Re: Checkpointing with RocksDB as statebackend

Re: Checkpointing with RocksDB as statebackend

|
Hi,
I was able to come up with a custom build of RocksDB yesterday that seems to fix the problems. I still have to build the native code for different platforms and then test it. I cannot make promises about the 1.2.1 release, but I would be optimistic that this will make it in. Best, Stefan
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Stephan, I see that the RocksDb issue is solved by having a separate FRocksDB dependency. I have added this dependency as discussed on the JIRA. Is it the only thing that we have to do or we have to change the code for setting RocksDB state backend as well ? Regards, Vinay Patil On Tue, Mar 28, 2017 at 1:20 PM, Stefan Richter [via Apache Flink User Mailing List archive.] <[hidden email]> wrote: Hi, |
Re: Checkpointing with RocksDB as statebackend
|
|
In reply to this post by Stefan Richter
Hi Stephan, I tested the pipeline with the FRocksDB dependency (with SSD_OPTIMIZED option), none of the checkpoints were failed. For checkpointing 10GB of state it took 45secs which is better than the previous results. Let me know if there are any other configurations which will help to get better results. Regards, Vinay Patil On Thu, May 4, 2017 at 10:05 PM, Vinay Patil <[hidden email]> wrote:
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Stephan, I have upgraded to Flink 1.3.0 to test RocksDB with incremental checkpointing (PredefinedOptions used is FLASH_SSD_OPTIMIZED) I am currently creating a YARN session and running the job on EMR having r3.4xlarge instances (122GB of memory), I have observed that it is utilizing almost all memory. This was not happening with previous version ; maximum 30GB was getting utilized. Because of this issue the job manager was killed and the job failed. Is there any other configurations I have to do ? P.S I am currently using FRocksDB Regards, Vinay Patil On Fri, May 5, 2017 at 1:01 PM, Vinay Patil <[hidden email]> wrote:
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Stephan,
I am observing similar issue with Flink 1.2.1 The memory is continuously increasing and data is not getting flushed to disk. I have attached the snapshot for reference. Also the data processed till now is only 17GB and above 120GB memory is getting used. Is there any change wrt RocksDB configurations 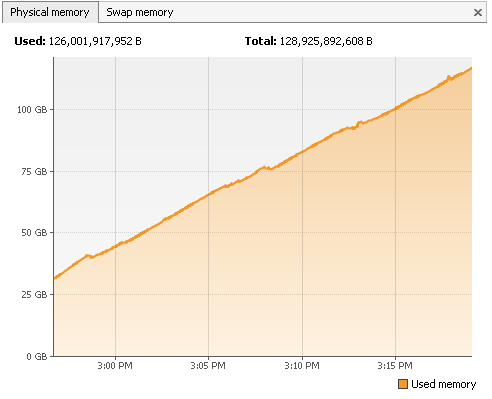 Regards, Vinay Patil |
Re: Checkpointing with RocksDB as statebackend
|
|
Hi,
Just a quick question, because I’m not sure whether this came up in the discussion so far: what kind of windows are you using? Processing time/event time? Sliding Windows/Tumbling Windows? Allowed lateness? How is the watermark behaving? Also, the latest memory usage graph you sent, is that heap memory or off-heap memory or both? Best, Aljoscha > On 27. Jun 2017, at 11:45, vinay patil <[hidden email]> wrote: > > Hi Stephan, > > I am observing similar issue with Flink 1.2.1 > > The memory is continuously increasing and data is not getting flushed to > disk. > > I have attached the snapshot for reference. > > Also the data processed till now is only 17GB and above 120GB memory is > getting used. > > Is there any change wrt RocksDB configurations > > <http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/file/n14013/TM_Memory_Usage.png> > > Regards, > Vinay Patil > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Re-Checkpointing-with-RocksDB-as-statebackend-tp11752p14013.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Aljoscha,
I am using event Time based tumbling window wherein the allowedLateness is kept to Long.MAX_VALUE and I have custom trigger which is similar to 1.0.3 where Flink was not discarding late elements (we have discussed this scenario before). The watermark is working correctly because I have validated the records earlier. I was doubtful that the RocksDB statebackend is not set , but in the logs I can clearly see that RocksDB is initialized successfully, so that should not be an issue. Even I have not changed any major code from the last performance test I had done. The snapshot I had attached is of Off-heap memory, I have only assigned 12GB heap memory per TM Regards, Vinay Patil On Wed, Jun 28, 2017 at 8:43 PM, Aljoscha Krettek <[hidden email]> wrote: Hi, |
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Vinay, We observed a similar problem before. We found that RocksDB keeps a lot of index and filter blocks in memory. With the growth in state size (in our cases, most states are only cleared in windowed streams), these blocks will occupy much more memory. We now let RocksDB put these blocks into block cache (via setCacheIndexAndFilterBlocks), and limit the memory usage of RocksDB with block cache size. Performance may be degraded, but TMs can avoid being killed by YARN for overused memory. This may not be the same cause of your problem, but it may be helpful. Regards, Xiaogang 2017-06-28 23:26 GMT+08:00 Vinay Patil <[hidden email]>:
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Xiaogang, Yes I have set that, I got the same issue. I don't see the graph coming down. Also I checked the HDFS usage , only 3GB is being used, that means nothing is getting flushed to disk. I think the parameters are not getting set properly. I am using FRocksDB , is it causing this error ? Regards, Vinay Patil On Thu, Jun 29, 2017 at 7:30 AM, SHI Xiaogang <[hidden email]> wrote:
|
|
|
Hi, Vinay,
I observed a similar problem in flink 1.3.0 with rocksdb. I wonder how to use FRocksDB as you mentioned above. Thanks. |
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Gerry, Even I have faced this issue on 1.3.0 even by using FRocksDB and enabling incremental checkpointing. You can add FRocksDB dependency as shown here : https://github.com/apache/flink/pull/3704 We will have to set some RocksDB parameters to get this working. @Stefan or @Stephan : can you please help in resolving this issue Regards, Vinay Patil On Thu, Jun 29, 2017 at 6:01 PM, gerryzhou [via Apache Flink User Mailing List archive.] <[hidden email]> wrote: Hi, Vinay, |
Re: Checkpointing with RocksDB as statebackend
|
|
In reply to this post by gerryzhou
Hi Vinay,
When you say HDFS usage is low and nothing is getting flushed to disk, what do you mean by that? RocksDB will not flush to disk, only checkpoints will get written to HDFS and then you can check in HDFS how big the checkpointed state actually is. Have you tried running with this newer version of Flink without checkpointing? I.e. do you also see the growing heap memory there? Best, Aljoscha > On 29. Jun 2017, at 14:31, gerryzhou <[hidden email]> wrote: > > Hi, Vinay, > I observed a similar problem in flink 1.3.0 with rocksdb. I wonder how > to use FRocksDB as you mentioned above. Thanks. > > > > -- > View this message in context: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Re-Checkpointing-with-RocksDB-as-statebackend-tp11752p14063.html > Sent from the Apache Flink User Mailing List archive. mailing list archive at Nabble.com. |
Re: Checkpointing with RocksDB as statebackend
|
|
In reply to this post by Vinay Patil
Just a quick remark: Flink 1.3.0 and 1.2.1 always use FRocksDB, you shouldn’t manually specify that.
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Aljoscha, Yes I have tried with 1.2.1 and 1.3.0 , facing the same issue. The issue is not of Heap memory , it is of the Off-Heap memory that is getting used ( please refer to the earlier snapshot I have attached in which the graph keeps on growing ). Regards, Vinay Patil On Thu, Jun 29, 2017 at 8:55 PM, Aljoscha Krettek <[hidden email]> wrote:
|
Re: Checkpointing with RocksDB as statebackend
|
|
Yup, I got that. I’m just wondering whether this occurs only with enabled checkpointing or also when checkpointing is disabled.
|
Re: Checkpointing with RocksDB as statebackend
|
|
The state size is not that huge. On the Flink UI when it showed the data sent as 4GB , the physical memory usage was close to 90GB .. I will re-run by setting the Flushing options of RocksDB because I am facing this issue on 1.2.0 as well. Regards, Vinay Patil On Thu, Jun 29, 2017 at 9:03 PM, Aljoscha Krettek <[hidden email]> wrote:
|
Re: Checkpointing with RocksDB as statebackend
|
|
Hi Guys, I am able to overcome the physical memory consumption issue by setting the following options of RocksDB: DBOptions: along with the FLASH_SSD_OPTIONS added the following: maxBackgroundCompactions(4) ColumnFamilyOptions: max_buffer_size : 512 MB block_cache_size : 128 MB max_write_buffer_number : 5 minimum_buffer_number_to_merge : 2 cacheIndexAndFilterBlocks : true optimizeFilterForHits: true I am going to modify these options to get the desired performance. I have set the DbLogDir("/var/tmp/") and StatsSumpPeriodicSec but I only got the configurations set in the log file present in var/tmp/ Where will I get the RocksDB statistics if I set createStatistics ? Let me know if any other configurations will help to get better performance. Now the physical memory is slowly getting increased and I can see the drop in the graph ( this means flushing is taking place at regular intervals ) Regards, Vinay Patil On Thu, Jun 29, 2017 at 9:13 PM, Vinay Patil <[hidden email]> wrote:
|
Re: Checkpointing with RocksDB as statebackend
|
|
That’s great to hear!
Maybe it would make sense to add these defaults to Flink, if they don’t otherwise degrade performance. Best, Aljoscha
|
| Free forum by Nabble | Edit this page |