Savepoint memory overhead


|
Hi.
I would like to know if there are any guidelines/recommendations for the memory overhead we need to calculate for when doing savepoint to s3. We use RockDb state backend. We run our job on relative small task managers and we can see we get memory problems if the state size for each task manager get "big" (we haven't found the rule of thumbs yet) and we can remove the problem if we reduce the state size, or increase parallelism and jobs with none or small state don't have any problems. So I see a relation between between allocated memory to a task manager and the state it can handle. So do anyone have any recommendations/ base practices for this and can someone explain why savepoint requires memory. Thanks In advance Lasse Nedergaard |
|
|
Hi Lasse
Which version of Flink did you use? Before Flink-1.10, there might exist memory problem when RocksDB executes savepoint with write batch[1].
Best
Yun Tang
From: Lasse Nedergaard <[hidden email]>
Sent: Wednesday, April 29, 2020 21:17 To: user <[hidden email]> Subject: Savepoint memory overhead Hi.
I would like to know if there are any guidelines/recommendations for the memory overhead we need to calculate for when doing savepoint to s3. We use RockDb state backend.
We run our job on relative small task managers and we can see we get memory problems if the state size for each task manager get "big" (we haven't found the rule of thumbs yet) and we can remove the problem if we reduce the state size, or increase parallelism
and jobs with none or small state don't have any problems.
So I see a relation between between allocated memory to a task manager and the state it can handle.
So do anyone have any recommendations/ base practices for this and can someone explain why savepoint requires memory.
Thanks
In advance
Lasse Nedergaard
|
Re: Savepoint memory overhead
|
|
We using Flink 1.10 running on Mesos.
Med venlig hilsen / Best regards Lasse Nedergaard Den 30. apr. 2020 kl. 04.53 skrev Yun Tang <[hidden email]>:
|
|
|
Hi Lasse
Would you please give more details?
Best
Yun Tang
From: Lasse Nedergaard <[hidden email]>
Sent: Thursday, April 30, 2020 12:39 To: Yun Tang <[hidden email]> Cc: user <[hidden email]> Subject: Re: Savepoint memory overhead We using Flink 1.10 running on Mesos.
Med venlig hilsen / Best regards
Lasse Nedergaard
Den 30. apr. 2020 kl. 04.53 skrev Yun Tang <[hidden email]>:
|
Re: Savepoint memory overhead
|
|
Hi
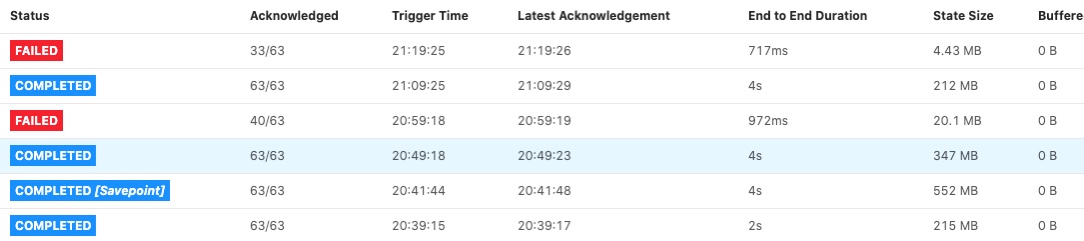
Thanks for the reply. The link you provide make us thinking of some old rocksdb cfg. We was still using and it could cause our container killing problems so I will do a test without specific rocksdb cfg. But we also see RocksDbExceptions “cannot allocate memory” while appending to a file. And that make me think the managed men is to small for the state size. Please see below for a specific job with parallelism 4 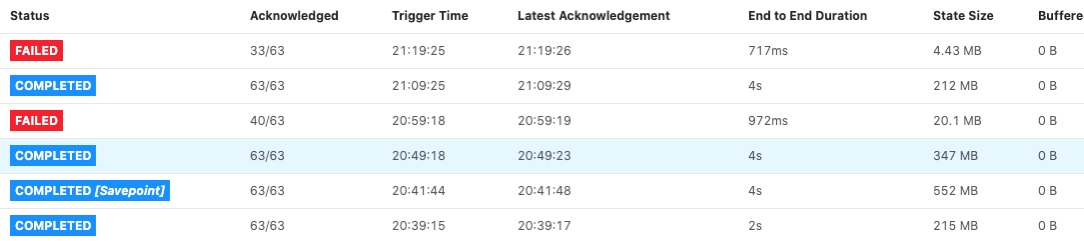 So task managers as we have can’t handle infinite size so I was looking for the understanding and guidelines for getting the config right in relation to the state size. For now we run in session mode and the setting is shared between all job and we have job that don’t require many resources therefore the low settings 1. Jvm heap size 734 mb Flink managed men 690 mb 1 slot for each task manager. 2. By a mistake we had some rocksdb Settings from prev. Version. I have removed this configuration and will test again. 3. For jobs with restart and failed checkpoints/savepoints there is a common trend that they have larger state than without problems. We have on some of the failing jobs reduced our retention so our state got smaller and then they run ok. We do tests where we increase parallelism and they’ve reduce the state size for each task manager and then they run ok. 4. We don’t use windows functions and the jobs use standard value, list and map state. Med venlig hilsen / Best regards Lasse Nedergaard Den 30. apr. 2020 kl. 08.55 skrev Yun Tang <[hidden email]>:
|
|
|
Hi From the given fig, seems that the end-to-end duration of the two failed checkpoint is small(it is not timeout due to some reason), could you please check why did they fail? Maybe you can find something in jm log such as "Decline checkpoint {} by task {} of job {} at {}." then you can go to the tm log to find out the root cause which caused the checkpoint failed. Best, Congxian Lasse Nedergaard <[hidden email]> 于2020年4月30日周四 下午4:37写道:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |