Question a possible use can for Iterative Streams.

Question a possible use can for Iterative Streams.

|
Hi everybody, I am brainstorming how it might be possible to perform database enrichment with the DataStream API, use keyed state for caching, and also utilize Async IO. Since AsyncIO does not support keyed state, then is it possible to use an Iterative Stream that uses keyed state for caching in the main body, and uses feedback to fetch cache misses with AsyncIO? I hope this diagram conveys my idea. 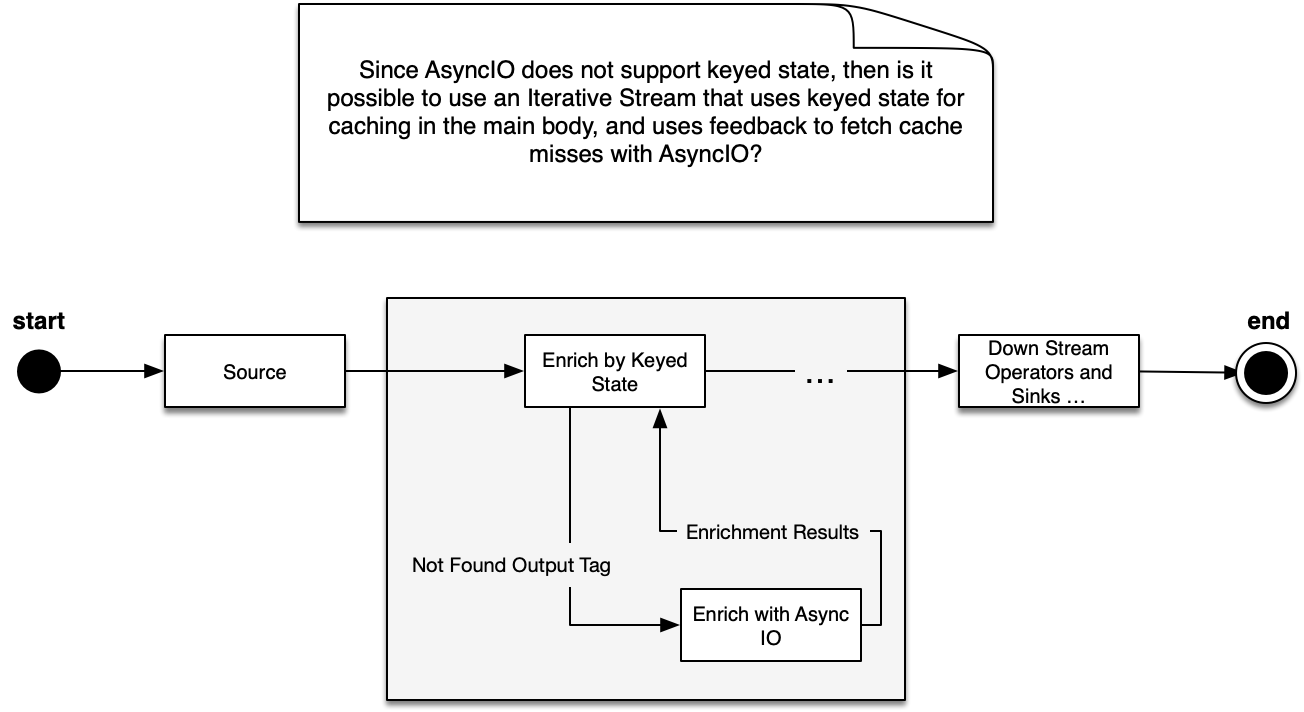 I am thinking of leveraging an Iterative Stream in this manner, but I am not quite sure how Iterative Steams work since the example is not clear to me. |
Re: Question a possible use can for Iterative Streams.
|
|
Hi Marco,
In the ideal setup, enrichment data existing in external databases is bootstrapped into the streaming job via Flink's State Processor API, and any follow-up changes to the enrichment data is streamed into the job as a second union input on the enrichment operator. For this solution to scale, lookups to the enrichment data needs to be by the same key as the input data, i.e. the enrichment data is co-partitioned with the input data stream. I assume you've already thought about whether or not this would work for your case, as it's a common setup for streaming enrichment. Otherwise, I believe your brainstorming is heading in the right direction, in the case that remote database lookups + local caching in state is a must. I'm personally not familiar with the iterative streams in Flink, but in general I think it is currently discouraged to use it. On the other hand, I think using Stateful Function's [1] programing abstraction might work here, as it allows arbitrary messaging between functions and cyclic dataflows. There's also an SDK that allows you to embed StateFun functions within a Flink DataStream job [2]. Very briefly, the way you would model this database cache hit / remote lookup is by implementing a function, e.g. called DatabaseCache. The function would expect message types of Lookup(lookupKey), and replies with a response of Result(lookupKey, value). The abstraction allows you, for on incoming message, to register state (similar to vanilla Flink), as well as register async operations with which you'll use to perform remote database lookups in case of cache / state miss. It also provides means for "timers" in the form of delayed messages being sent to itself, if you need some mechanism for cache invalidation. Hope this provides some direction for you to think about! Cheers, Gordon [1] https://ci.apache.org/projects/flink/flink-statefun-docs-release-2.2/ [2] https://ci.apache.org/projects/flink/flink-statefun-docs-release-2.2/sdk/flink-datastream.html -- Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
Re: Question regarding a possible use case for Iterative Streams.
|
|
Hi Gorden,
Thank you very much for the detailed response. I considered using the state-state processor API, however, our enrichment requirements make the state-processor API a bit inconvenient. 1. if an element from the stream matches a record in the database then it can remain in the cache a very long time (potentially forever). 2. if an element from the stream does not match a record in the database then that miss cannot be cached a very long time because that record might be added to the database and we have to pick it up in a timely manner. 3. Our stream has many elements that lack enrichment information in the database. Thus, for that reason, the state processor api only really helps with records that already exist in the database, even though the stream has many records that do not exist. That is why I was brainstorming over my idea of using an iterative stream that uses caching in the body, but AsyncIO in a feedback loop. You mentioned "in general I think it is currently discouraged to us it (iterative streams)." May I ask what is your source for that statement? I see no mention of any discouragement in Flink's documentation. I will look into how State Functions can help me in this scenario. I have not read up much on stateful functions. If I were to write a proof of concept, and my database queries were performed with JDBC, could I just write an embedded function that performs the JDBC call directly (I want to avoid changing our deployment topology for now) and package it with my Data Stream Job? Thank you. > On Feb 2, 2021, at 10:08 PM, Tzu-Li (Gordon) Tai <[hidden email]> wrote: > > Hi Marco, > > In the ideal setup, enrichment data existing in external databases is > bootstrapped into the streaming job via Flink's State Processor API, and any > follow-up changes to the enrichment data is streamed into the job as a > second union input on the enrichment operator. > For this solution to scale, lookups to the enrichment data needs to be by > the same key as the input data, i.e. the enrichment data is co-partitioned > with the input data stream. > > I assume you've already thought about whether or not this would work for > your case, as it's a common setup for streaming enrichment. > > Otherwise, I believe your brainstorming is heading in the right direction, > in the case that remote database lookups + local caching in state is a must. > I'm personally not familiar with the iterative streams in Flink, but in > general I think it is currently discouraged to use it. > > On the other hand, I think using Stateful Function's [1] programing > abstraction might work here, as it allows arbitrary messaging between > functions and cyclic dataflows. > There's also an SDK that allows you to embed StateFun functions within a > Flink DataStream job [2]. > > Very briefly, the way you would model this database cache hit / remote > lookup is by implementing a function, e.g. called DatabaseCache. > The function would expect message types of Lookup(lookupKey), and replies > with a response of Result(lookupKey, value). The abstraction allows you, for > on incoming message, to register state (similar to vanilla Flink), as well > as register async operations with which you'll use to perform remote > database lookups in case of cache / state miss. It also provides means for > "timers" in the form of delayed messages being sent to itself, if you need > some mechanism for cache invalidation. > > Hope this provides some direction for you to think about! > > Cheers, > Gordon > > [1] https://ci.apache.org/projects/flink/flink-statefun-docs-release-2.2/ > [2] > https://ci.apache.org/projects/flink/flink-statefun-docs-release-2.2/sdk/flink-datastream.html > > > > -- > Sent from: http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/ |
|
|
Answers inline: On Wed, Feb 3, 2021 at 3:55 PM Marco Villalobos <[hidden email]> wrote: Hi Gorden, This SO thread contains some answers, and links to some further answers: https://stackoverflow.com/questions/61710605/flink-iterations-in-data-stream-api-disadvantages
Yes, you can establish JDBC connections directly in Flink user functions.
|
«
Return to (DEPRECATED) Apache Flink User Mailing List archive.
|
1 view|%1 views
| Free forum by Nabble | Edit this page |