Re: Flink 1.10.0 failover


|
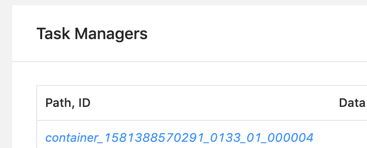
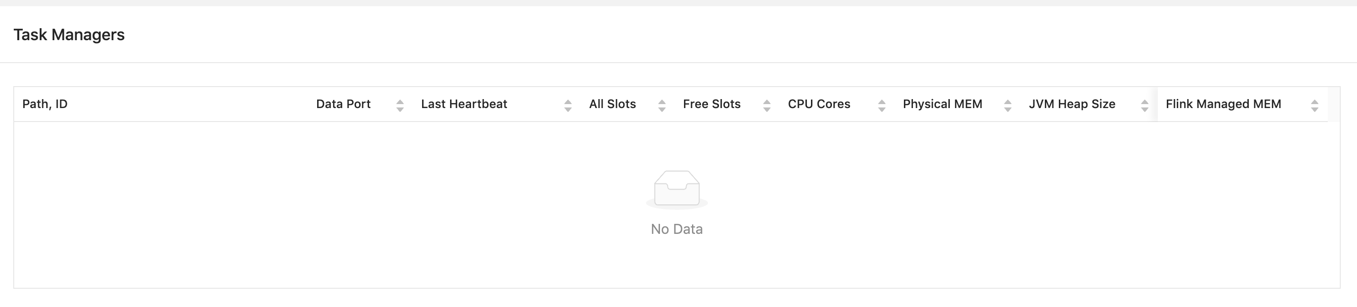
Thank you for your reply. I forget providing some information. I use 'run -m yarn-cluster’ to start my job, which means ‘run a single flink job on yarn’. after one minute, the job throw exception: java.util.concurrent.TimeoutException: The heartbeat of TaskManager with id container_1581388570291_0133_01_000003 timed out. First, the job start with two taskManager: org.apache.flink.yarn.YarnResourceManager - Registering TaskManager with ResourceID container_1581388570291_0133_01_000003 (xxx.xxx.xxx.xxx:38211) org.apache.flink.yarn.YarnResourceManager - Registering TaskManager with ResourceID container_1581388570291_0133_01_000002 (xxx.xxx.xxx.xxx:33715) Then, 003 timeout, and throw with exception: org.apache.flink.yarn.YarnResourceManager - The heartbeat of TaskManager with id container_1581388570291_0133_01_000003 timed out. org.apache.flink.yarn.YarnResourceManager - Closing TaskExecutor connection container_1581388570291_0133_01_000003 because: The heartbeat of TaskManager with id container_1581388570291_0133_01_000003 timed out. Switch RUNNING TO CANCELING, Swith CANCELING To CANCELED. After 10 Seconds(I used fixedDelayRestart), Switch Restarting TO RUNNING. switched from CREATED to SCHEDULED. Requesting new slot [SlotRequestId{c6c137acf7ef9fd639157f0e9495fe42}] and profile ResourceProfile{UNKNOWN} from resource manager. Requesting new TaskExecutor container with resources <memory:12288, vCores:3>. Number pending requests 1. Requesting new TaskExecutor container with resources <memory:12288, vCores:3>. Number pending requests 2. The heartbeat of TaskManager with id container_1581388570291_0133_01_000002 timed out. Closing TaskExecutor connection container_1581388570291_0133_01_000002 because: The heartbeat of TaskManager with id container_1581388570291_0133_01_000002 timed out. org.apache.flink.yarn.YarnResourceManager - Received 1 containers with 2 pending container requests. org.apache.flink.yarn.YarnResourceManager - Removing container request Capability[<memory:12288, vCores:3>]Priority[1]. Pending container requests 1. org.apache.flink.yarn.YarnResourceManager - TaskExecutor container_1581388570291_0133_01_000004 will be started org.apache.flink.yarn.YarnResourceManager - Registering TaskManager with ResourceID container_1581388570291_0133_01_000004 (xxx.xxx.xxx.xxx:40463) akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused:xxx.xxx.xxx.xxx:33715 org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate the required slot within slot request timeout. Please make sure that the cluster has enough resources. And it restart again. switched from SCHEDULED to CANCELING. switched from CANCELING to CANCELED. 10 Seconds later, switched from CREATED to SCHEDULED. akka.remote.transport.netty.NettyTransport - Remote connection to [null] failed with java.net.ConnectException: Connection refused: (xxx.xxx.xxx.xxx:33715) the port 33715 is container_1581388570291_0133_01_000002, it was closed already. then org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate the required slot within slot request timeout. Please make sure that the cluster has enough resources. 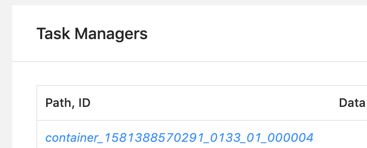 10 seconds later, the third times restart, it only report NoResourceAvailableException, and nothing about 33715. Now, the job only have one task manager 004, but yarn resource has nothing left. last email has no task manager and no resource. I don’t know what make this happen. there is enough resource if all old taskmanager was released, sometimes the job can create one, sometimes none. this never happen on 1.8.2, i use same cluster and job, just different flink version. the job may fail and auto-recovery. but in 1.10.0, it seems yarn miss some taskmanager fail, and not release resource, so the new one can’t be created. What’s more should i do? Thanks a lot. 原始邮件 发件人: Zhu Zhu<[hidden email]> 收件人: seeksst<[hidden email]> 抄送: user<[hidden email]> 发送时间: 2020年4月26日(周日) 11:52 主题: Re: Flink 1.10.0 failover Sorry I did not quite understand the problem. Do you mean a failed job does not release resources to yarn? - if so, is the job in restarting process? A job in recovery will reuse the slots so they will not be release. Or a failed job cannot acquire slots when it is restarted in auto-recovery? - if so, normally the job should be in a loop like (restarting tasks -> allocating slots -> failed due to not be able to acquire enough slots -> restarting task -> ...). Would you check whether the job is in such a loop? Or the job cannot allocate enough slots even if the cluster has enough resource? Thanks, Zhu Zhu seeksst <[hidden email]> 于2020年4月26日周日 上午11:21写道:
|
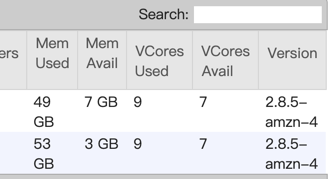
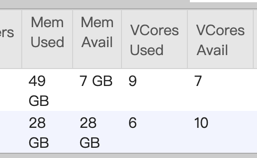
|
|
Seems something bad happened in the task managers and led to heartbeat timeouts. These TMs were not released by flink but lost connections with the master node. I think you need to check the TM log to see what happens there. Thanks, Zhu Zhu seeksst <[hidden email]> 于2020年4月26日周日 下午2:13写道:
|
|
|
In reply to this post by seeksst
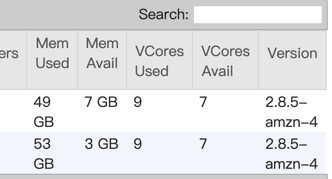
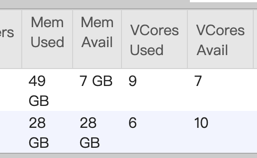
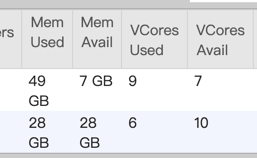
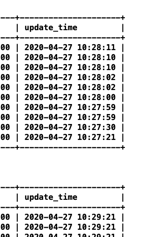
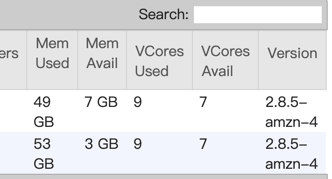
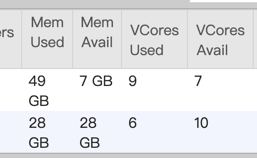
I check the taskmanager log, and find some information in taskmanager.err: Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main-SendThread(xxx.xxx.xxx.xxx:xx) org.apache.flink.runtime.taskexecutor.TaskExecutor - The heartbeat of ResourceManager with id 7a0487f6e6eedaa78f8170172dd1a9c9 timed out org.apache.flink.runtime.taskexecutor.TaskExecutor - Close ResourceManager connection 7a0487f6e6eedaa78f8170172dd1a9c9. I check gc log and find many full gc:  you can see 2711 FGC. It looks like full gc causes timeout. This is not a normal thing, the task throw OutOfMemoryError and program is still running. 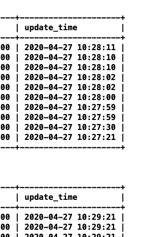 you can see update_time, it means job still running. But jobmanager lost connection and request new slot, if cluster has enough memory, will a new taskmanager be created? if will, This is a very bad thing. you think job is normal, but there are more taskmanagers not under controller. If not, i don’t think job will exec checkpoint, and more dirty data will be sinked. How to avoid this happen? Any advice is helpful. Thanks. 原始邮件 发件人: Zhu Zhu<[hidden email]> 收件人: seeksst<[hidden email]> 抄送: user<[hidden email]> 发送时间: 2020年4月26日(周日) 15:16 主题: Re: Flink 1.10.0 failover Seems something bad happened in the task managers and led to heartbeat timeouts. These TMs were not released by flink but lost connections with the master node. I think you need to check the TM log to see what happens there. Thanks, Zhu Zhu seeksst <[hidden email]> 于2020年4月26日周日 下午2:13写道:
|
|
|
I think you need to increase the TM heap to avoid OOM and frequent FGC. The heartbeat timeout happened because the TM process is keeping FGC and failed to respond to heartbeat from RM. It's weird that the job was failed but the task in the taskmanager was not. It would be helpful if you can share the JM log on why the job was failed and the TM log around that time. Thanks, Zhu Zhu seeksst <[hidden email]> 于2020年4月27日周一 上午10:38写道:
|

| Free forum by Nabble | Edit this page |