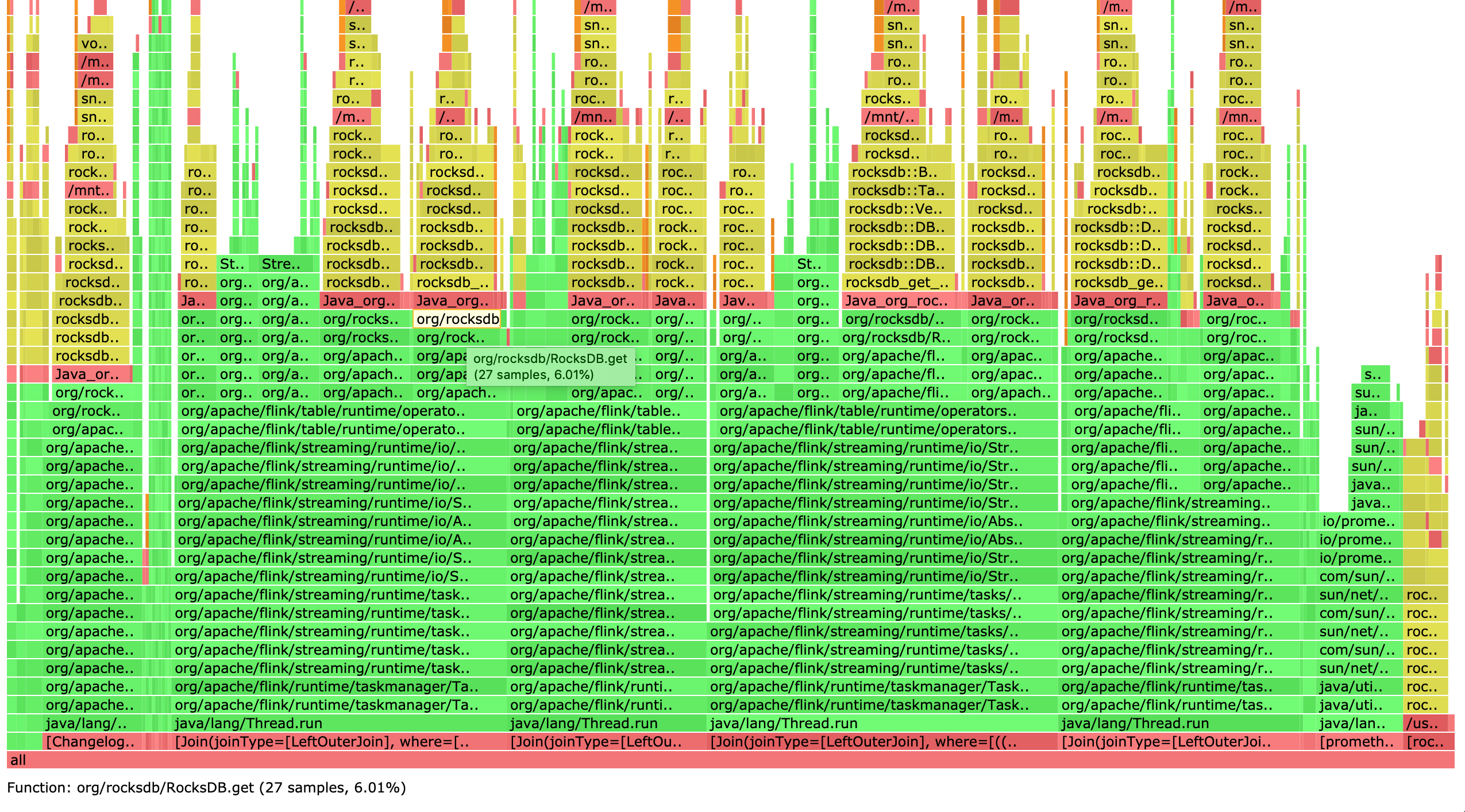
Hi team,
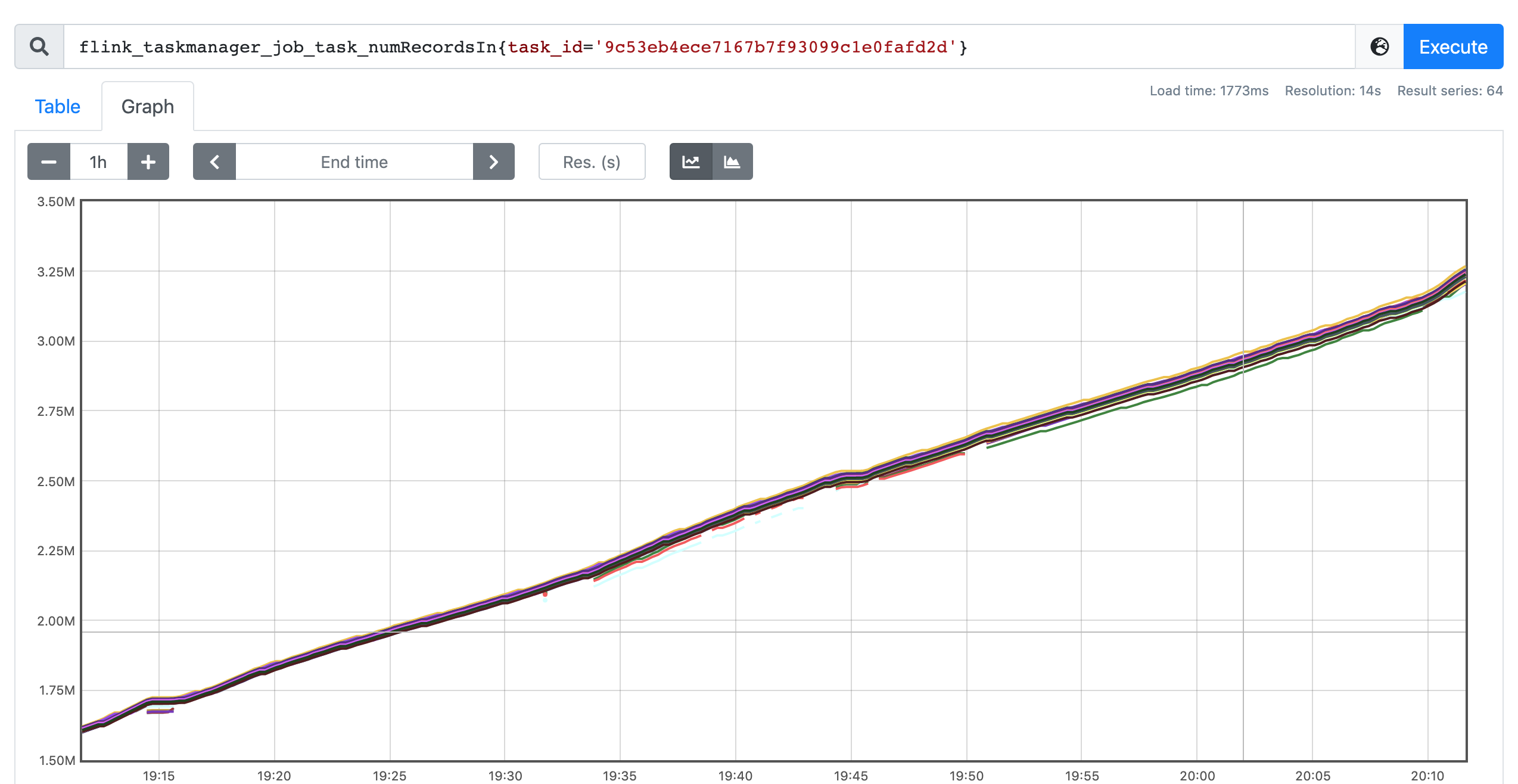
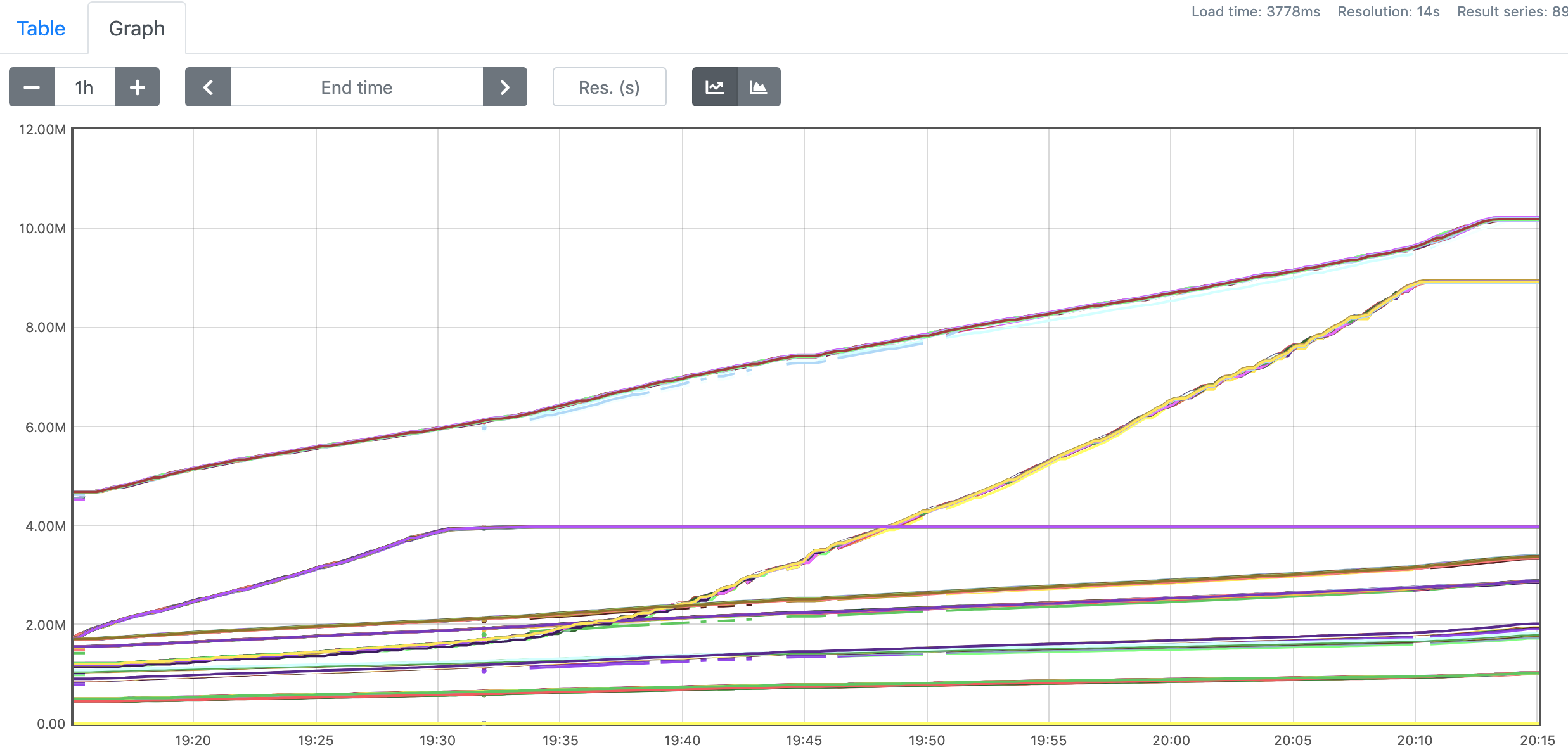
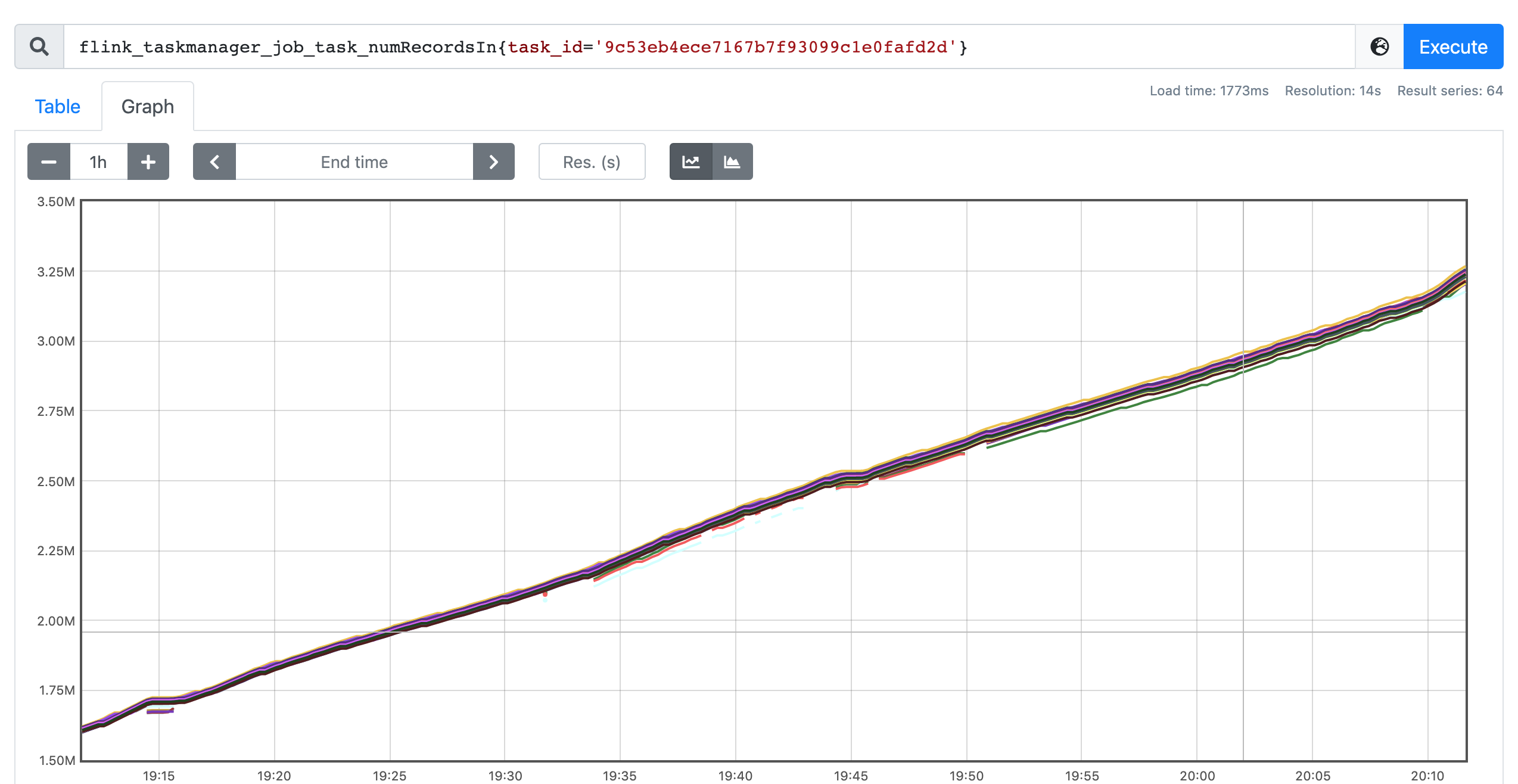
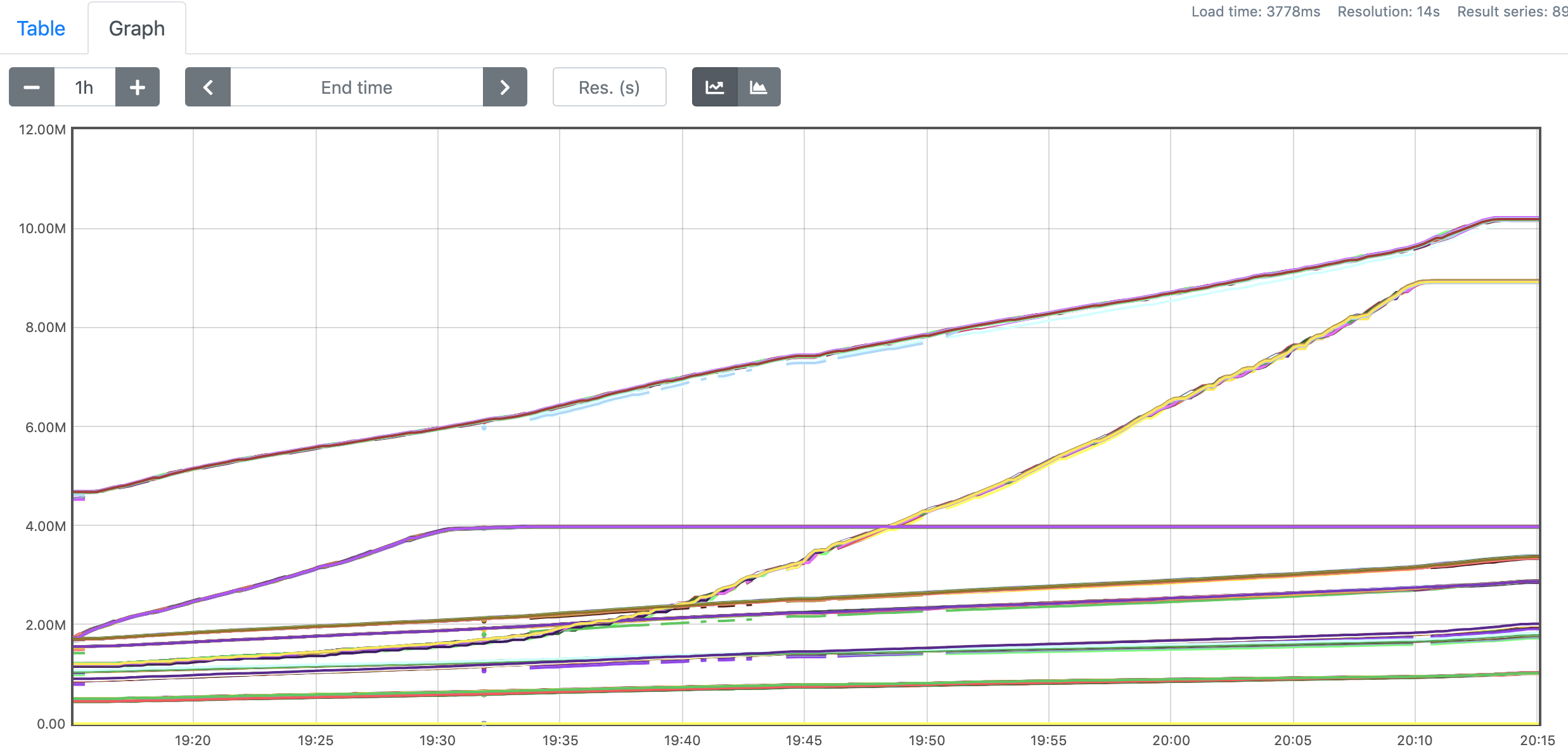
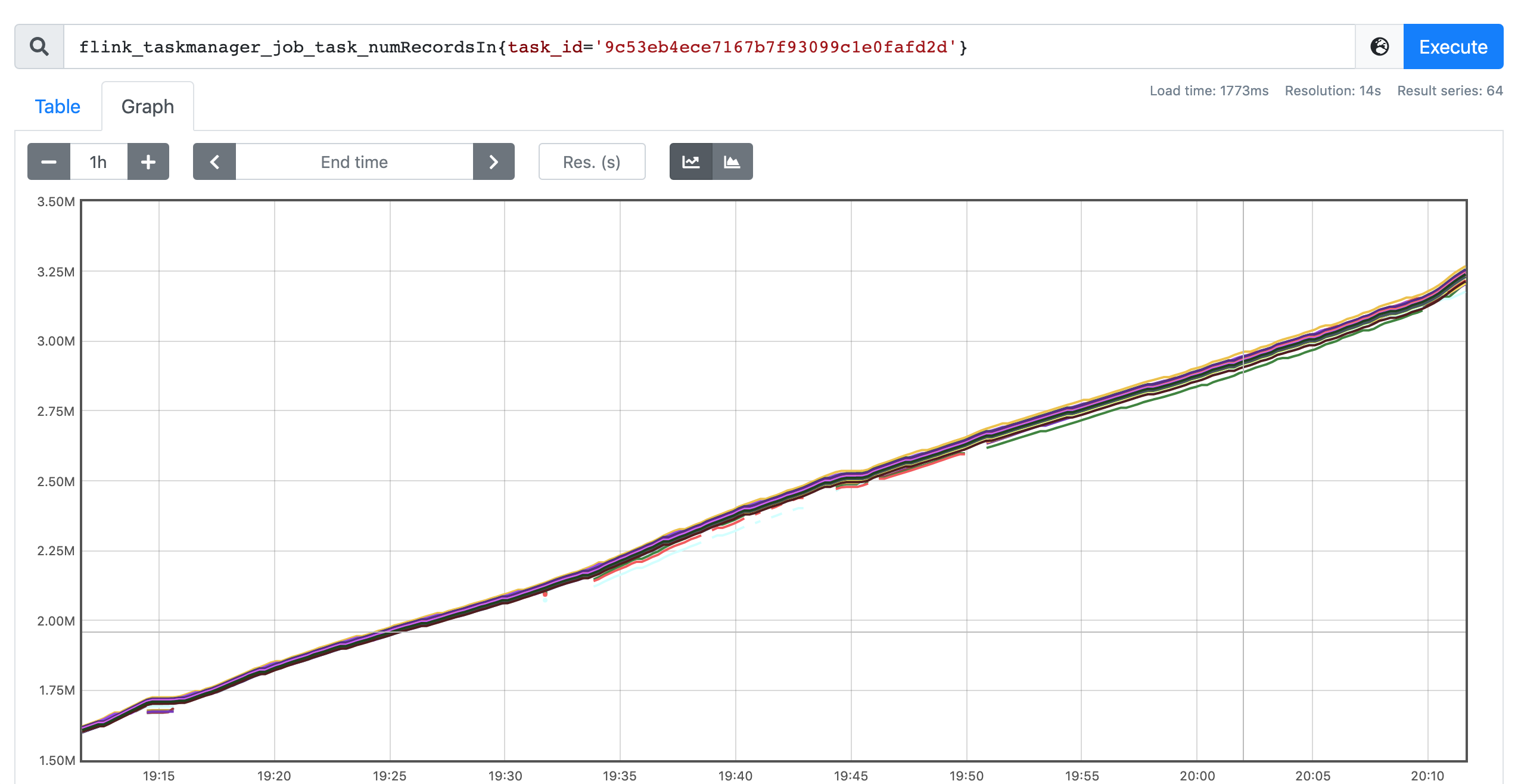
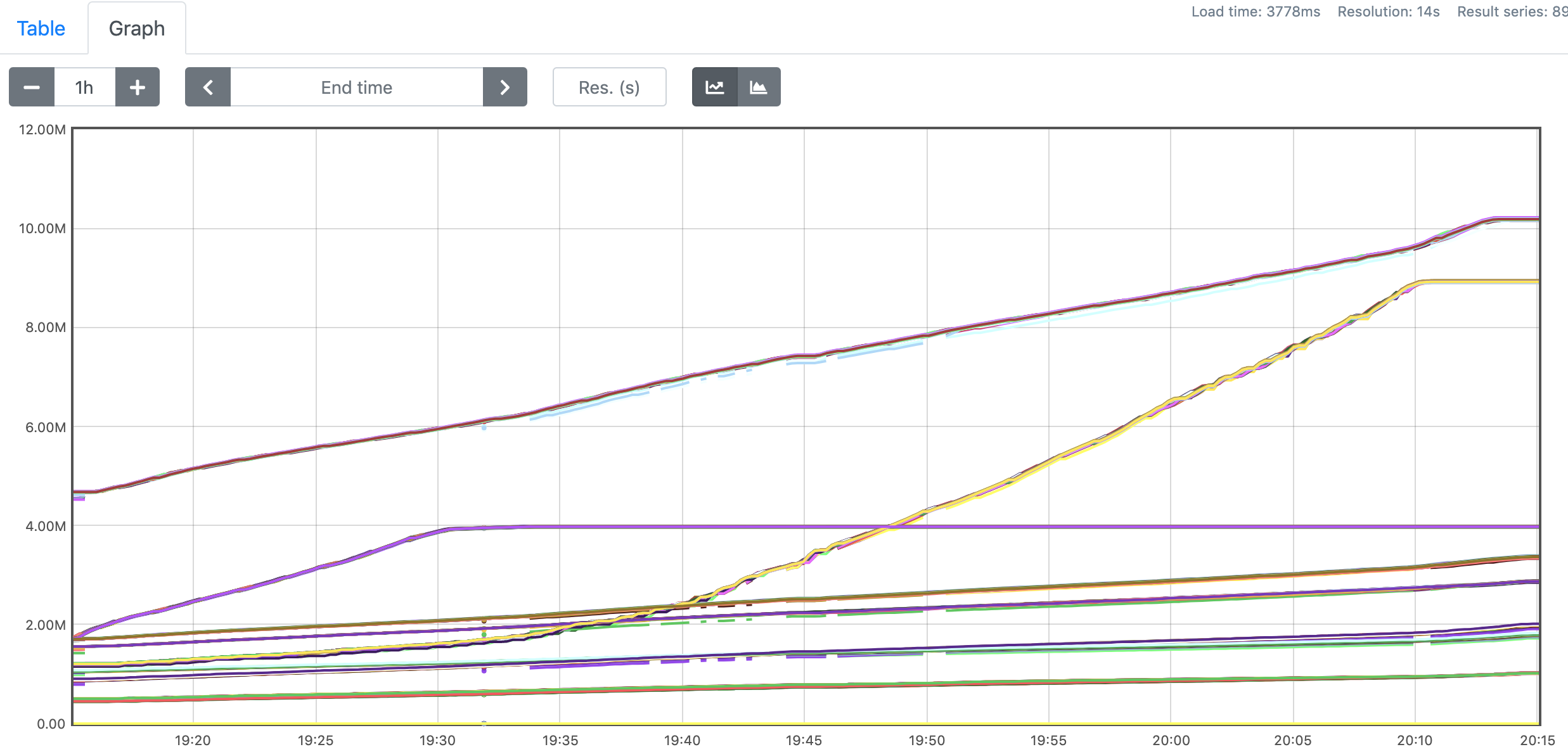
We're using multiple joins to generate the dynamic view from Kafka stream. There are no data skew in our data input, and that can be verified by number of consumed records for all subtasks for one operator, they fit close as shown in the figure below. This is the metrics figure for the last operator and it's similar trend for other operators.
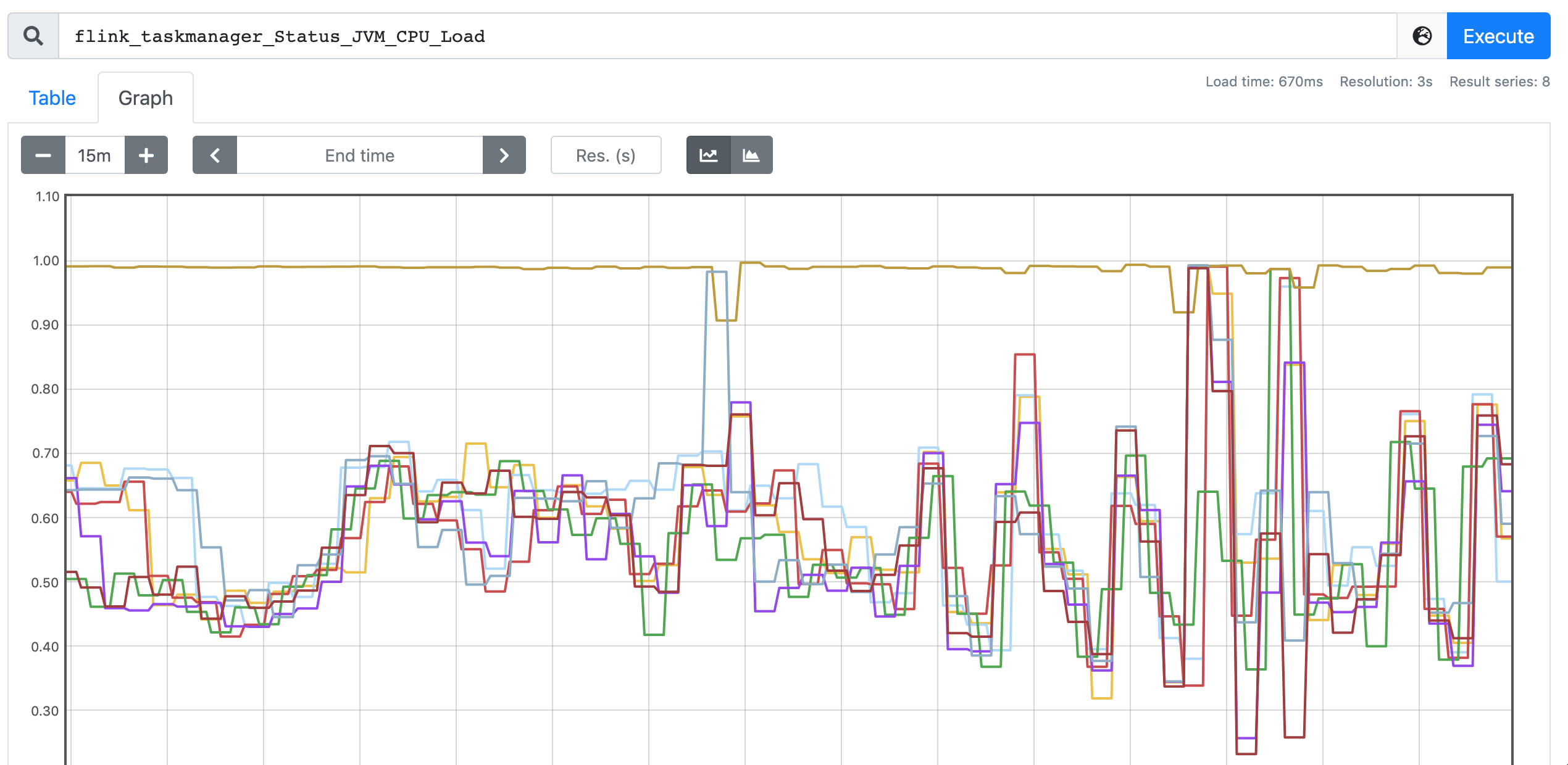
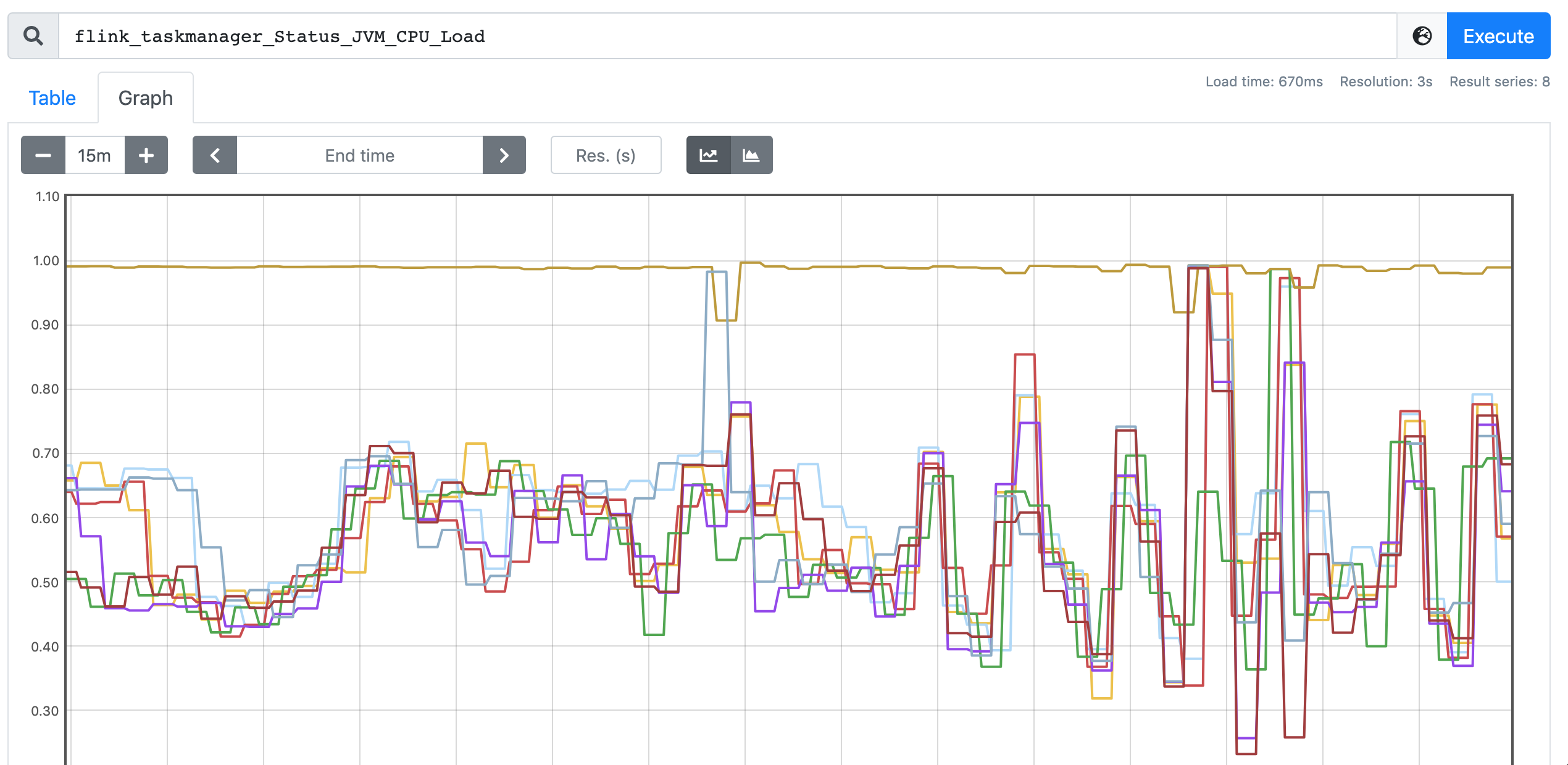
While we faced a issue of skewed CPU utilization as shown in Figure-3. This does not happen everytime with the parallelism settings. Is there any guidance for further analysis on this?
Figure-1. number of consumed records for the last operator.
Figure-2. number of consumed records for all operators.
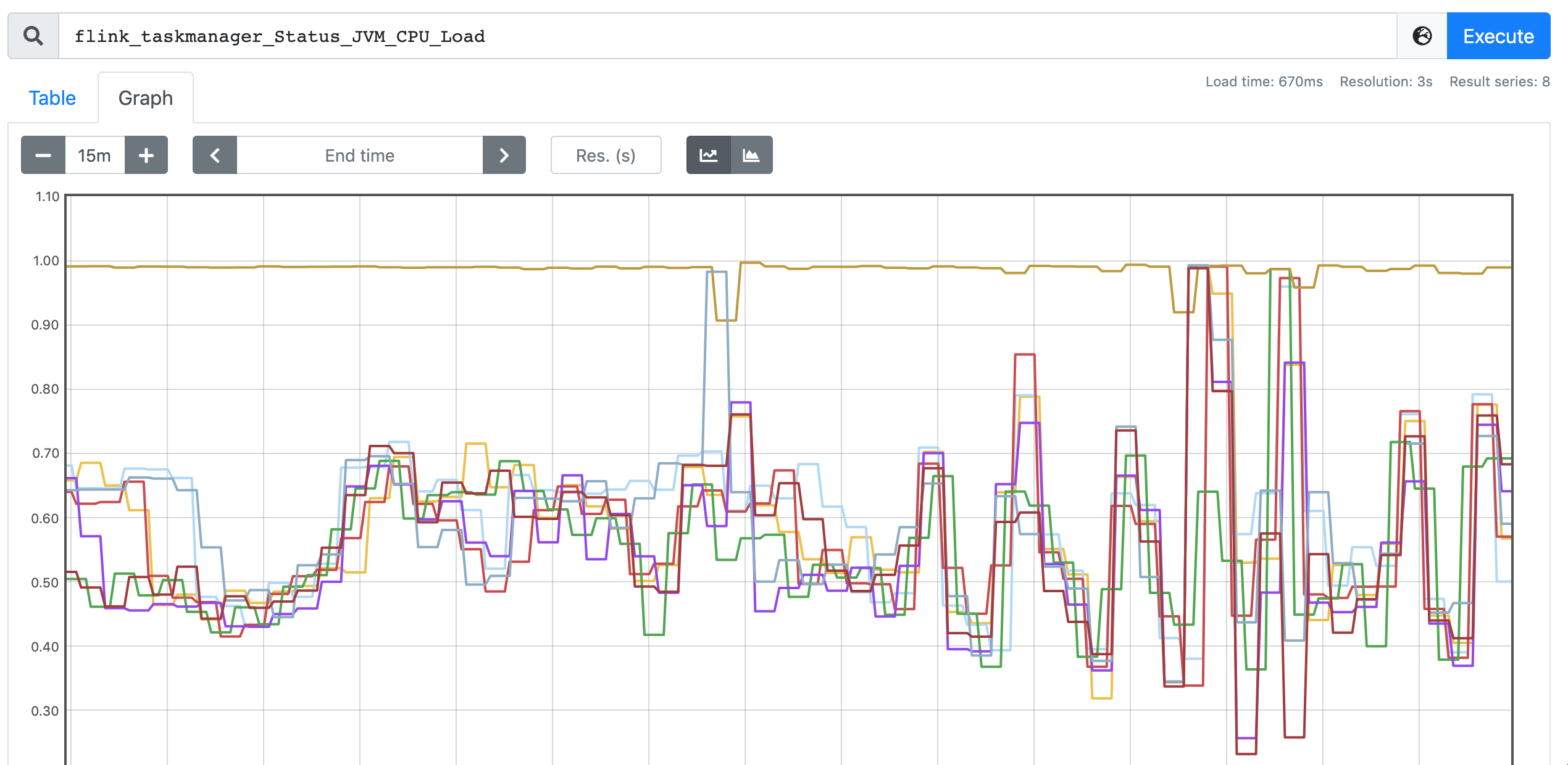
Figure-3. Skewed CPU utilization.
--