Hi Till Rohrmann,
I was running flink 1.5.5, and I use prometheus to collect metrics to check latency of my jobs.
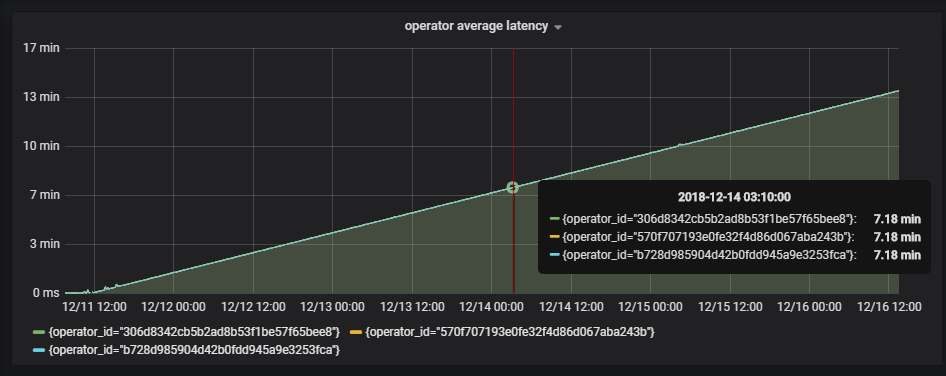
But sometimes I observerd that the operator's latency metrics continues to increase in my job.
The operator's latency time is increased by approximately 2.7 minutes per day (please see the attached screenshots)
my job's logic is simple,just distribute data from kafkaSource to bucketingSink.
so I check the consumer offsets in kafka for consumer group, I also check the latest data in hdfs . in fact, there is no serious latency in my job.
I notice that the statistical method of latency is currentTimeMillis minus LatencyMarker's markedTime.
but LatencyMarker's timestamp come from RepeatedTriggerTask's nextTimestamp which compute timestamp by plus a period(default value is 2s before v1.5.5),the nextTimestamp will be delay when JVM GC or linux preemptive scheduling happened. as time increases,the nextTimestamp is much later than the current time ( I had verify this result via the JVM Heap Dump).
we can avoid the above situation by directly using linux's NTP to guarantee accuracy,not need to compute timestamp by process.
I'm not very familiar with SystemProcessingTimeService. Is there some detail I have not think about?