Running and Maintaining Multiple Jobs

Running and Maintaining Multiple Jobs

|
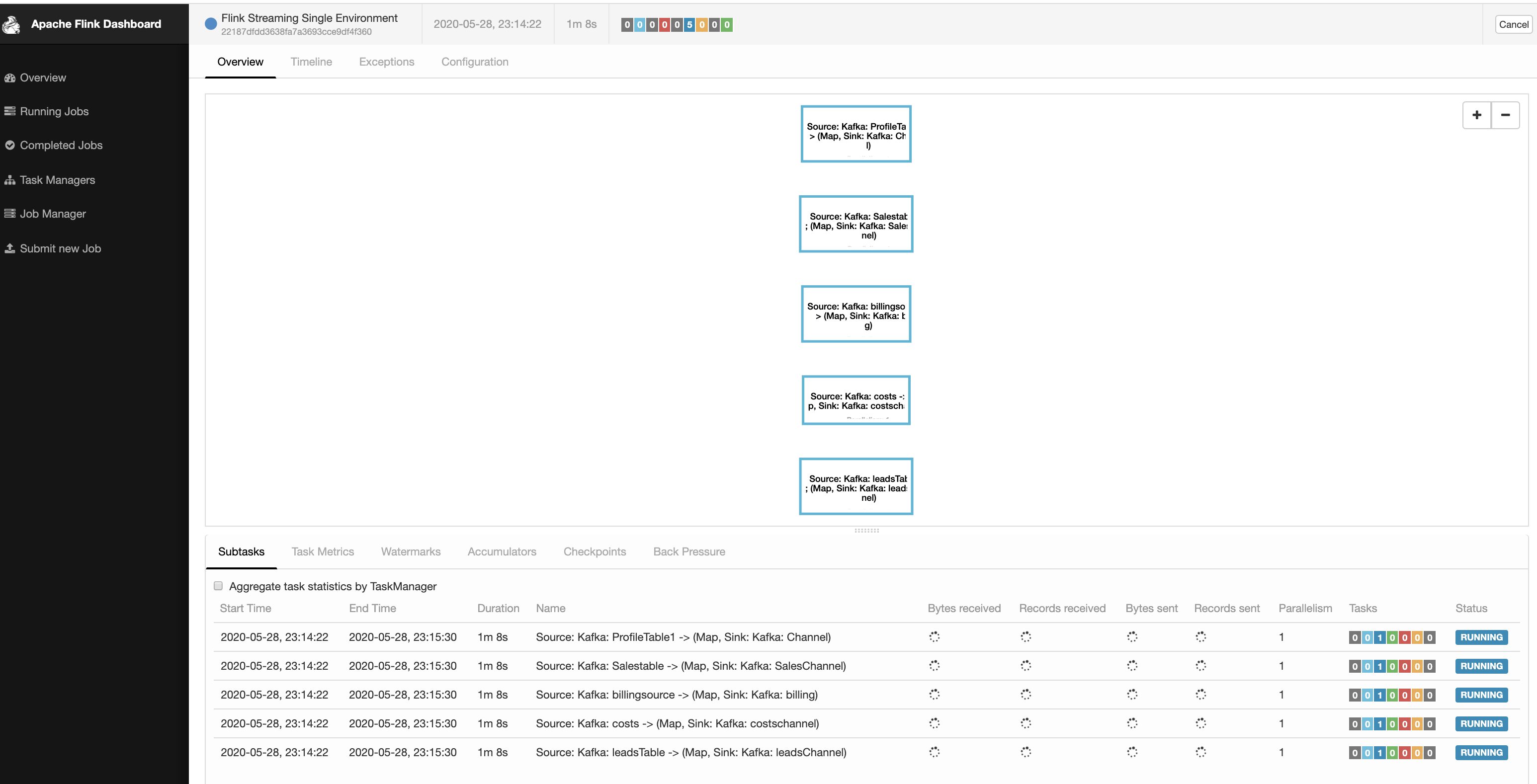
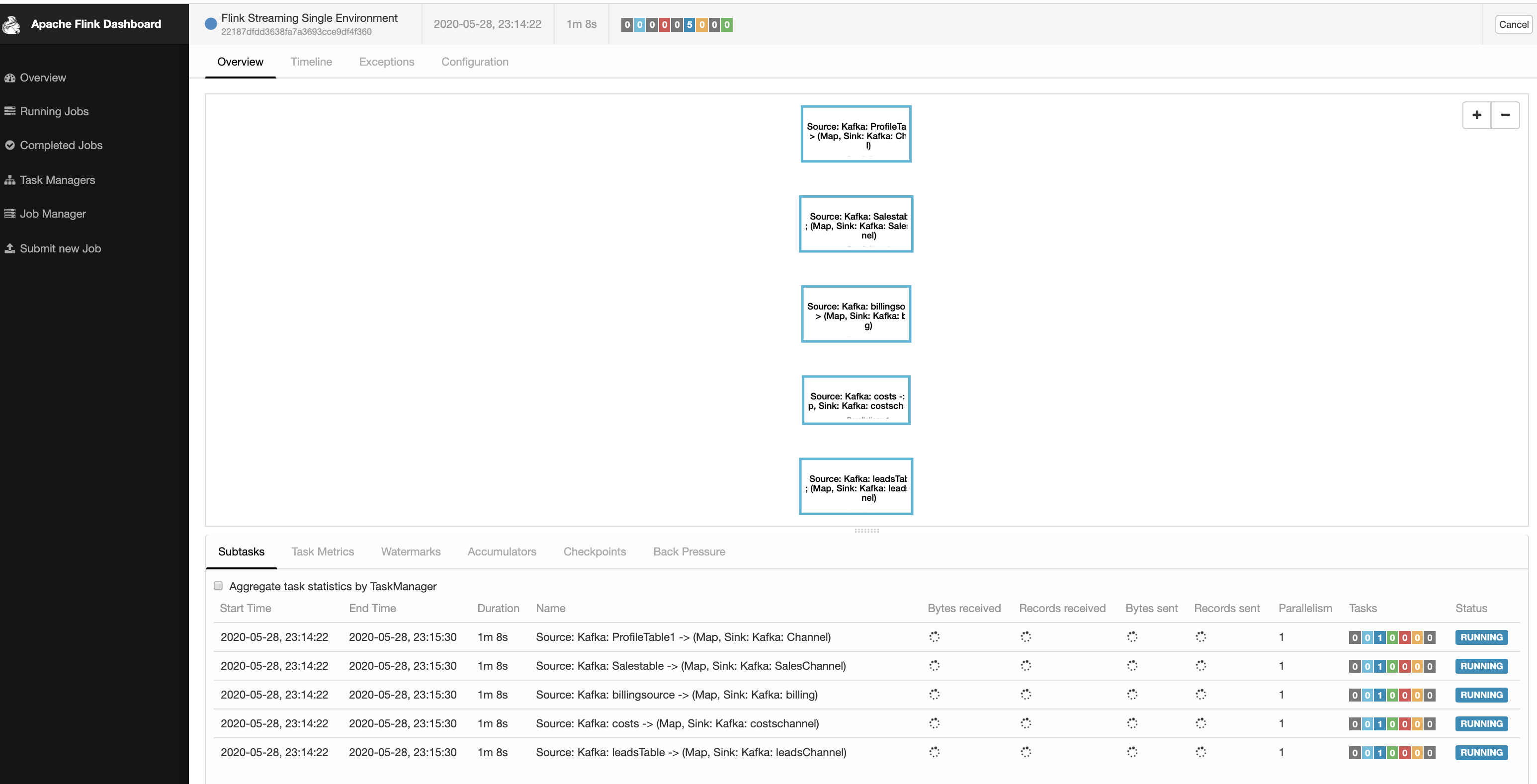
Hi, I have a list of jobs that need to be run via flink. For PoC we are implementing via JSON configuration file. Sample JSON file { "registryJobs": [ { "inputTopic": "ProfileTable1", "outputTopic": "Channel" }, { "inputTopic": "Salestable", "outputTopic": "SalesChannel" }, { "inputTopic": "billingsource", "outputTopic": "billing" }, { "inputTopic": "costs", "outputTopic": "costschannel" }, { "inputTopic": "leadsTable", "outputTopic": "leadsChannel" }, ] } But in Long run we do want to have this detail in a RDBMS. There are many other properties for Job such as transformation, filter , rules which would be captured in DB via UI. Flink Supports Single Execution Environment. I ended up writing JobGenerator Module which reads from this JSON and creates Jobs. public static void Generate Jobs(Registry job, StreamExecutionEnvironment env) { This created 5 tasks in a single Job and it is seen this way. 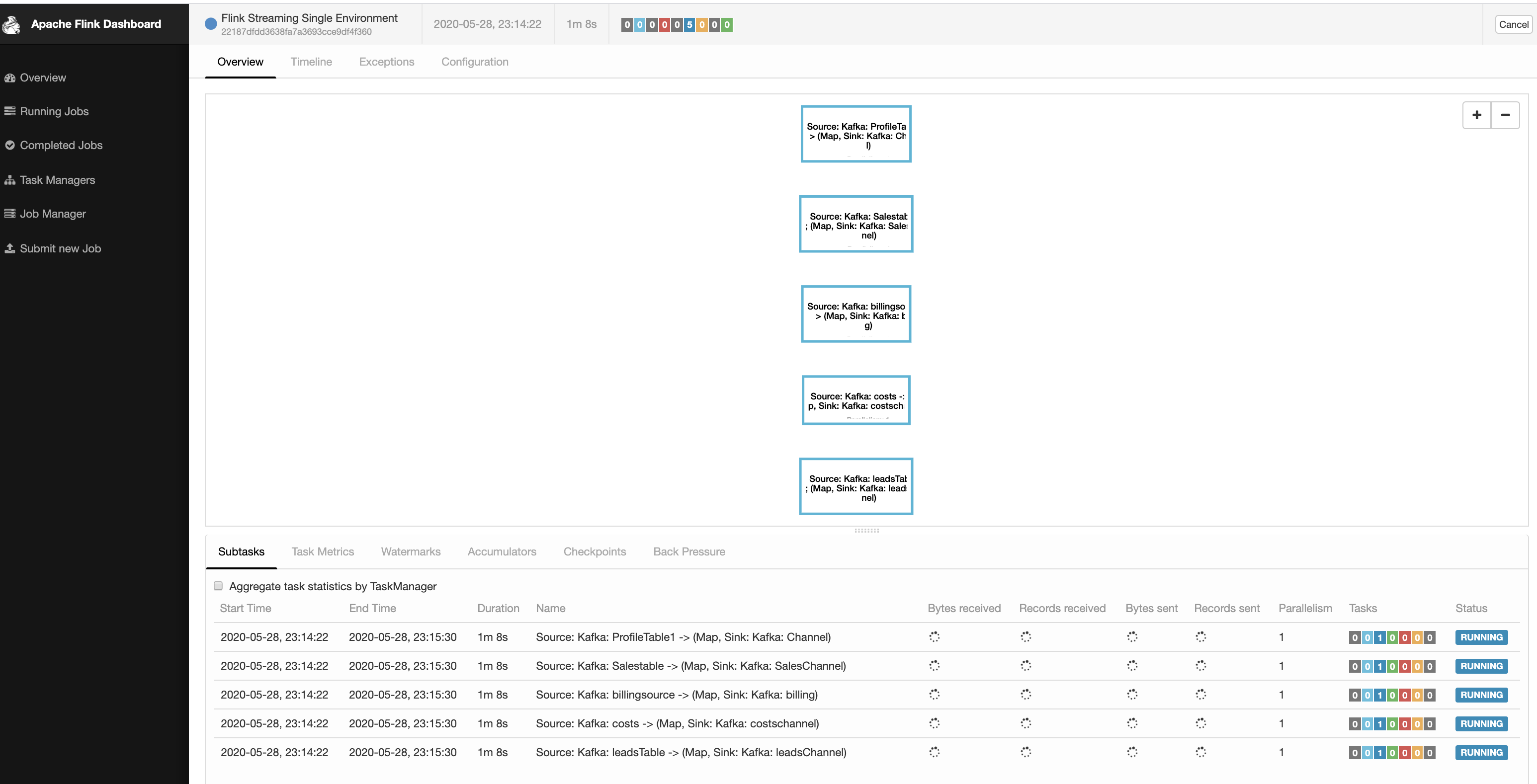 Questions 1) Is this a good way to design ? We might end up having 500 - 1000 such tasks in say 1 year down the lane. Or there is another way possible ? 2) We cannot afford downtime in our system. Say 5 tasks are pushed to production. Say we need to add / update tasks later should we restart the cluster with the new job and JAR ? 3) Now we have the job registry in files. Is it possible to read from the DB directly and create the Jobs (DAG) dynamically without restarting it ? Thanks, Prasanna. |
Re: Running and Maintaining Multiple Jobs
|
|
Hi, I also looked at this link. This says my approach is not good. Wanted to hear more on the same from the community. Prasanna. On Thu, May 28, 2020 at 11:22 PM Prasanna kumar <[hidden email]> wrote:
|
|
|
Hi Prasanna
At year of 2018, Flink can only restart all tasks to recover the job. That's why you would found the answer that multiple jobs might be good. However, Flink supports to restart only affected pipeline instead of the whole job, a.k.a "region failover" after Flink-1.9,
and make this failover strategy as default after Flink-1.10 [1].
In a nutshell, I think multiple pipelines could be acceptable now.
Best
Yun Tang
From: Prasanna kumar <[hidden email]>
Sent: Friday, May 29, 2020 1:59 To: user <[hidden email]> Subject: Re: Running and Maintaining Multiple Jobs Hi,
I also looked at this link. This says my approach is not good. Wanted to hear more on the same from the community. Prasanna. On Thu, May 28, 2020 at 11:22 PM Prasanna kumar <[hidden email]> wrote:
|
Re: Running and Maintaining Multiple Jobs
|
|
Thanks Yun for your reply. Your thoughts on the following too? 2) We cannot afford downtime in our system. Say 5 tasks are pushed to production. Say we need to add / update tasks later should we restart the cluster with the new job and JAR ? 3) Now we have the job registry in files. Is it possible to read from the DB directly and create the Jobs (DAG) dynamically without restarting it ? Prasanna. On Fri 29 May, 2020, 08:04 Yun Tang, <[hidden email]> wrote:
|
|
|
Hi Prasanna
As far as I know, Flink does not allow to submit new jobgraph without restarting it, and I actually not understand what's your 3rd question meaning.
From: Prasanna kumar <[hidden email]>
Sent: Friday, May 29, 2020 11:18 To: Yun Tang <[hidden email]> Cc: user <[hidden email]> Subject: Re: Running and Maintaining Multiple Jobs Thanks Yun for your reply.
Your thoughts on the following too?
2) We cannot afford downtime in our system. Say 5 tasks are pushed to production. Say we need to add / update tasks later should we restart the cluster with the new job and JAR ?
3) Now we have the job registry in files. Is it possible to read from the DB directly and create the Jobs (DAG) dynamically without restarting it ?
Prasanna.
On Fri 29 May, 2020, 08:04 Yun Tang, <[hidden email]> wrote:
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |